Архитектуры CNN
Мы рассмотрели базовые компоненты, из которых состоят современные свёрточные нейронные сети, а также техники их обучения.
На этом занятии рассмотрим, какие модели можно построить на основе этих компонентов.
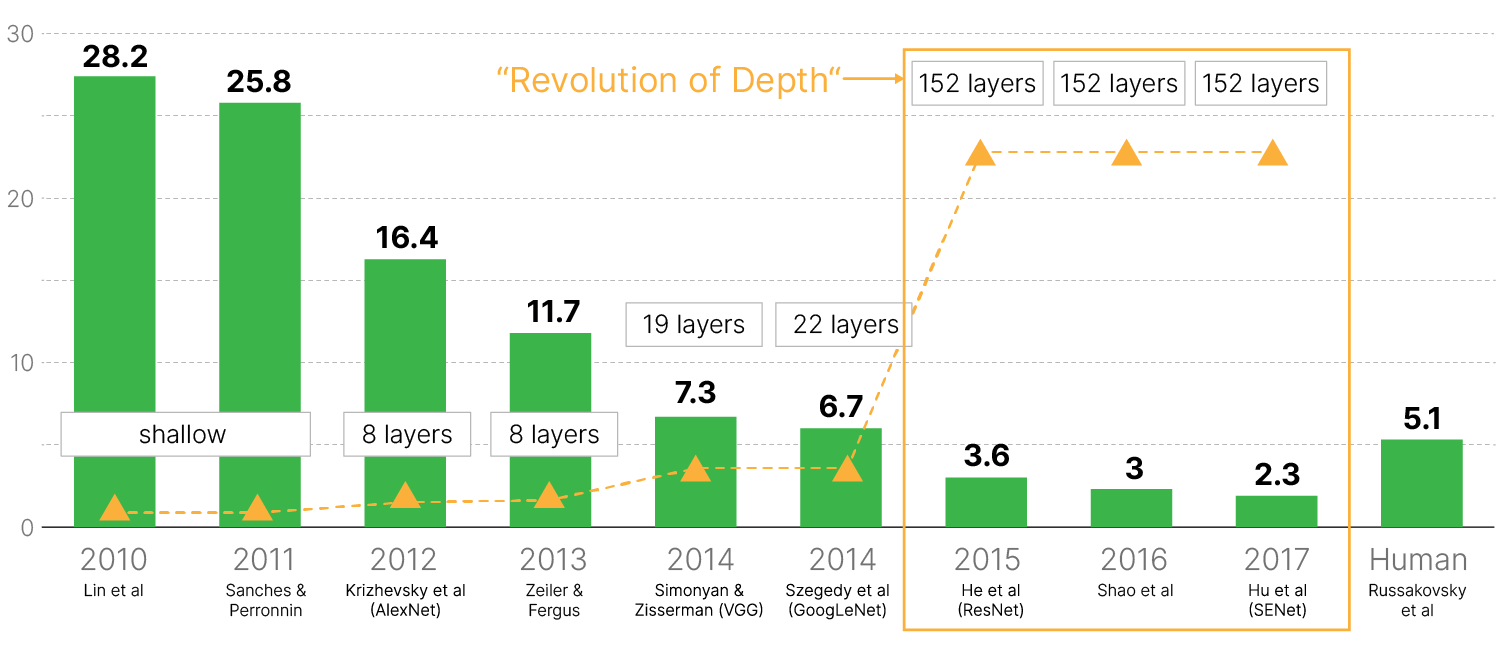
Large Scale Visual Recognition Challenge
ImageNet — одно из самых известных соревнований в области распознавания изображений и машинного зрения. Содержит более 14 миллионов вручную размеченных изображений, принадлежащих к 1000 классам.
Для загрузки с официального сайта 🛠️[doc] необходимо запрашивать доступ, но можно загрузить данные с Kaggle 🛠️[doc]. Однако архив занимает порядка 156Gb и не поместится на диск Colab. Поэтому воспользуемся другим репозиторием, который содержит 1000 изображений из оригинального датасета.
P.S. Для загрузки данных, которые стали недоступны на официальных сайтах, можно использовать Academic Torrents 🛠️[doc]. В частности для ImageNet 🛠️[doc].
import torch
import random
import numpy as np
# fix random_seed
torch.manual_seed(42)
random.seed(42)
np.random.seed(42)
# compute in cpu or gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Full list of labels
#'https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json'
!wget -q https://edunet.kea.su/repo/EduNet-web_dependencies/datasets/imagenet_class_index.json
# https://github.com/ajschumacher/imagen.git
!wget -q https://edunet.kea.su/repo/EduNet-web_dependencies/datasets/imagen.zip
!unzip -q imagen.zip
Загрузили категории:
import json
import pprint
import numpy as np
pp = pprint.PrettyPrinter(width=41, compact=True)
with open("imagenet_class_index.json") as f:
imagenet_labels = json.load(f)
classes = np.array(list(imagenet_labels.values()))[:, 1]
pp.pprint(
dict(list(imagenet_labels.items())[:10])
) # Use Pretty Print to display long dict
{'0': ['n01440764', 'tench'],
'1': ['n01443537', 'goldfish'],
'2': ['n01484850', 'great_white_shark'],
'3': ['n01491361', 'tiger_shark'],
'4': ['n01494475', 'hammerhead'],
'5': ['n01496331', 'electric_ray'],
'6': ['n01498041', 'stingray'],
'7': ['n01514668', 'cock'],
'8': ['n01514859', 'hen'],
'9': ['n01518878', 'ostrich']}
from glob import glob
from PIL import Image
from torch.utils.data import Dataset
class MicroImageNet(Dataset):
def __init__(self):
super().__init__()
# Load labels
self.num2id = {}
with open("imagenet_class_index.json") as f:
imagenet_labels = json.load(f)
w_net = {}
# Because not all world net image codes from imagen exists in imagenet_labels
# we need to filter this image
for key in imagenet_labels.keys():
wn_id = imagenet_labels[key][0]
w_net[wn_id] = {"num": int(key), "name": imagenet_labels[key][1]}
self.labels = []
self.paths = []
# Load data
images = glob("imagen/*.jpg")
images.sort()
for i, path in enumerate(images):
name = path.split("_")[2] # Class name
id = path.split("_")[0][7:] # WorldNet based ID
if w_net.get(id, None):
self.labels.append([w_net[id]["num"], w_net[id]["name"], id])
self.paths.append(path)
def __getitem__(self, idx):
im = Image.open(self.paths[idx])
class_num = self.labels[idx][0]
return im, class_num
def __len__(self):
return len(self.paths)
microImgNet = MicroImageNet()
Посмотрим на картинки:
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (15, 10)
def show(img, label_1, num, label_2=""):
ax = plt.subplot(2, 3, num + 1)
plt.imshow(img)
plt.title(label_1)
ax.set_xlabel(label_2)
plt.axis("off")
for i in range(6, 12):
img, label = microImgNet[i * 6]
name = microImgNet.labels[i * 6][1]
show(img, name, i - 6)

Создатели: Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton University of Toronto
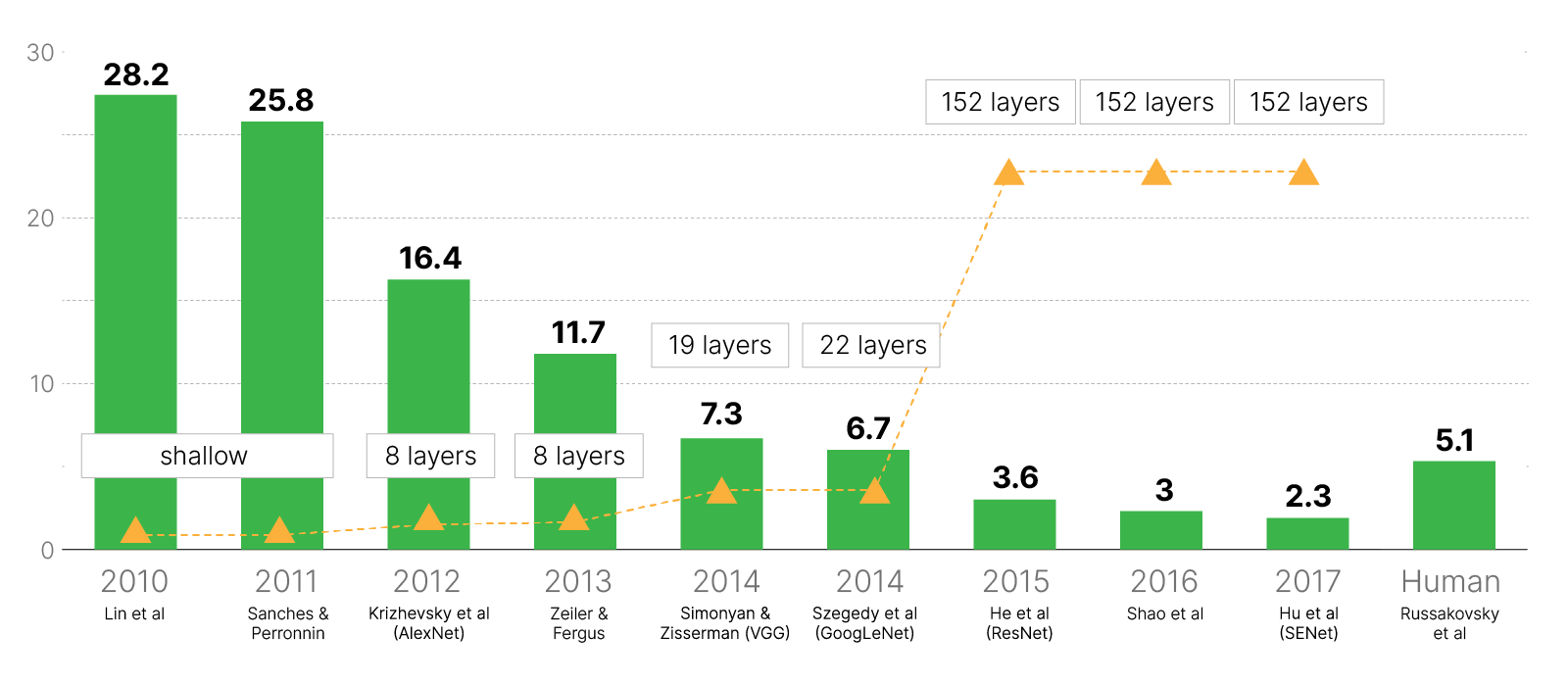
Современный бум нейросетевых технологий начался в 2012 году, когда AlexNet с большим отрывом от конкурентов победила в ImageNet.
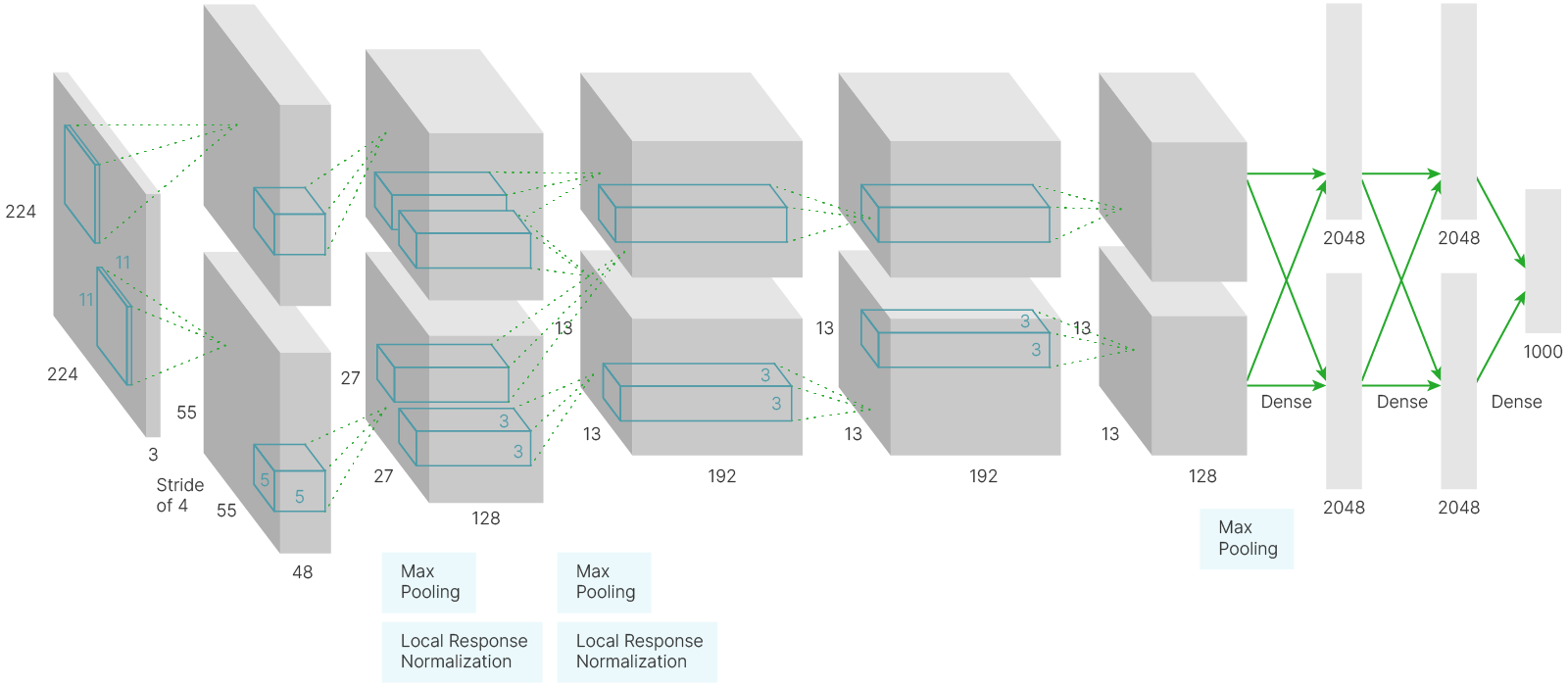
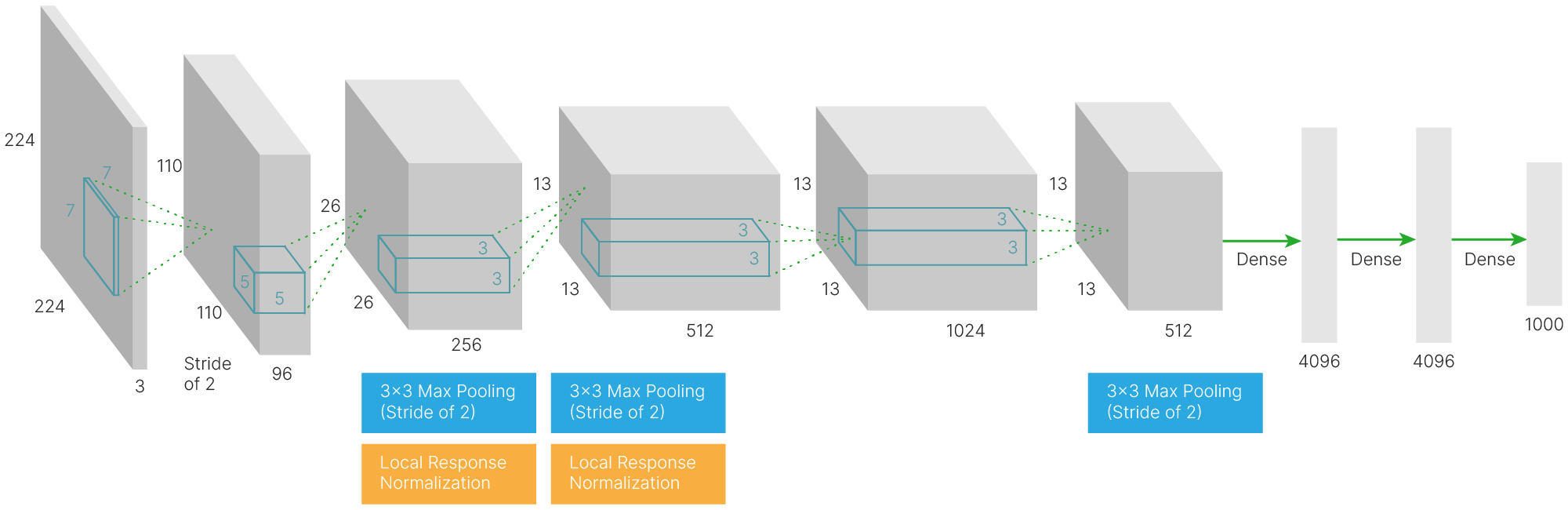
В AlexNet есть все компоненты, которые мы рассматривали ранее. Её архитектура состоит из пяти свёрточных слоёв, между которыми располагаются pooling-слои и слои нормализации, а завершают нейросеть три полносвязных слоя.
[blog] ✏️ Подробнее про AlexNet
Можно заметить, что нейросеть состоит из двух работающих параллельно нейросетей, которые обмениваются информацией после 2-го и 5-го сверточного слоя и в полносвязных слоях. Это было необходимо, т.к. для обучения использовались GPU GTX580 с 3 ГБ видеопамяти. Авторы архитектуры использовали две видеокарты, работающие параллельно. На вход нейронной сети подавалось трёхканальное изображение с пространственными размерами $224 \times 224$ пикселя, к которому применялось $96$ свёрток с ядром $11 \times 11 \times 3$ и сдвигом $4$. Веса, соответствующие первым $48$ свёрткам, хранились на первой видеокарте, а оставшиеся $48$ свёрток были связаны со второй видеокартой.
Пространственные размеры карты признаков резко сжимаются: $224\times224 \to 55\times55 \to 27\times27 \to 13\times13 \to 13\times13 \to 13\times13$.
При этом увеличивается количество сверток (фильтров) в каждом слое: $96 (48\times2) \to 256 (128\times2) \to 384 (192\times2) \to 256 (128\times2)$.
На выходе нейросети стоят два полносвязных слоя, формирующие ответ (в ImageNet 1000 классов).
AlexNet невозможно напрямую использовать для классификации CIFAR-10. Если так агрессивно уменьшать изображение размером $32\times32$ px, то в определенный момент в него просто не поместится следующий фильтр, который нужно применить. Можно сделать resize изображения с $32\times32$ до $224\times224$, но это не самый рациональный способ использования вычислительных ресурсов.
Структура некоторых (особенно старых) сетей, обученных под ImageNet, напрямую зависит от размера изображений. В более современных сетях есть слой Adaptive Average Pooling 🛠️[doc], позволяющий решить эту проблему, но о нем мы расскажем чуть позже.
Такая архитектура показала прорывную точность: 2 место имело ошибку 26.2% против 15.3% у AlexNet.

Нестандартные решения, принятые разработчиками AlexNet:
Сравним реализацию в PyTorch с оригинальной. В чем отличия?
from torchvision import models
alexnet = models.alexnet(weights="AlexNet_Weights.DEFAULT")
Downloading: "https://download.pytorch.org/models/alexnet-owt-7be5be79.pth" to /root/.cache/torch/hub/checkpoints/alexnet-owt-7be5be79.pth 100%|██████████| 233M/233M [00:02<00:00, 116MB/s]
from torchsummary import summary
print("AlexNet architecture")
print(summary(alexnet, (3, 224, 224), device="cpu"))
print(alexnet)
AlexNet architecture
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 55, 55] 23,296
ReLU-2 [-1, 64, 55, 55] 0
MaxPool2d-3 [-1, 64, 27, 27] 0
Conv2d-4 [-1, 192, 27, 27] 307,392
ReLU-5 [-1, 192, 27, 27] 0
MaxPool2d-6 [-1, 192, 13, 13] 0
Conv2d-7 [-1, 384, 13, 13] 663,936
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 [-1, 256, 13, 13] 884,992
ReLU-10 [-1, 256, 13, 13] 0
Conv2d-11 [-1, 256, 13, 13] 590,080
ReLU-12 [-1, 256, 13, 13] 0
MaxPool2d-13 [-1, 256, 6, 6] 0
AdaptiveAvgPool2d-14 [-1, 256, 6, 6] 0
Dropout-15 [-1, 9216] 0
Linear-16 [-1, 4096] 37,752,832
ReLU-17 [-1, 4096] 0
Dropout-18 [-1, 4096] 0
Linear-19 [-1, 4096] 16,781,312
ReLU-20 [-1, 4096] 0
Linear-21 [-1, 1000] 4,097,000
================================================================
Total params: 61,100,840
Trainable params: 61,100,840
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 8.38
Params size (MB): 233.08
Estimated Total Size (MB): 242.03
----------------------------------------------------------------
None
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
В PyTorch версии:
Количество слоев и размеры сверток те же.
Проверим, как работает:
import torch
import torchvision.transforms.functional as F
def img2tensor(img):
t = F.to_tensor(img)
t = F.normalize(t, (0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
return t
def catId2names(nums):
titles = []
for num in nums:
titles.append(imagenet_labels[str(num.item())][1])
titles.reverse()
return ", ".join(titles)
for i in range(6, 12):
img, label = microImgNet[i * 6]
tensor = img2tensor(img)
out = alexnet(tensor.unsqueeze(0)) # Add batch dimension
labels_num = torch.argsort(out[0]) # Ascending order
weights = out[0][-5:]
predicted = catId2names(labels_num[-5:]) # Top 5
titles = []
name = microImgNet.labels[i * 6][1]
show(img, name, i - 6, predicted)
На каждом изображении может быть один или несколько предметов, относящихся к одному из 1000 классов. Для метрики Тop5 алгоритм выдает метки 5 классов. Если предмет, относящийся к одному из этих классов, есть на изображении, то ответ засчитывается как верный. Для Top1, соответственно, принимается только метка одного класса.

Source: ImageNet
Тюнингованный AlexNet
Нейросеть ZFNet, созданная учеными из Йорского университета, в 2013 году выиграла соревнования, достигнув результата 11.7%. В ней AlexNet использовалась в качестве основы, но с изменёнными параметрами и слоями.
Отличия от AlexNet небольшие:
Количество слоев и общая структура сети, когда слои свёртки и пулинга чередуются друг с другом, а затем идут два полносвязных слоя, сохранились.
[arxiv] 🎓 Very Deep Convolutional Networks for Large-Scale Image Recognition (Simonyan et al., 2014)
Karen Simonyan and Andrew Zisserman (Visual Geometry Group — Oxford)
[doc] 🛠️ Краткое описание VGGNet
В 2014-ом году в Оксфорде была разработана модель VGGNet.
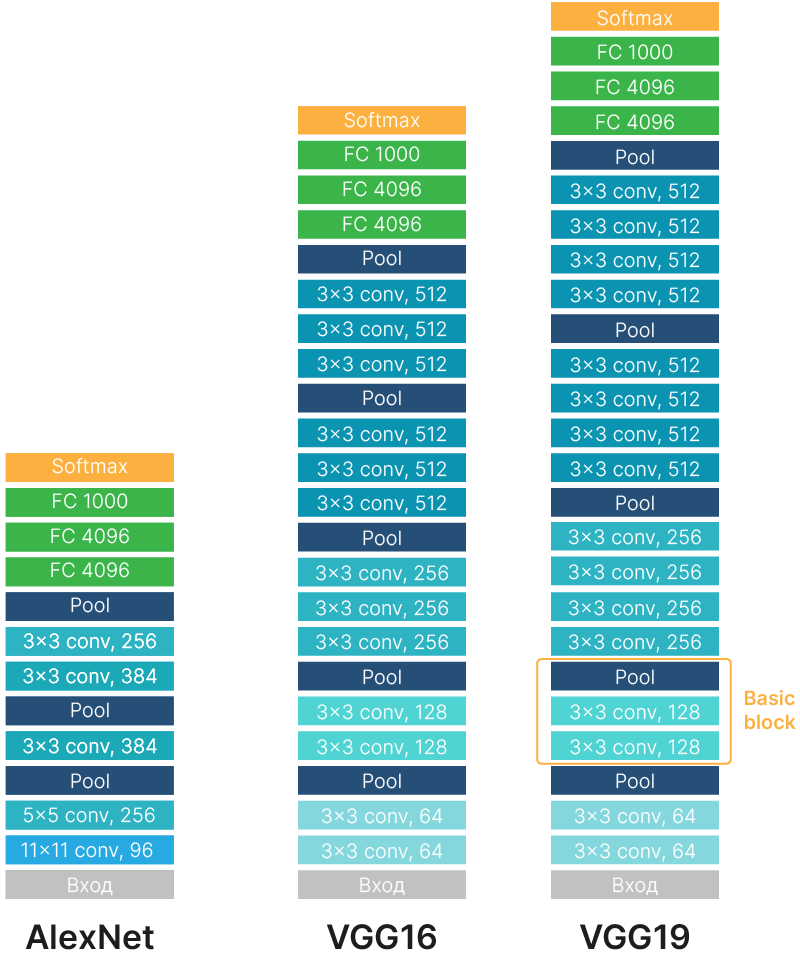
В архитектуре VGGNet появляется идея повторения стандартных блоков и увеличения глубины нейросети повторением таких блоков (stacking). На момент создания данной архитектуры идея увеличения глубины нейросети для получения лучших результатов не была очевидна. Стандартный блок VGGNet состоит из нескольких слоев свертки (от 2 до 4) и max-pooling слоя.
Существует несколько вариантов VGGNet архитектуры. Самые известные: VGG11, VGG16 и VGG19. Цифра ставится по количеству слоев с обучаемыми весами: сверточных и полносвязных слоев.
На изображении выше показаны сети AlexNet и две версии VGG16 и VGG19 с 16 и 19 обучаемыми слоями соответственно. На соревнованиях победила более глубокая VGG19, показавшая процент ошибок при классификации top-5 7.3% (у AlexNet 15.4%).
Интересные факты о VGGNet:
Особенности архитектуры VGGNet:
Появление "стандартных" блоков внутри модели — важное нововведение. Идея базового блока внутри сети будет достаточно широко использоваться дальше.
Разберем на коде:
from torchvision import models
vgg = models.vgg16(
weights=None
) # Change on True if you want to use VGG to predict something
print(vgg)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Чтобы понять смысл использования сверток $3\times3$, необходимо познакомиться с понятием рецептивного поля и научиться оценивать количество необходимых вычислительных ресурсов.
Какие ресурсы нужны для работы нейронной сети?
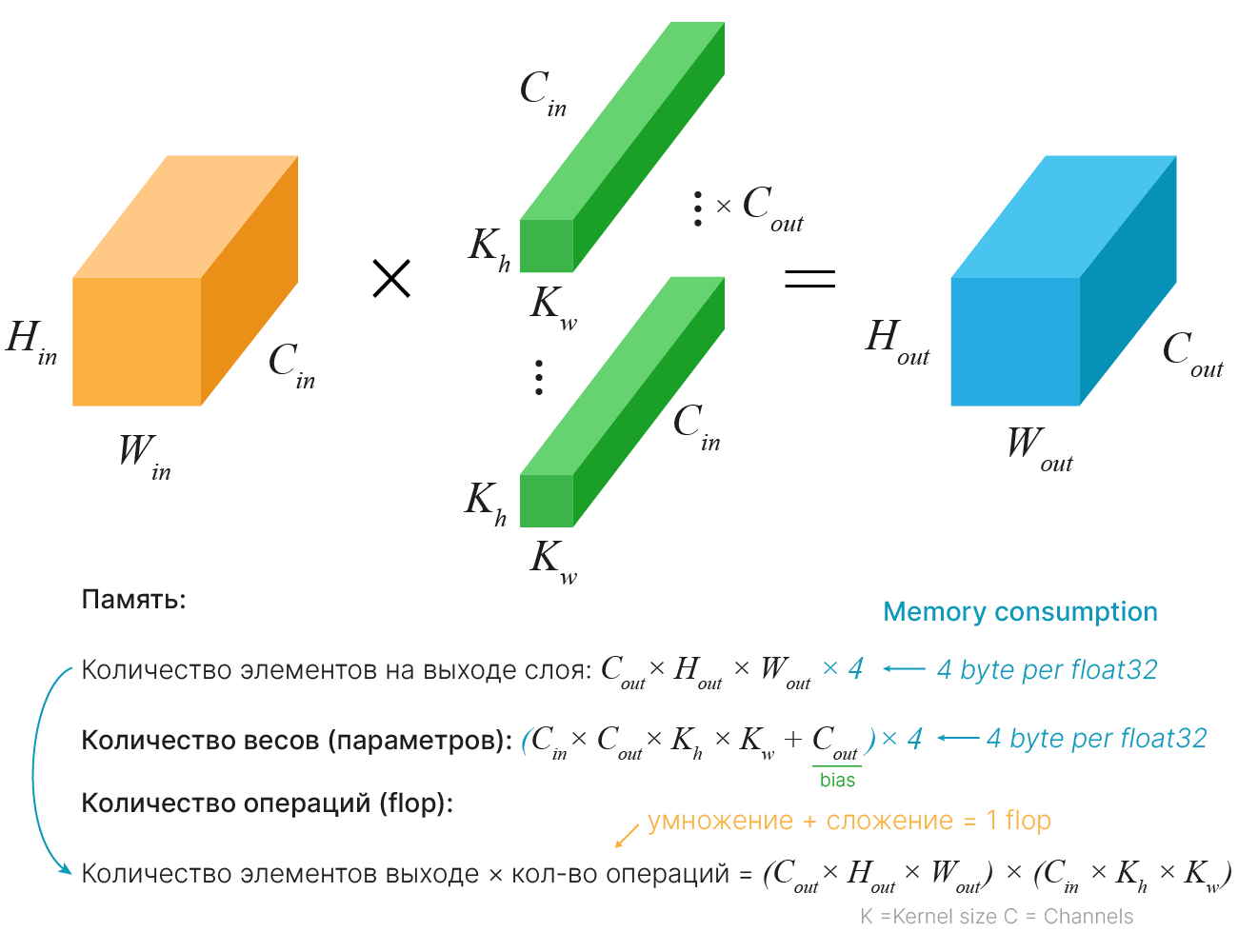
Для случая, когда количество каналов не меняется, фильтры и изображения квадратные, stride = 1 и padding = "same":
$\color{orange}{\text{Оранжевый тензор}}$ — карта признаков, поступившая на вход сверточного слоя. Параметры $H_{in}$, $W_{in}$, $C_{in}$ — длина, ширина и глубина (число каналов изображения или фильтров в предыдущем сверточном слое) входного тензора. Данный тензор не учитывается в затрачиваемых ресурсах, т.к. информация сохранена в предыдущем слое.
Память для хранения промежуточных представлений определяется количеством элементов на выходе слоя ($\color{blue}{\text{синий тензор}}$). Они хранятся для вычисления следующих слоев и градиентов. Необходимая память рассчитывается как:
$$\large H_{out}⋅W_{out}⋅C_{out}⋅n_{byte},$$где $H_{out}, W_{out}, C_{out}$ — длина, ширина и глубина (число фильтров в свертке) выходной карты признаков, а $n_{byte}$ — количество байт для хранения одного элемента ($4$ для float32).
Память для обучаемых параметров определяется весами и смещением (bias) фильтров свертки ($\color{green}{\text{зеленые тензоры}}$). Необходимая память рассчитывается как:
$$\large (K_h⋅K_w⋅C_{in}⋅C_{out} + С_{out})⋅n_{byte},$$где $K_h, K_w, C_{in}$ — длина, ширина и глубина одного фильтра, $C_{out}$ — число фильтров в свертке.
Для оценки необходимых вычислительных ресурсов посчитаем количество операций сложения и умножения при прямом проходе. Каждое число выходного тензора является результатом применения фильтра свертки к некоторому рецептивному полю входного тензора. Количество операций можно оценить как произведение количества элементов на выходе слоя на размер одного фильтра:
$$\large (H_{out}⋅W_{out}⋅C_{out})⋅(K_h⋅K_w⋅C_{in}).$$Оценка памяти для хранения параметров слоя:
import torch.nn as nn
conv_sizes = [11, 7, 5, 3]
for conv_size in conv_sizes:
conv_layer = nn.Conv2d(3, 64, conv_size, stride=1, padding=1)
print("Convolution size: %ix%i" % (conv_size, conv_size))
for tag, p in conv_layer.named_parameters():
print("Memory reqired for %s: %.2f kb" % (tag, (np.prod(p.shape) * 4) / 1024))
Convolution size: 11x11 Memory reqired for weight: 90.75 kb Memory reqired for bias: 0.25 kb Convolution size: 7x7 Memory reqired for weight: 36.75 kb Memory reqired for bias: 0.25 kb Convolution size: 5x5 Memory reqired for weight: 18.75 kb Memory reqired for bias: 0.25 kb Convolution size: 3x3 Memory reqired for weight: 6.75 kb Memory reqired for bias: 0.25 kb
Оценка количества вычислительных операций (для одной свертки):
$11×11: (224 * 224 * 64) * (3 * 11 * 11) = 9 633 792 * 11 * 11 = 9 633 792 * 121 = 1 165 688 832$
$7×7: (224 * 224 * 64) * (3 * 7 * 7) = 9 633 792 * 7 * 7 = 9 633 792 * 49 = 472 055 808$
$121:49 \approx 2.5 ⟶ $ в $\approx 2.5$ раза меньше, чем $11×11$
$5×5: (224 * 224 * 64) * (3 * 5 * 5) = 9 633 792 * 5 * 5 = 9 633 792 * 25 = 240 844 800$
$49:25 \approx 2 ⟶ $ в $\approx 2$ раза меньше, чем $7×7$
$3×3: (224 * 224 * 64) * (3 * 3 * 3) = 9 633 792 * 3 * 3 = 9 633 792 * 9 = 86 704 128$
$25:9 \approx 2.7$ ⟶ в $\approx 2.7$ раза меньше, чем $5×5$
Уменьшение размера ядра свертки приводит к существенному уменьшению количества вычислительных операций
Рецептивное поле — участок входной карты признаков (входного тензора), который при прохождении одного или нескольких слоев нейронной сети формирует один признак на выходе (одно число выходного тензора). Рецептивное поле можно назвать “полем зрения”.
Интуитивно кажется, что чем больше “поле зрение”, тем лучше обобщающая способность свертки. Авторы VGG решили отказаться от свертки 5×5 и заменить ее двумя свертками 3×3.
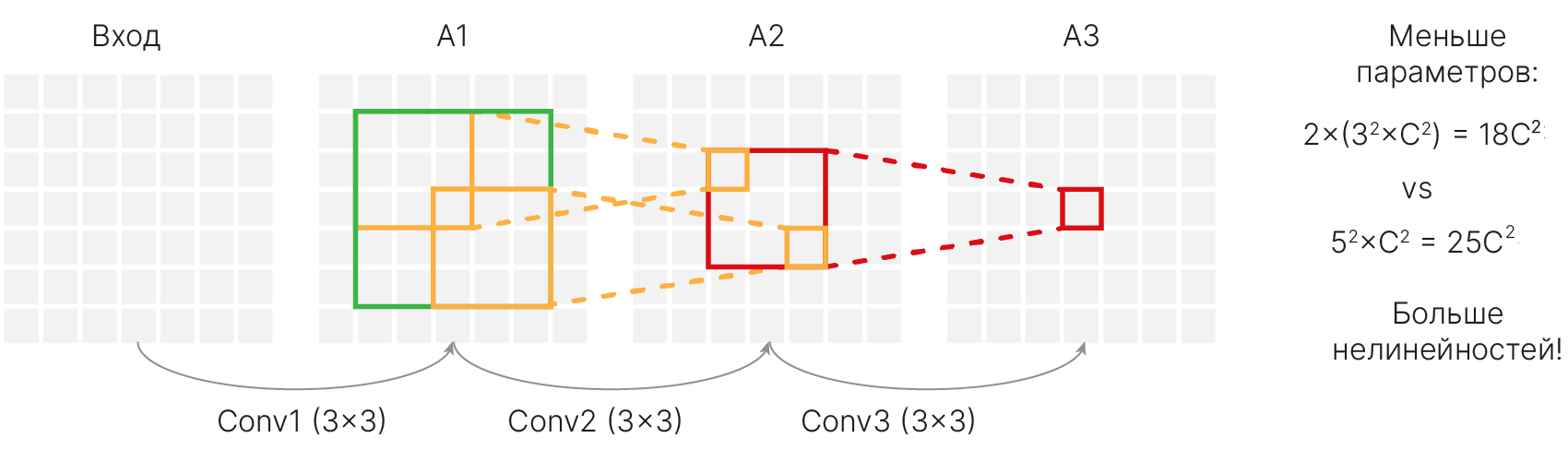
Рассмотрим рецептивное поле свертки 5×5 ($\color{green}{\text{зеленый квадрат}}$ на A1). Применение свертки 5×5 к этому квадрату даст 1 признак на выходе ($\color{red}{\text{красный квадрат}}$ на A3). Применение к этому же рецептивному полю свертки 3×3 ($\color{orange}{\text{оранжевые квадраты}}$ на A1) даст на 3×3 признака ($\color{red}{\text{красный квадрат}}$ на A2), применение второй свертки 3×3 позволит получить 1 признак на выходе ($\color{red}{\text{красный квадрат}}$ A3).
Итого: одна свертка 5×5 имеет то же рецептивное поле, что две свертки 3×3.
При этом применение двух сверток 3×3 дает ряд преимуществ:
2 маленьких фильтра работают как один большой или даже лучше!
Аналогично 3 свертки 3×3 могут заменить одну свертку 7×7.


Благодаря такой экономии получилось сделать большую по тем временам сеть (16 слоев). Тем не менее, несмотря на применённые способы уменьшения вычислительной сложности и снижение числа параметров, сеть все равно получилась огромной (16-слойная версия сети VGG расходует в 25 раз больше дорогой памяти GPU, нежели AlexNet).
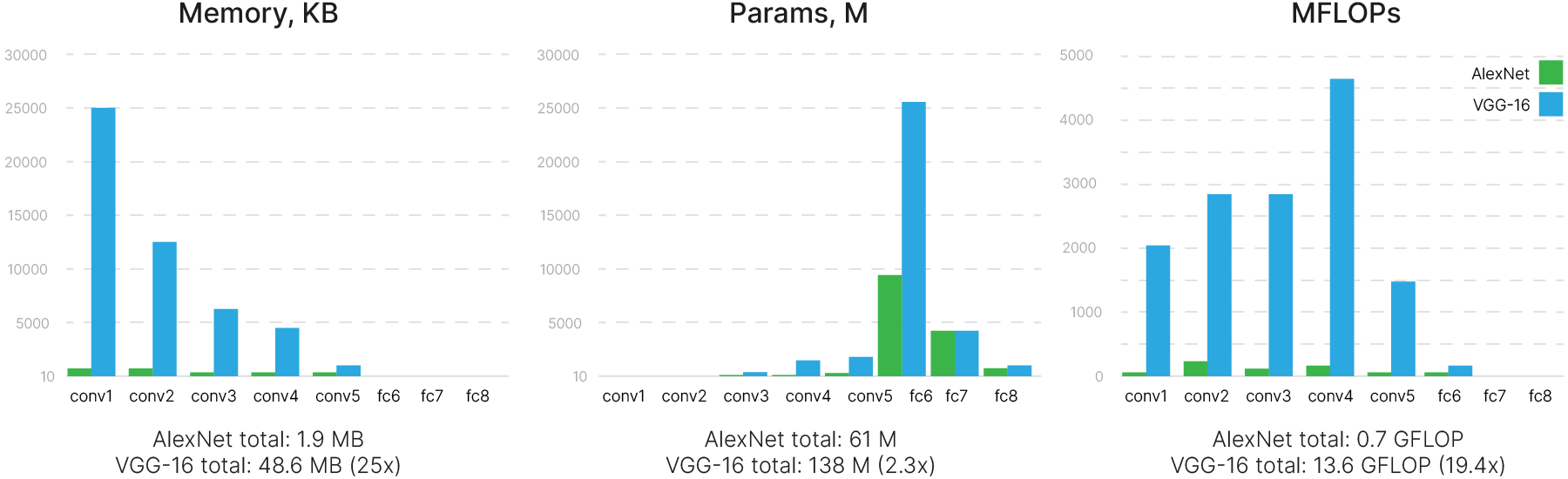
VGG-16 получилась существенно больше по сравнению с и так довольно объемной AlexNet, и тем более по сравнению с современными моделями.
В значительной степени с этим связано дальнейшее направление развития моделей. В следующем году ImageNet выиграла сеть под названием Inception.
!nvidia-smi
Fri Jan 26 12:20:36 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 60C P8 10W / 70W | 3MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
Чтобы контролировать расход памяти в процессе обучения, установим библиотеку для мониторинга ресурсов GPU:
!pip install -q GPUtil
Preparing metadata (setup.py) ... done Building wheel for GPUtil (setup.py) ... done
import os
import psutil
import GPUtil as GPU
def gpu_usage():
GPUs = GPU.getGPUs()
# XXX: only one GPU on Colab and isn’t guaranteed
if len(GPUs) == 0:
return False
gpu = GPUs[0]
process = psutil.Process(os.getpid())
print(
f"GPU RAM Free: {gpu.memoryFree:.0f}MB \
| Used: {gpu.memoryUsed:.0f}MB \
| Util {gpu.memoryUtil*100:3.0f}% \
| Total {gpu.memoryTotal:.0f}MB"
)
Посмотрим, сколько памяти потребуется VGG19 и какого размера batch можно использовать.
import torch
import torchvision
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
vgg19 = torchvision.models.vgg19(weights=None, progress=True)
vgg19.requires_grad = True
vgg19.to(device)
gpu_usage() # Common GPU info
vgg19.train()
for batch_size in [1, 8, 16, 32, 64]:
input_random = torch.rand(batch_size, 3, 224, 224, device=device)
out = vgg19(input_random)
print("Batch size", batch_size)
gpu_usage()
GPU RAM Free: 14425MB | Used: 677MB | Util 4% | Total 15360MB Batch size 1 GPU RAM Free: 14289MB | Used: 813MB | Util 5% | Total 15360MB Batch size 8 GPU RAM Free: 13475MB | Used: 1627MB | Util 11% | Total 15360MB Batch size 16 GPU RAM Free: 12395MB | Used: 2707MB | Util 18% | Total 15360MB Batch size 32 GPU RAM Free: 9843MB | Used: 5259MB | Util 34% | Total 15360MB Batch size 64 GPU RAM Free: 5529MB | Used: 9573MB | Util 62% | Total 15360MB
Очистка памяти:
gpu_usage()
GPU RAM Free: 5529MB | Used: 9573MB | Util 62% | Total 15360MB
input_random = None # del input
out = None # del out
gpu_usage()
GPU RAM Free: 5529MB | Used: 9573MB | Util 62% | Total 15360MB
torch.cuda.empty_cache()
gpu_usage()
GPU RAM Free: 8267MB | Used: 6835MB | Util 44% | Total 15360MB
vgg19 = None
gpu_usage()
GPU RAM Free: 8267MB | Used: 6835MB | Util 44% | Total 15360MB
torch.cuda.empty_cache()
gpu_usage()
GPU RAM Free: 14369MB | Used: 733MB | Util 5% | Total 15360MB
[arxiv] 🎓 Going Deeper with Convolutions (Szegedy et al., 2014)
GoogLeNet (на самом деле архитектура называется Inception, а GoogLeNet — это имя команды в соревновании ILSVRC14, названной так в честь нейронной сети Яна Лекуна LeNet 5, но до сих пор первую версию сети Inception называют GoogLeNet) — ещё более глубокая архитектура с 22 слоями.
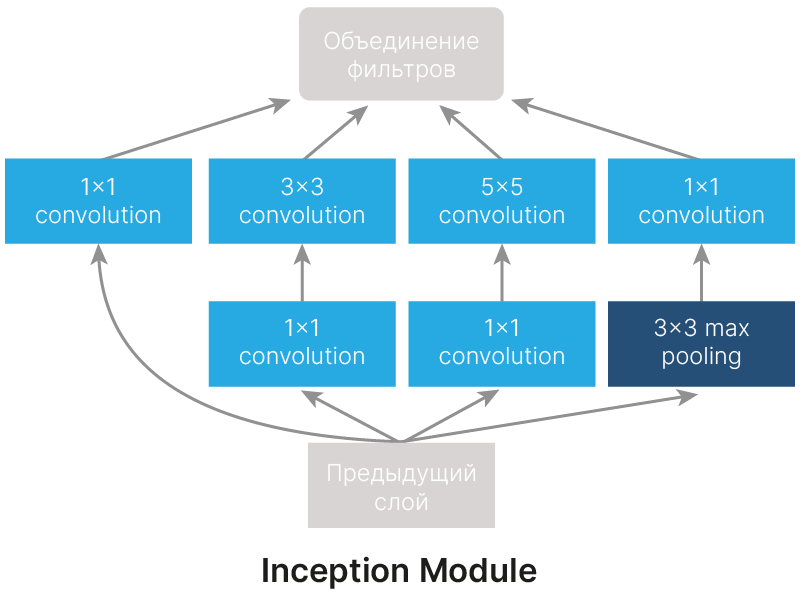
В отличие от предыдущих нейросетей, GoogLeNet разработана в коммерческой компании с целью практического применения, поэтому основной упор был сделан на эффективность.
Она содержит менее 7 миллионов параметров — в 9 раз меньше, чем у AlexNet, и в 20 раз меньше, чем у VGG19. При этом сеть оказалась немного более точной, чем VGG19: ошибка снизилась с 7.3% до 6.7%.
Рассмотрим, за счёт чего удалось достичь такого огромного выигрыша в ресурсах, так как многие идеи, которые впервые были использованы для GoogLeNet, активно применяются до сих пор.
Составной блок GoogLeNet называется Inception module. Архитектура GoogLeNet состоит из множества таких блоков, следующих друг за другом.
Идея Inception module состоит в том, чтобы производить параллельные вычисления сверток с различным размером рецептивного поля и Max Pooling, конкатенируя (объединяя, а не складывая) полученные результаты. Это позволяет выделять признаки разного размера и сложности.
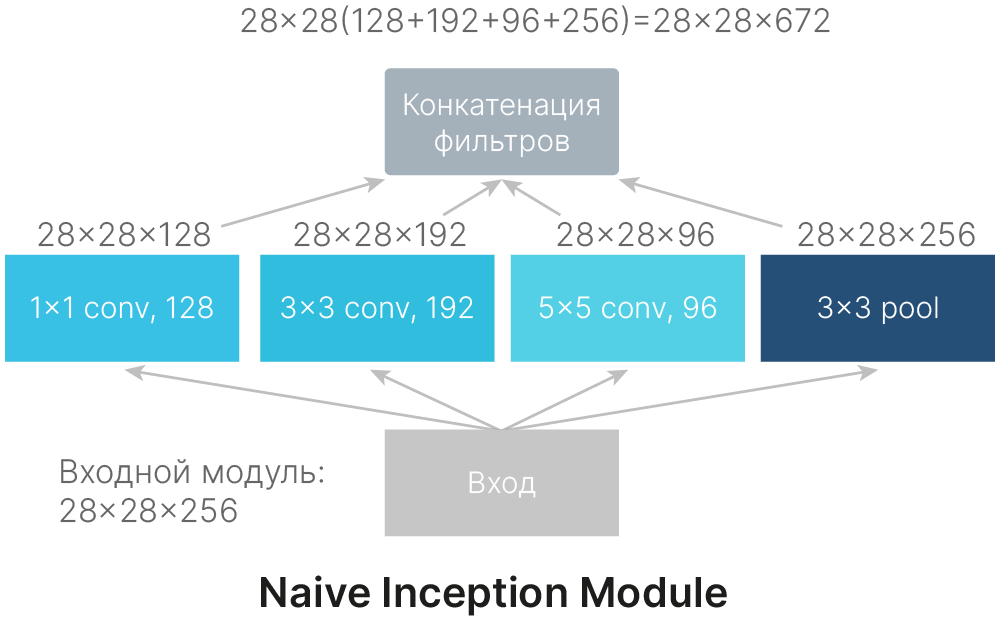
На рисунке выше представлена наивная реализация Inception module. Данная реализация имеет очень важный недостаток: увеличение глубины карты признаков. За счет конкатенации выходов сверток и Max Pooling из 256 каналов на входе мы получаем 672 канала на выходе. Количество каналов изображения увеличилось более чем в 2.6 раза. За 9 таких блоков глубина увеличится более чем в 5000 раз!
Такое решение плохо совместимо с экономией ресурсов.
Стоит также заметить, что слой Max Pooling в данной архитектуре имеет шаг 1 и не изменяет пространственные размеры карты признаков.

Как мы уже показали, при использовании наивной реализации Inception module количество фильтров возрастает от слоя к слою.
Чтобы этого избежать, введены так называемые «бутылочные горлышки» — слои с фильтром 1×1, уменьшающие глубину изображения. Благодаря им удалось достичь того, чтобы количество каналов на входе и на выходе либо не менялось, либо менялось только в моменты, когда это необходимо.
Интересно, что слой свертки 1×1 ставится после слоя Max Pooling. Это позволяет более эффективно преобразовывать признаки.
import torchvision
# https://pytorch.org/vision/stable/_modules/torchvision/models/googlenet.html#googlenet
googlenet = torchvision.models.googlenet(init_weights=True)
print(googlenet)
GoogLeNet(
(conv1): BasicConv2d(
(conv): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(maxpool1): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(conv2): BasicConv2d(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(conv3): BasicConv2d(
(conv): Conv2d(64, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(maxpool2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(inception3a): Inception(
(branch1): BasicConv2d(
(conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(96, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(192, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(16, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=True)
(1): BasicConv2d(
(conv): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inception3b): Inception(
(branch1): BasicConv2d(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(128, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(32, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=True)
(1): BasicConv2d(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(maxpool3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(inception4a): Inception(
(branch1): BasicConv2d(
(conv): Conv2d(480, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(480, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(96, 208, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(208, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(480, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(16, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(16, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=True)
(1): BasicConv2d(
(conv): Conv2d(480, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inception4b): Inception(
(branch1): BasicConv2d(
(conv): Conv2d(512, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(112, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(112, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(224, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(24, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(24, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=True)
(1): BasicConv2d(
(conv): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inception4c): Inception(
(branch1): BasicConv2d(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(24, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(24, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=True)
(1): BasicConv2d(
(conv): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inception4d): Inception(
(branch1): BasicConv2d(
(conv): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(112, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(512, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(144, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(144, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(288, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(512, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=True)
(1): BasicConv2d(
(conv): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inception4e): Inception(
(branch1): BasicConv2d(
(conv): Conv2d(528, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(528, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(528, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=True)
(1): BasicConv2d(
(conv): Conv2d(528, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(maxpool4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(inception5a): Inception(
(branch1): BasicConv2d(
(conv): Conv2d(832, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(832, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(832, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=True)
(1): BasicConv2d(
(conv): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(inception5b): Inception(
(branch1): BasicConv2d(
(conv): Conv2d(832, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(832, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(832, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(48, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=True)
(1): BasicConv2d(
(conv): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(aux1): InceptionAux(
(conv): BasicConv2d(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(fc1): Linear(in_features=2048, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=1000, bias=True)
(dropout): Dropout(p=0.7, inplace=False)
)
(aux2): InceptionAux(
(conv): BasicConv2d(
(conv): Conv2d(528, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(fc1): Linear(in_features=2048, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=1000, bias=True)
(dropout): Dropout(p=0.7, inplace=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(dropout): Dropout(p=0.2, inplace=False)
(fc): Linear(in_features=1024, out_features=1000, bias=True)
)
Свёртку 1×1 можно сравнить с линейным слоем полносвязной нейронной сети. Мы берем вектор из карты признаков (столбик 1×1×64 на картинке) и домножаем на матрицу весов (одну для всех векторов, в данном случае матрица будет 64×32, т.к. она составлена из 32 фильтров с размерами 1×1×64), чтобы получить вектор на выходе (столбик 1×1×32 на картинке).
Это одновременно формирует более сложные признаки, собирая информацию с различных сверток и Max Pooling, и позволяет сократить их количество.
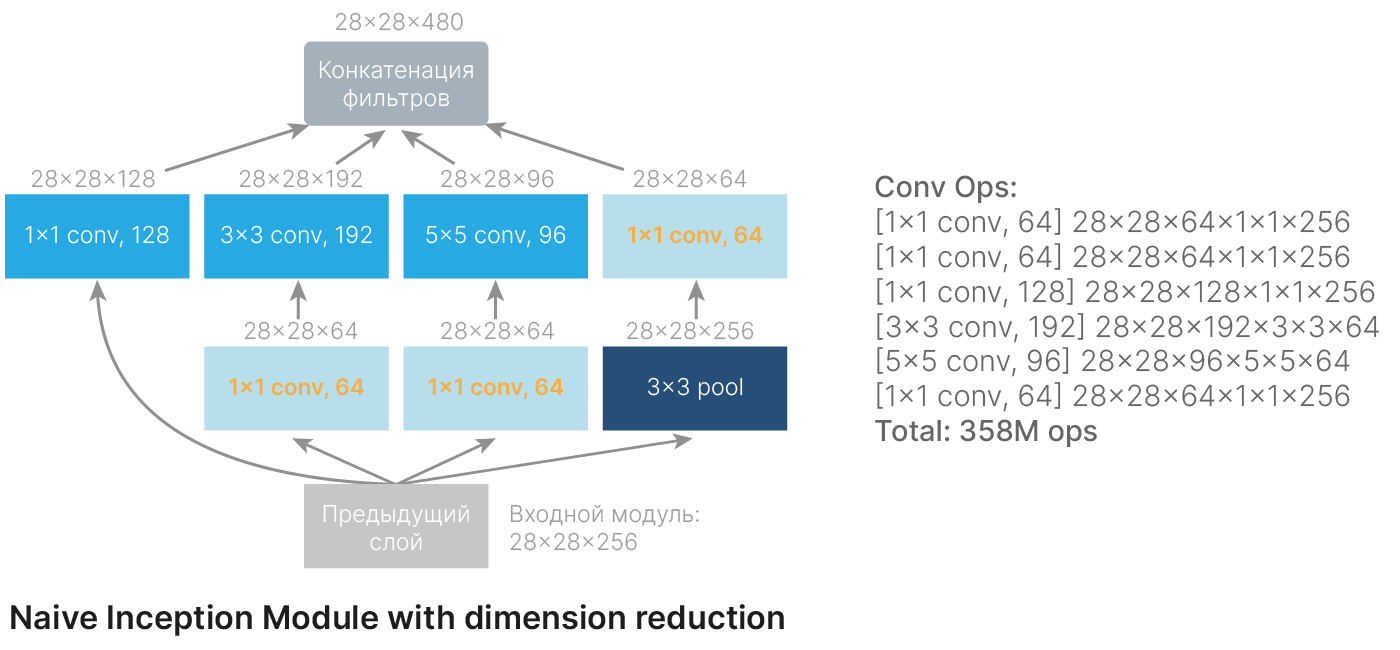
Количество параметров уменьшается в два с лишним раза по сравнению с наивной реализацией. Сеть получается значительно экономичнее.
Использование таких модулей и отсутствие полносвязных слоёв делают GoogLeNet очень эффективной и достаточно точной сетью. Но это далеко не все нововведения, которые появились в этой модели.
В составе GoogLeNet есть небольшая подсеть — Stem Network. Она состоит из трёх свёрточных слоёв (первый с большим фильтом) с двумя pooling-слоями и располагается в самом начале архитектуры. Цель этой подсети — быстро и сильно уменьшить пространственные размеры (сжать изображение перед параллельной обработкой), чтобы минимизировать количество элементов в слоях.

Отдельного внимания заслуживает завершающая часть сети. В AlexNet и VGGNet мы привыкли видеть в конце сети вытягивание карты признаков в вектор и два полносвязных слоя. В GoogLeNet один из полносвязных слоев заменен на Global Average Pooling.
Этот слой просто усредняет все значения в канале. На выходе получаем вектор признаков количество элементов в котором равно количеству каналов.
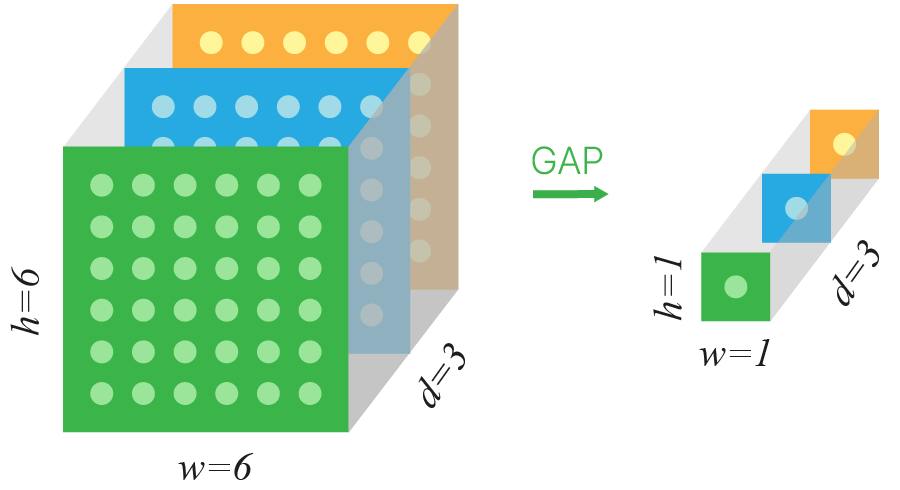
Плюсы GAP:
В PyTorch можно реализовать GAP при помощи класса nn.AdaptiveAvgPool2d 🛠️[doc]. При создании экземпляра класса указываем, какую пространственную размерность мы хотим получить на выходе. При output_size = 1получим результат как на иллюстрации.
gap = torch.nn.AdaptiveAvgPool2d(1)
dummy_input = torch.randn(1, 3, 6, 6)
out = gap(dummy_input)
print("Raw out shape", out.shape)
out = nn.Flatten()(out)
print("Flatten out shape", out.shape)
Raw out shape torch.Size([1, 3, 1, 1]) Flatten out shape torch.Size([1, 3])
[blog] ✏️ Max Pooling and Global Average Pooling
На выходе последнего Inception module формируется карта признаков 7×7×1024. Если вытянуть их в линейный слой, получится более 50 тысяч признаков.
Идея слоя Global Average Pooling (GAP) в том, что все пространственные размеры, какими бы они ни были (например, 7×7, как в Inception, или 6×6, как на картинке), сворачиваются в 1×1.
Мы берем среднее значение независимо по каждому каналу полученной карты признаков.
Ранее считалось, что применение Global Average Pooling в составе архитектуры сверточной нейронной сети (CNN), то есть осуществление поканального усреднения пространственных измерений тензора, приведёт к полной потере пространственной информации о переданном сети объекте. Тем не менее, последние исследования 🎓[arxiv] показывают, что после такого преобразования часть пространственной информации всё же сохраняется. Несмотря на то, что семантическая информация (например информация о точных границах объекта), полностью утрачивается после Global Average Pooling, информация об абсолютном положении объекта на исходном изображении сохраняется и оказывается закодированной порядком следования компонент в оставшемся векторе усреднённых фильтров.
Применяя GAP, мы сократили количество признаков в 49 раз! Кроме того, Global Average Pooling уменьшает переобучение, т.к. мы избавляемся от влияния менее важных признаков.
import torch
import torch.nn as nn
from PIL import Image
def file2tensor(filename):
img = Image.open(filename)
t = torchvision.transforms.functional.to_tensor(img)
t = torchvision.transforms.functional.normalize(
t, (0.485, 0.456, 0.406), (0.229, 0.224, 0.225)
)
return t
class CNNfromHW(nn.Module):
def __init__(self, conv_module=None):
super().__init__()
self.activation = nn.ReLU()
self.conv1 = nn.Conv2d(3, 16, 5, padding=2) # 16xHxW
self.pool = nn.MaxPool2d(2, 2) # 16 x H/2 x W/2
self.conv2 = nn.Conv2d(16, 32, 3, padding=1) # 32 x H/2 x W/2
self.gap = nn.AdaptiveAvgPool2d((1, 1)) # Any spatial size -> 32x1x1
self.fc = nn.Linear(32, 10)
def forward(self, x):
print("Input shape", x.shape)
x = self.conv1(x) # 16xHxW
x = self.pool(x) # 16 x H/2 x W/2
x = self.conv2(x) # 32 x H/2 x W/2
x = self.activation(x) # Any spatial size -> 32x1x1
x = self.gap(x)
scores = self.fc(x.flatten(1))
print("Output shape", scores.shape)
return scores
print("CIFAR10 like")
input_random = torch.rand(1, 3, 32, 32)
model_with_gap = CNNfromHW()
out = model_with_gap(input_random)
print("Arbitrary size")
# Different sizes work too!
aramdillo_t = file2tensor("imagen/n02454379_10511_armadillo.jpg")
out = model_with_gap(aramdillo_t.unsqueeze(0))
CIFAR10 like Input shape torch.Size([1, 3, 32, 32]) Output shape torch.Size([1, 10]) Arbitrary size Input shape torch.Size([1, 3, 500, 500]) Output shape torch.Size([1, 10])
GoogLeNet: дополнительный классификатор
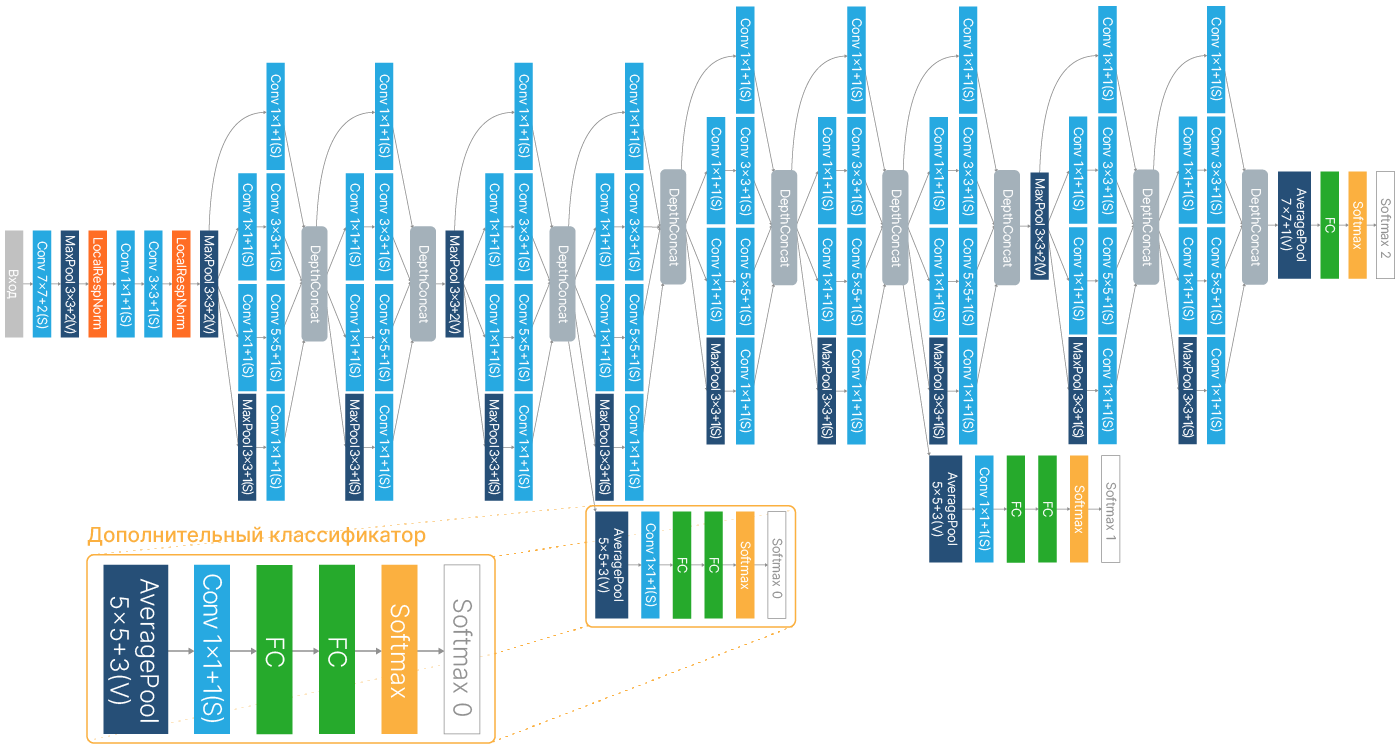
Помимо основного классификатора на выходе сети добавлены два дополнительных классификатора, встроенных в промежуточные слои. Они понадобились для того, чтобы улучшить обратное распространение градиента, без батч-нормализации в таких глубоких сетях градиент очень быстро затухал, и обучить сеть такого размера было серьёзной проблемой.
Обучение VGG осуществлялось непростым способом: сначала обучали 7 слоев, затем добавляли туда следующие и обучали это вручную. Без использования батч-нормализации вряд ли получится повторить результат.
Google подошел более системно, добавив дополнительные выходы, которые способствовали тому, чтобы градиент меньше затухал. Благодаря этому удалось решить серьёзную на тот момент проблему, которая ограничивала возможность обучения глубоких моделей. Статья про батч-нормализацию появилась как раз в 15-ом году, видимо, уже после выхода этой модели.
В 2015 году вышла статья Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 🎓[arxiv]. Благодаря добавлению слоя BatchNorm стало технически возможно обучать сети состоящие из десятков слоев.
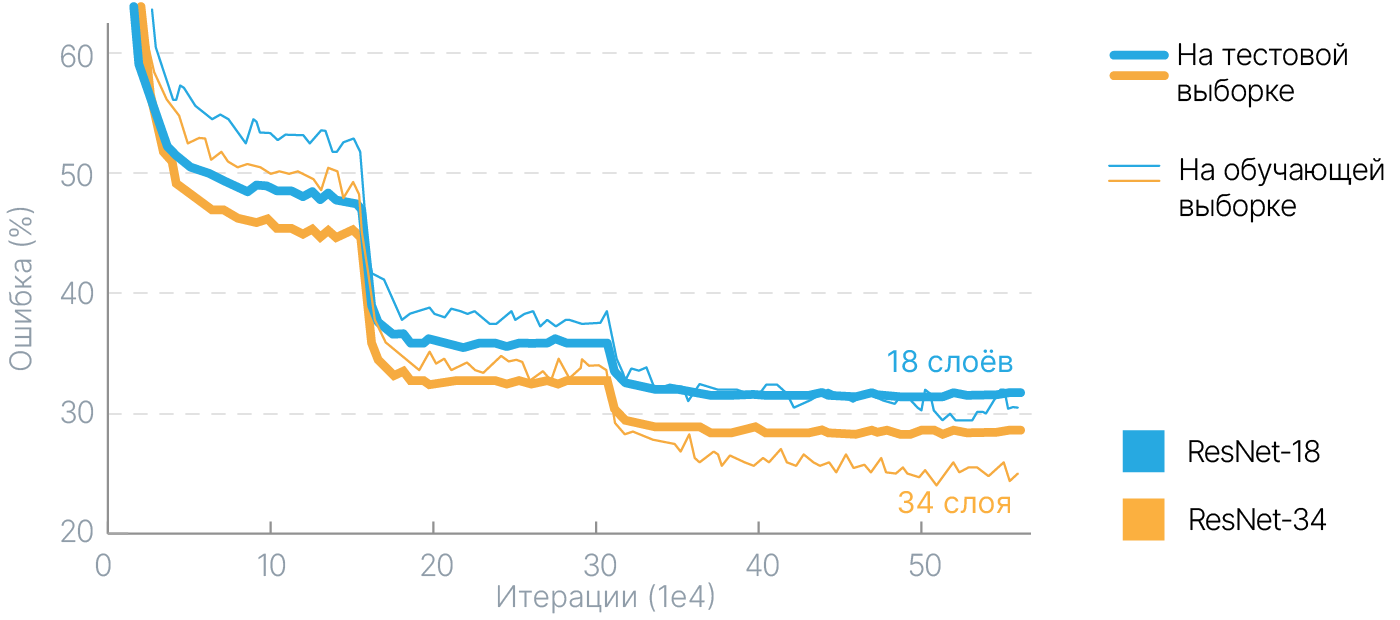
Но точность с увеличением глубины не росла:
[arxiv] 🎓 Deep Residual Learning for Image Recognition (He et al., 2015)

На графике выше приведено сравнение графиков обучения 56-слойной и 20-слойной сетей Microsoft, построенных на принципах VGGNet. Как видно из графиков, у 56-слойной сети и на тренировочном, и на тестовом датасете ошибка больше, чем у 20-слойной. Казалось бы, сеть, состоящая из большего количества слоёв, должна работать как минимум не хуже, чем сеть меньшего размера. К сожалению, проблема затухания градиента в этом случае не позволяет эффективно обучить более глубокую сеть.
В 2015 году соревнования выиграла сеть ResNet, архитектура которой предлагала новый подход к решению проблемы обучения глубоких сетей. Она состояла из 152 слоёв и снизила процент ошибок до 3,57%. Это сделало её почти в два раза эффективнее GoogLeNet.
При обучении нейронной сети методом обратного распространения ошибки модуль градиента постепенно уменьшается, проходя через каждый из слоёв сети. В глубоких сетях "длина" такого пути оказывается достаточной для того, чтобы модуль градиента стал мал и процесс обучения фактически остановился. В архитектуре ResNet такая проблема решается отказом от простого последовательного соединения слоёв (stacking) в пользу создания дополнительных связей в вычислительном графе нейронной сети, через которые градиент смог бы распространяться, минуя свёрточные слои и таким образом не затухая.
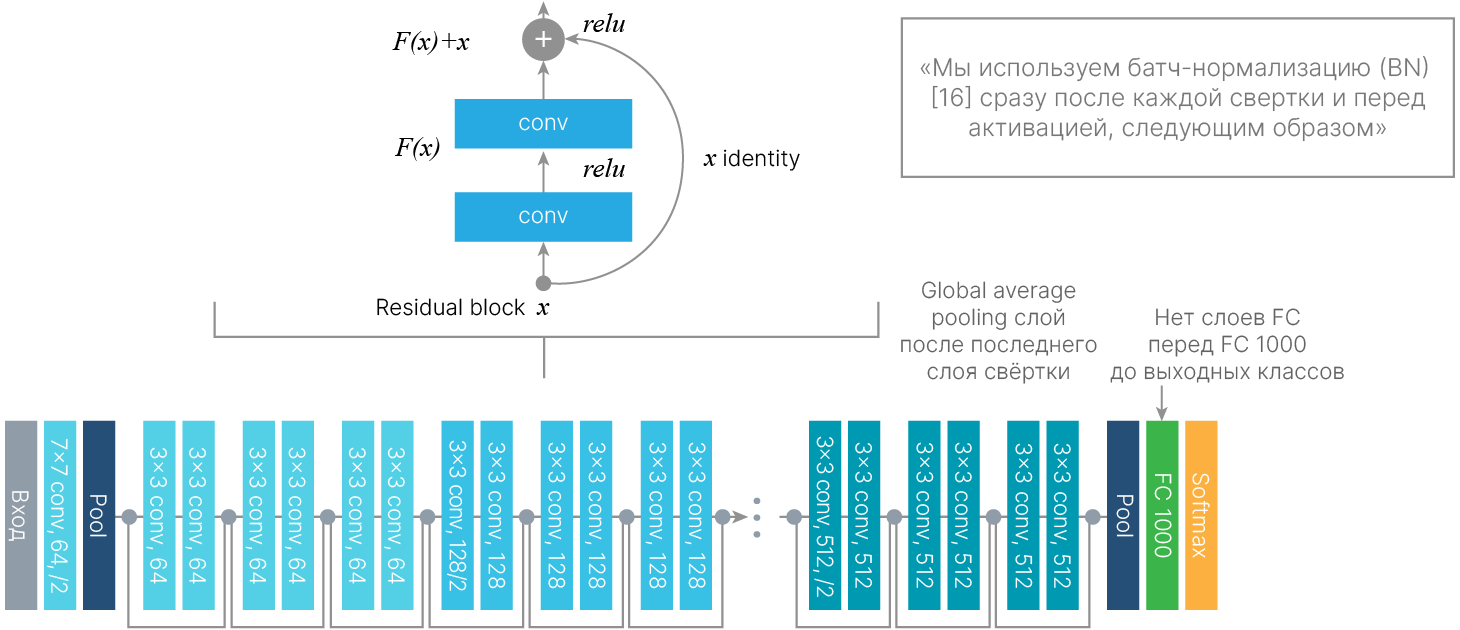
Сеть архитектуры ResNet состоит из набора так называемых Residual Block-ов. В данном блоке тензор входных признаков пропускается через пару последовательно соединённых свёрточных слоёв, после чего полученный результат складывается поканально с этим же неизменённым входным тензором. Свёрточные слои в таком блоке аппроксимируют не саму функциональную зависимость между входным и выходным тензором, а разность (анг. residual) между такой искомой зависимостью и тождественным преобразованием.
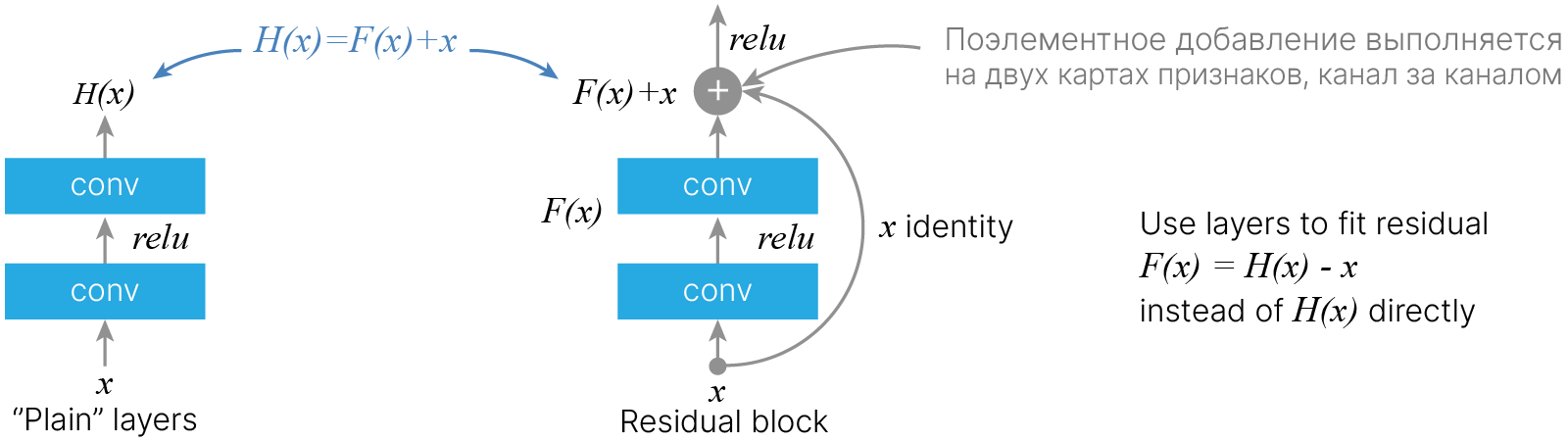
Идея Residual Block состоит в уточнении набора признаков на каждом блоке. Вместо того, чтобы перезаписывать признаки, мы добавляем к выходу предыдущего блока уточнение, сформированное на этом блоке.
Бонусы Residual Block:
Из таких блоков можно построить очень глубокую сеть (были эксперименты из 1000 слоев). Для решения конкретной задачи — победы на ImageNet — хватило 150 слоев (добавление большего количества блоков уже не давало прироста точности).
В ResNet используются многие идеи, которые присутствовали в предыдущих моделях:
Блоки состоят из конструкций, изображенных выше:
Код базового блока
import inspect
import torchvision.models.resnet as resnet
# BasicBlock
code = inspect.getsource(resnet.BasicBlock.forward)
print(code)
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
Так выглядит в коде базовый блок для сетей, в которых меньше 50 слоёв: свёртка, батч-нормализация, активация, свёртка, батч-нормализация.
Если свойство downsample != None, то вызывается слой downsample. Это свёртка 1×1 с шагом 2, уменьшающая пространственные размеры карты признаков.
Вот как инициализируются блоки (в первом сжатие происходит, во втором — нет).
from torchvision import models
resnet = models.resnet18(weights=None)
print(resnet.layer2)
Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)

Стоит отметить, что сеть ResNet-152 имеет существенно меньше обучаемых параметров, чем VGG-19 (58 миллионов против 144 миллионов).
Это достигнуто за счёт того, что в более глубоких сетях, помимо упомянутых Residual Block-ов с двумя свёрточными слоями с ядром 3×3, применялся более эффективный блок — bottleneck, состоящий из:
При обучении ResNet шаг обучения понижали вручную, когда точность выходила на плато.
Помимо того, что ResNet c огромным отрывом выиграла ImageNet у моделей прошлого года, она стала первой моделью, превысившей точность человеческой разметки. Решения на базе этой архитектуры также стали победителями на соревнованиях по детектированию и сегментации.
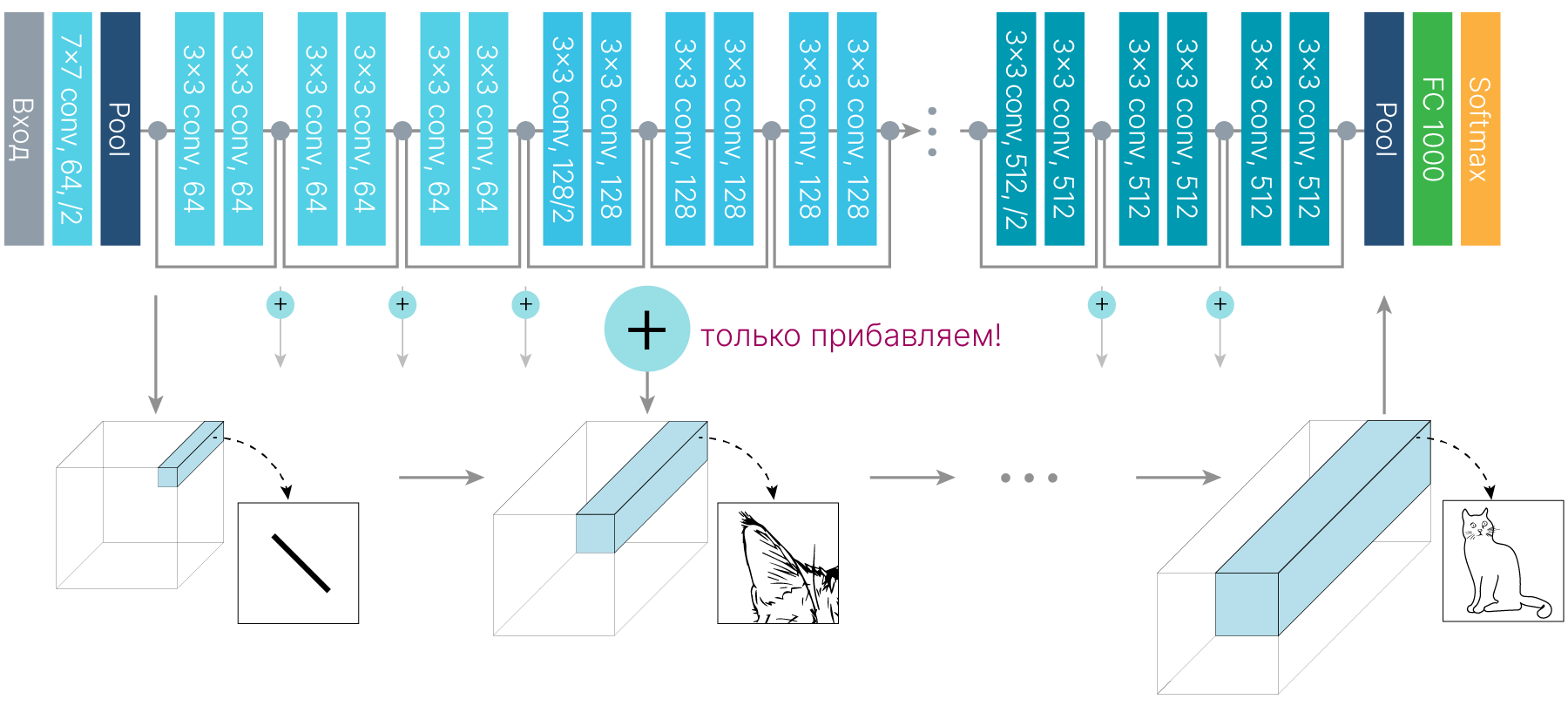
Можно взглянуть на архитектуру ResNet под таким углом: на первых слоях мы получаем базовую карту признаков, а на последующих улучшаем ее, прибавляя к ней новые уточненные признаки.
В AlexNet выходы первого слоя обрабатывались параллельно: половина каналов отправлялась на одну видеокарту, а половина — на другую.
Только на последних слоях полученные признаки объединялись.
Можно рассматривать такой подход как ансамблирование, как минимум, он позволяет выполнять часть операций параллельно и таким образом ускорить вычисления.
Эта идея реализуется при помощи Grouped convolution. Можно поканально разделить входной тензор признаков на произвольное количество частей (групп) и сворачивать их независимо.

[blog] ✏️ A Tutorial on Filter Groups (Grouped Convolution)
На картинке выше входная карта признаков разбивается на две группы по каналам. Над каждой группой свертки вычисляются независимо, а потом конкатенируются. Это позволяет заменить $D_{out}$ фильтров $H_{in} × H_{in} × D_{in}$ на $D_{out}$ фильтров $H_{in} × H_{in} × D_{in}/2$, сократив количество обучаемых весов в 2 раза.
Так как размер ядер станет меньше, получим выигрыш в производительности:
$$ \large \text{weights} = \frac{C}{G} C K^2, $$где $G$ — количество групп.
Возможность вычисления груповой свертки в PyTorch заложена в объект nn.Conv2d. Количество групп задается параметром groups, значение которого по умолчанию равно 1.
Сравним время, которое требуется на обычную свертку с groups = 1 и groups = 64 при вычислениях на CPU:
# CPU test
import time
import torch
from torch import nn
def time_synchronized():
torch.cuda.synchronize() if torch.cuda.is_available() else None
return time.time()
input_random = torch.rand(8, 512, 112, 112)
start = time_synchronized()
normal_conv = nn.Conv2d(512, 1024, 3, groups=1)
out = normal_conv(input_random)
tm = time_synchronized() - start
print(f"Normal convolution take {tm} sec.")
start = time_synchronized()
groupped_conv = nn.Conv2d(512, 1024, 3, groups=64)
out = groupped_conv(input_random)
tm = time_synchronized() - start
print(f"Groupped convolution take {tm} sec.")
Normal convolution take 8.310923337936401 sec. Groupped convolution take 1.1188368797302246 sec.
И на GPU:
# GPU test
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
start = time_synchronized()
normal_conv = nn.Conv2d(512, 1024, 3, groups=1).to(device)
out = normal_conv(input_random.to(device))
tm = time_synchronized() - start
print(f"Normal convolution take {tm} sec.")
start = time_synchronized()
groupped_conv = nn.Conv2d(512, 1024, 3, groups=64).to(device)
out = groupped_conv(input_random.to(device))
tm = time_synchronized() - start
print(f"Groupped convolution take {tm} sec.")
Normal convolution take 0.32497549057006836 sec. Groupped convolution take 0.061997413635253906 sec.
Применение групповой свертки с groups=64 дает выигрыш во времени. Это связано с уменьшением количества вычислительных операций.
ResNeXt объединяет идеи:
[arxiv] 🎓 2016 Aggregated Residual Transformations for Deep Neural Networks (Xie et al., 2016)
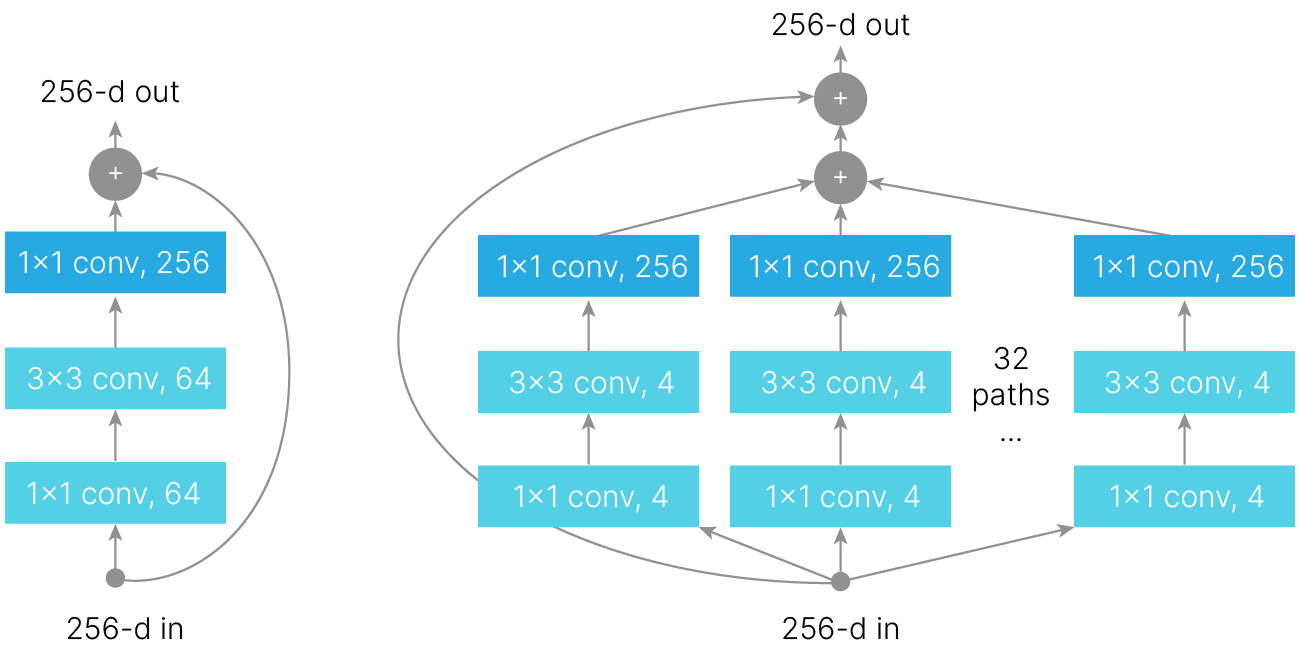
Следующая модель — ResNeXt. Эта сеть выиграла ImageNet в следующем году. Идея немного напоминает блок Inception в GoogLeNet: обрабатывать не сразу все каналы, а распараллелить обработку на несколько групп.
from torchvision import models
from torchsummary import summary
resnext = models.resnext50_32x4d(weights=None)
print(summary(resnext, (3, 224, 224), device="cpu"))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 128, 56, 56] 8,192
BatchNorm2d-6 [-1, 128, 56, 56] 256
ReLU-7 [-1, 128, 56, 56] 0
Conv2d-8 [-1, 128, 56, 56] 4,608
BatchNorm2d-9 [-1, 128, 56, 56] 256
ReLU-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 32,768
BatchNorm2d-12 [-1, 256, 56, 56] 512
Conv2d-13 [-1, 256, 56, 56] 16,384
BatchNorm2d-14 [-1, 256, 56, 56] 512
ReLU-15 [-1, 256, 56, 56] 0
Bottleneck-16 [-1, 256, 56, 56] 0
Conv2d-17 [-1, 128, 56, 56] 32,768
BatchNorm2d-18 [-1, 128, 56, 56] 256
ReLU-19 [-1, 128, 56, 56] 0
Conv2d-20 [-1, 128, 56, 56] 4,608
BatchNorm2d-21 [-1, 128, 56, 56] 256
ReLU-22 [-1, 128, 56, 56] 0
Conv2d-23 [-1, 256, 56, 56] 32,768
BatchNorm2d-24 [-1, 256, 56, 56] 512
ReLU-25 [-1, 256, 56, 56] 0
Bottleneck-26 [-1, 256, 56, 56] 0
Conv2d-27 [-1, 128, 56, 56] 32,768
BatchNorm2d-28 [-1, 128, 56, 56] 256
ReLU-29 [-1, 128, 56, 56] 0
Conv2d-30 [-1, 128, 56, 56] 4,608
BatchNorm2d-31 [-1, 128, 56, 56] 256
ReLU-32 [-1, 128, 56, 56] 0
Conv2d-33 [-1, 256, 56, 56] 32,768
BatchNorm2d-34 [-1, 256, 56, 56] 512
ReLU-35 [-1, 256, 56, 56] 0
Bottleneck-36 [-1, 256, 56, 56] 0
Conv2d-37 [-1, 256, 56, 56] 65,536
BatchNorm2d-38 [-1, 256, 56, 56] 512
ReLU-39 [-1, 256, 56, 56] 0
Conv2d-40 [-1, 256, 28, 28] 18,432
BatchNorm2d-41 [-1, 256, 28, 28] 512
ReLU-42 [-1, 256, 28, 28] 0
Conv2d-43 [-1, 512, 28, 28] 131,072
BatchNorm2d-44 [-1, 512, 28, 28] 1,024
Conv2d-45 [-1, 512, 28, 28] 131,072
BatchNorm2d-46 [-1, 512, 28, 28] 1,024
ReLU-47 [-1, 512, 28, 28] 0
Bottleneck-48 [-1, 512, 28, 28] 0
Conv2d-49 [-1, 256, 28, 28] 131,072
BatchNorm2d-50 [-1, 256, 28, 28] 512
ReLU-51 [-1, 256, 28, 28] 0
Conv2d-52 [-1, 256, 28, 28] 18,432
BatchNorm2d-53 [-1, 256, 28, 28] 512
ReLU-54 [-1, 256, 28, 28] 0
Conv2d-55 [-1, 512, 28, 28] 131,072
BatchNorm2d-56 [-1, 512, 28, 28] 1,024
ReLU-57 [-1, 512, 28, 28] 0
Bottleneck-58 [-1, 512, 28, 28] 0
Conv2d-59 [-1, 256, 28, 28] 131,072
BatchNorm2d-60 [-1, 256, 28, 28] 512
ReLU-61 [-1, 256, 28, 28] 0
Conv2d-62 [-1, 256, 28, 28] 18,432
BatchNorm2d-63 [-1, 256, 28, 28] 512
ReLU-64 [-1, 256, 28, 28] 0
Conv2d-65 [-1, 512, 28, 28] 131,072
BatchNorm2d-66 [-1, 512, 28, 28] 1,024
ReLU-67 [-1, 512, 28, 28] 0
Bottleneck-68 [-1, 512, 28, 28] 0
Conv2d-69 [-1, 256, 28, 28] 131,072
BatchNorm2d-70 [-1, 256, 28, 28] 512
ReLU-71 [-1, 256, 28, 28] 0
Conv2d-72 [-1, 256, 28, 28] 18,432
BatchNorm2d-73 [-1, 256, 28, 28] 512
ReLU-74 [-1, 256, 28, 28] 0
Conv2d-75 [-1, 512, 28, 28] 131,072
BatchNorm2d-76 [-1, 512, 28, 28] 1,024
ReLU-77 [-1, 512, 28, 28] 0
Bottleneck-78 [-1, 512, 28, 28] 0
Conv2d-79 [-1, 512, 28, 28] 262,144
BatchNorm2d-80 [-1, 512, 28, 28] 1,024
ReLU-81 [-1, 512, 28, 28] 0
Conv2d-82 [-1, 512, 14, 14] 73,728
BatchNorm2d-83 [-1, 512, 14, 14] 1,024
ReLU-84 [-1, 512, 14, 14] 0
Conv2d-85 [-1, 1024, 14, 14] 524,288
BatchNorm2d-86 [-1, 1024, 14, 14] 2,048
Conv2d-87 [-1, 1024, 14, 14] 524,288
BatchNorm2d-88 [-1, 1024, 14, 14] 2,048
ReLU-89 [-1, 1024, 14, 14] 0
Bottleneck-90 [-1, 1024, 14, 14] 0
Conv2d-91 [-1, 512, 14, 14] 524,288
BatchNorm2d-92 [-1, 512, 14, 14] 1,024
ReLU-93 [-1, 512, 14, 14] 0
Conv2d-94 [-1, 512, 14, 14] 73,728
BatchNorm2d-95 [-1, 512, 14, 14] 1,024
ReLU-96 [-1, 512, 14, 14] 0
Conv2d-97 [-1, 1024, 14, 14] 524,288
BatchNorm2d-98 [-1, 1024, 14, 14] 2,048
ReLU-99 [-1, 1024, 14, 14] 0
Bottleneck-100 [-1, 1024, 14, 14] 0
Conv2d-101 [-1, 512, 14, 14] 524,288
BatchNorm2d-102 [-1, 512, 14, 14] 1,024
ReLU-103 [-1, 512, 14, 14] 0
Conv2d-104 [-1, 512, 14, 14] 73,728
BatchNorm2d-105 [-1, 512, 14, 14] 1,024
ReLU-106 [-1, 512, 14, 14] 0
Conv2d-107 [-1, 1024, 14, 14] 524,288
BatchNorm2d-108 [-1, 1024, 14, 14] 2,048
ReLU-109 [-1, 1024, 14, 14] 0
Bottleneck-110 [-1, 1024, 14, 14] 0
Conv2d-111 [-1, 512, 14, 14] 524,288
BatchNorm2d-112 [-1, 512, 14, 14] 1,024
ReLU-113 [-1, 512, 14, 14] 0
Conv2d-114 [-1, 512, 14, 14] 73,728
BatchNorm2d-115 [-1, 512, 14, 14] 1,024
ReLU-116 [-1, 512, 14, 14] 0
Conv2d-117 [-1, 1024, 14, 14] 524,288
BatchNorm2d-118 [-1, 1024, 14, 14] 2,048
ReLU-119 [-1, 1024, 14, 14] 0
Bottleneck-120 [-1, 1024, 14, 14] 0
Conv2d-121 [-1, 512, 14, 14] 524,288
BatchNorm2d-122 [-1, 512, 14, 14] 1,024
ReLU-123 [-1, 512, 14, 14] 0
Conv2d-124 [-1, 512, 14, 14] 73,728
BatchNorm2d-125 [-1, 512, 14, 14] 1,024
ReLU-126 [-1, 512, 14, 14] 0
Conv2d-127 [-1, 1024, 14, 14] 524,288
BatchNorm2d-128 [-1, 1024, 14, 14] 2,048
ReLU-129 [-1, 1024, 14, 14] 0
Bottleneck-130 [-1, 1024, 14, 14] 0
Conv2d-131 [-1, 512, 14, 14] 524,288
BatchNorm2d-132 [-1, 512, 14, 14] 1,024
ReLU-133 [-1, 512, 14, 14] 0
Conv2d-134 [-1, 512, 14, 14] 73,728
BatchNorm2d-135 [-1, 512, 14, 14] 1,024
ReLU-136 [-1, 512, 14, 14] 0
Conv2d-137 [-1, 1024, 14, 14] 524,288
BatchNorm2d-138 [-1, 1024, 14, 14] 2,048
ReLU-139 [-1, 1024, 14, 14] 0
Bottleneck-140 [-1, 1024, 14, 14] 0
Conv2d-141 [-1, 1024, 14, 14] 1,048,576
BatchNorm2d-142 [-1, 1024, 14, 14] 2,048
ReLU-143 [-1, 1024, 14, 14] 0
Conv2d-144 [-1, 1024, 7, 7] 294,912
BatchNorm2d-145 [-1, 1024, 7, 7] 2,048
ReLU-146 [-1, 1024, 7, 7] 0
Conv2d-147 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-148 [-1, 2048, 7, 7] 4,096
Conv2d-149 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-150 [-1, 2048, 7, 7] 4,096
ReLU-151 [-1, 2048, 7, 7] 0
Bottleneck-152 [-1, 2048, 7, 7] 0
Conv2d-153 [-1, 1024, 7, 7] 2,097,152
BatchNorm2d-154 [-1, 1024, 7, 7] 2,048
ReLU-155 [-1, 1024, 7, 7] 0
Conv2d-156 [-1, 1024, 7, 7] 294,912
BatchNorm2d-157 [-1, 1024, 7, 7] 2,048
ReLU-158 [-1, 1024, 7, 7] 0
Conv2d-159 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-160 [-1, 2048, 7, 7] 4,096
ReLU-161 [-1, 2048, 7, 7] 0
Bottleneck-162 [-1, 2048, 7, 7] 0
Conv2d-163 [-1, 1024, 7, 7] 2,097,152
BatchNorm2d-164 [-1, 1024, 7, 7] 2,048
ReLU-165 [-1, 1024, 7, 7] 0
Conv2d-166 [-1, 1024, 7, 7] 294,912
BatchNorm2d-167 [-1, 1024, 7, 7] 2,048
ReLU-168 [-1, 1024, 7, 7] 0
Conv2d-169 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-170 [-1, 2048, 7, 7] 4,096
ReLU-171 [-1, 2048, 7, 7] 0
Bottleneck-172 [-1, 2048, 7, 7] 0
AdaptiveAvgPool2d-173 [-1, 2048, 1, 1] 0
Linear-174 [-1, 1000] 2,049,000
================================================================
Total params: 25,028,904
Trainable params: 25,028,904
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 361.78
Params size (MB): 95.48
Estimated Total Size (MB): 457.83
----------------------------------------------------------------
None
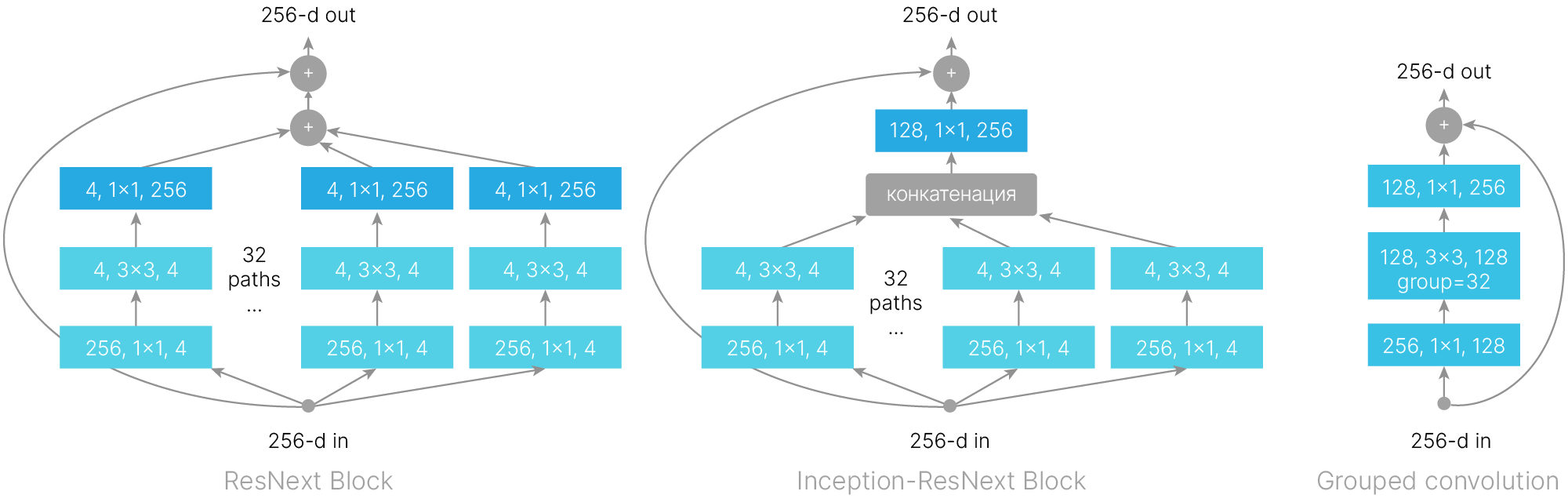
[blog] ✏️ Review of ResNet Family: from ResNet to ResNeSt
Альтернативой для блока ResNeXt (рисунок слева) является блок Inception-ResNeXt (рисунок посередине), объединивший идеи ResNeXt блока и Inception блока. Применение таких блоков вместо ResNeXt позволяет немного улучшить результаты ResNeXt.
MobileNet — архитектура нейронной сети, специально созданная для работы на CPU мобильных устройств. Высокая скорость работы первой версии MobileNet достигалась благодаря разделимой по глубине свертке (Depthwise Separable Convolution).
Также для данной архитектуры предусматривается возможность варьировать размер входного изображения и ширину слоев.
Функцией активации у MobileNet обычно выступает ReLU6 (ограничение сверху у данной функции активации призвано облегчить дальнейшую 8-битную квантизацию нейронной сети).
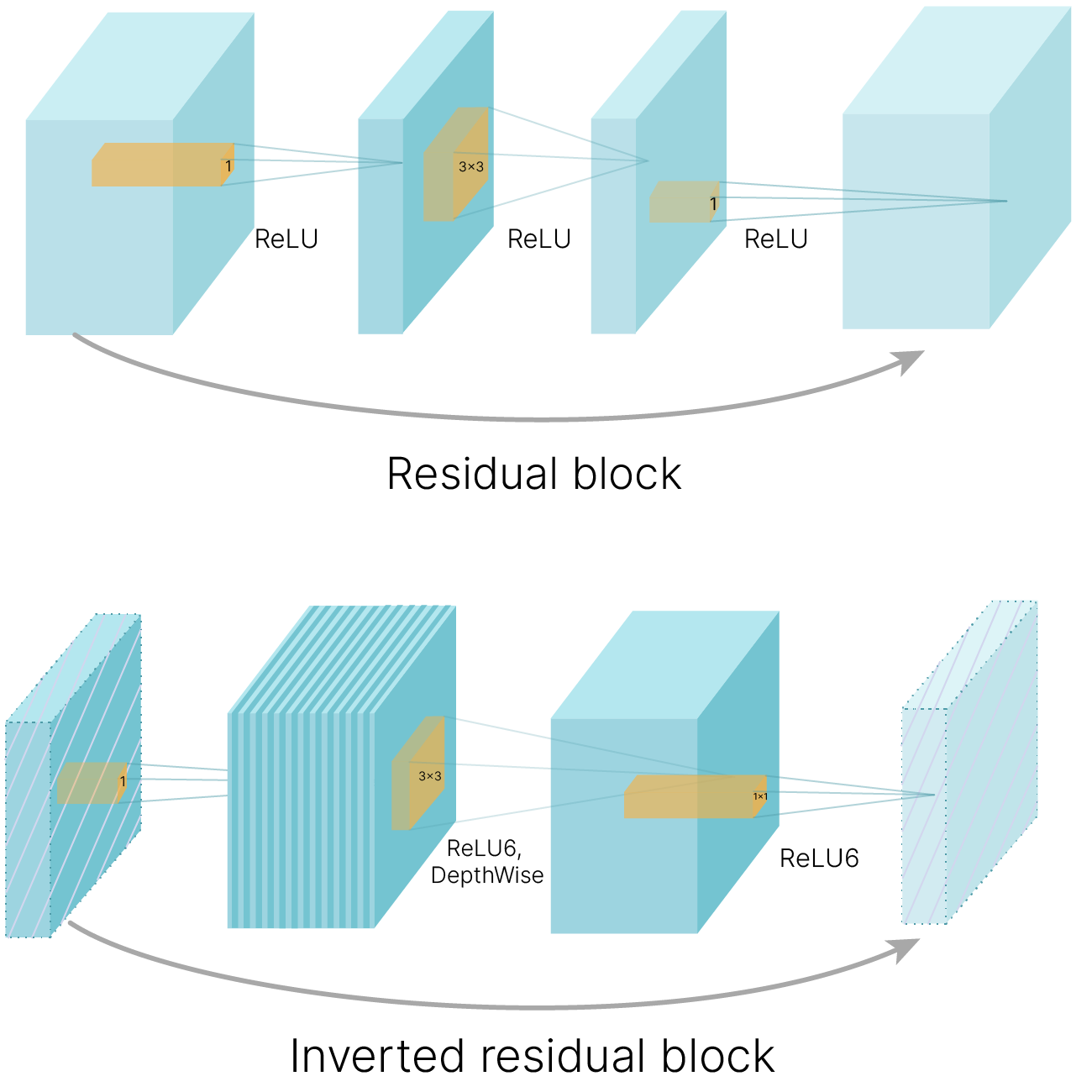
В 2018 году была предложена архитектура MobileNetV2, которая существенно превосходит первую версию благодаря добавлению к архитектуре инвертированных остаточных блоков (Inverted Residual Block).
А в 2019 году была предложена уже MobileNetV3, которая была получена при помощи автоматического поиска архитектуры (Network Architecture Search) и дополнительно включала в себя модули squeeze-and-excitation и немонотонную функцию активации swish ("жесткая" версия которой, hard-swish, так же призвана облегчить квантизацию).
Давайте разберемся, как все эти улучшения работают.
Обычная свертка в CNN одновременно работает с шириной, высотой и глубиной (каналами) карты признаков. Разделимая по глубине свёртка (Depthwise separable convolution) разделяет вычисления на два этапа:
Применение разделимой по глубине свертки позволяет уменьшить количество обучаемых параметров и вычислительных операций при небольшой потере точности.
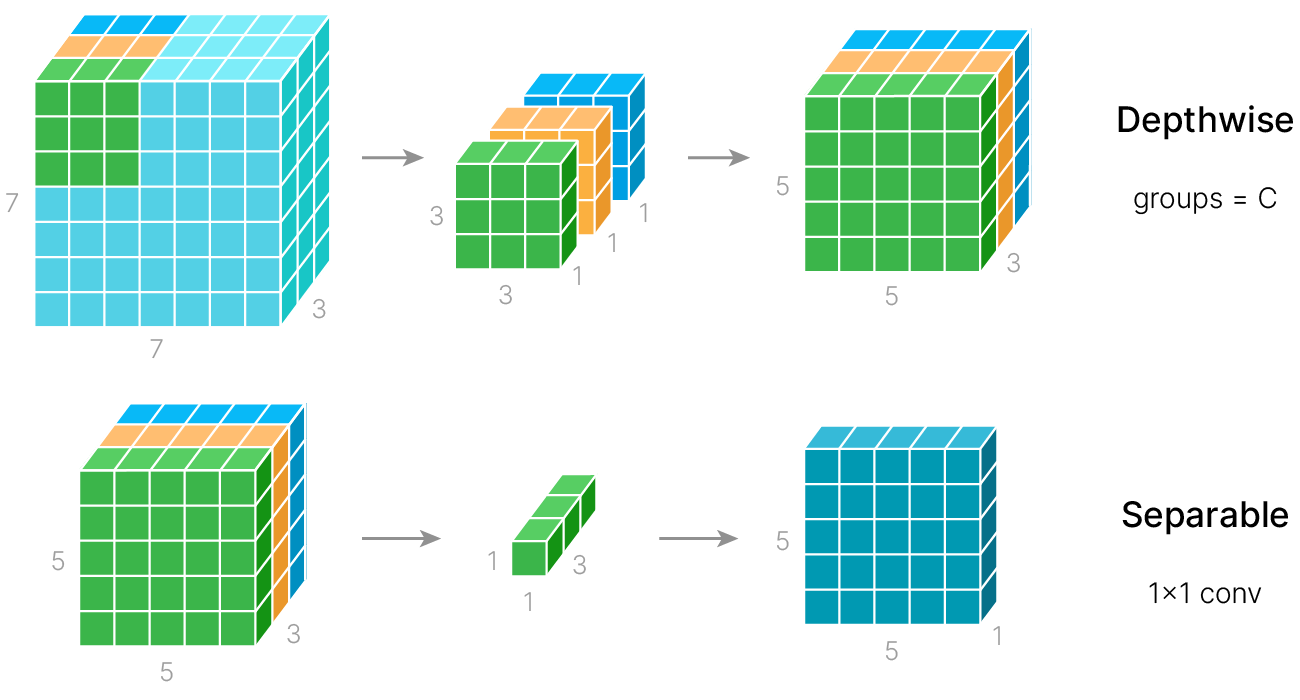
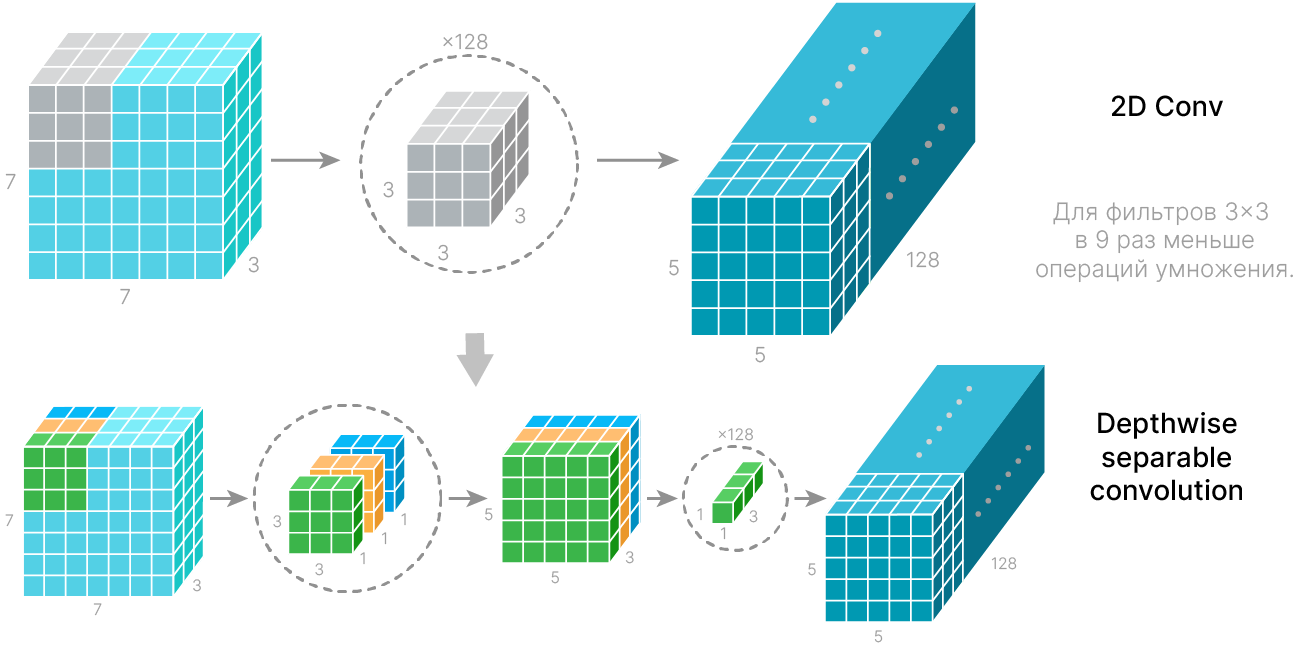
$\text{DepthwiseSeparableConv} = \text{GroupedConv}(\text{group} = C) + \text{Conv}(1×1)$
Количество обучаемых параметров (весов):
Чем больше каналов, тем больше экономия.
При размере ядра $3×3$ $(K=3)$ :
$\text{Conv2d}: \qquad \qquad \qquad \qquad 3^2 C^2 $
$\text{DepthwiseSeparableConv}: \ 3^2C +C^2$
Инвертированный остаточный блок (Inverted residual block) напоминает классический residual block из архитектуры ResNet, однако имеет ряд существенных отличий. Дело в том, что классический residual block, из-за резкого уменьшения размерности пространства в комбинации с функцией активации ReLU, которая уничтожает всю информацию от отрицательных значений, приводит к потере большого количества информации. Поэтому вместо уменьшения количества слоев в середине, оно, наоборот, увеличивается. Увеличение вычислительной сложности компенсируется использованием разделимой по глубине свертки. А на входе и выходе из блока (где количество слоев уменьшается) отсутствует нелинейность (ReLU).

Картинка из статьи 2018 года (не самая свежая), но она позволяет визуально сравнить модели по трем параметрам:
Здесь можно увидеть, что VGGNet — огромные по объёму модели, но по нынешним меркам они обладают средней точностью. Они требуют больших вычислительных ресурсов, поэтому сейчас имеет смысл их использовать разве что в учебных целях, а модели на базе ResNet (ResNet-50, ResNet-152) довольно хороши: в плане точности какого-то большого отрыва от них здесь не видно. Но, тем не менее, есть модели, которые работают чуть лучше. Рассмотрим их кратко, чтобы было понимание того, куда двигалась мысль в этой области.
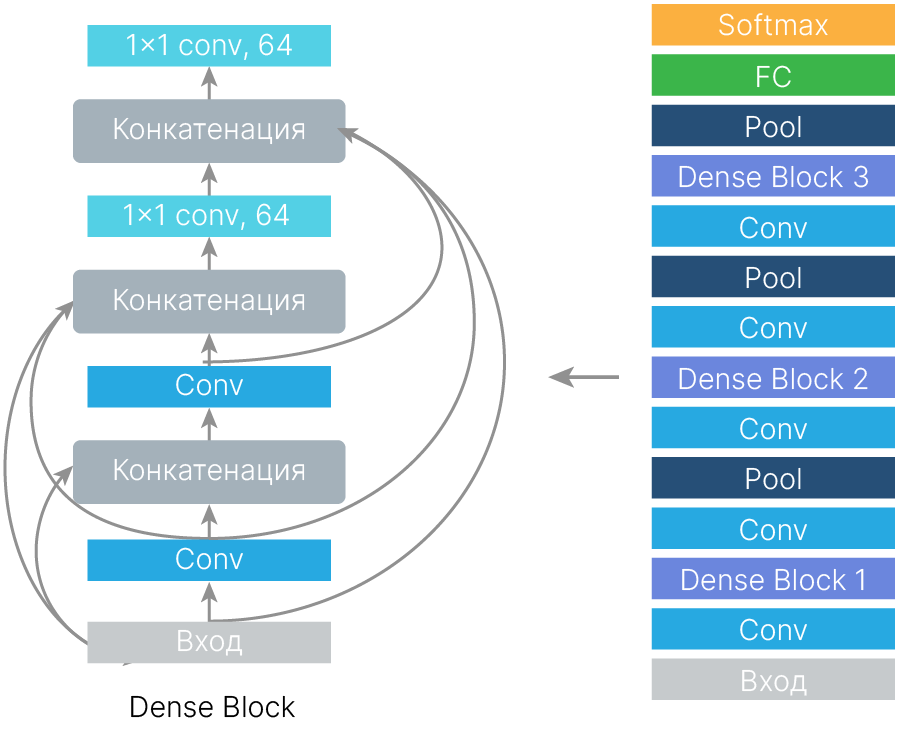
Еще один вариант, что можно сделать со слоями — добавить дополнительные связи в обход сверточных блоков, чтобы градиент проходил ещё лучше.
Можно также заменить сумму на конкатенацию. Чтобы не увеличить при этому глубину карт признаков, можно использовать свёртки 1×1.
На этих двух принципах построен DenseNet. С точки зрения ресурсов он чуть более требовательный, чем базовый ResNet, и немного более точный.
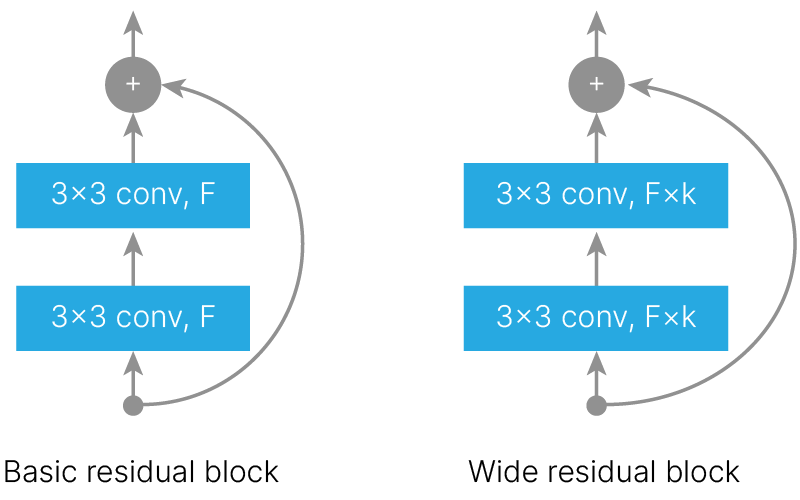
Другой подход состоит в том, чтобы увеличивать не глубину, а ширину модели. Авторы утверждают, что ширина (количество фильтров) residuals блока — значительно более важный фактор, чем глубина нейронной сети. 50-слойный Wide ResNet показывает лучшие результаты, чем оригинальный 152-х слойный ResNet. С точки зрения вычислительных ресурсов, использование ширины вместо глубины позволяет более эффективно параллелить вычисления на GPU (parallelizable).
При обычной свёртке значения всех каналов учитывались одинаково. Идея SE блока состоит в том, чтобы взвесить каналы, умножив каждый на свой коэффициент из интервала $[0 \dots 1]$.
Но эти коэффициенты должны зависеть от входных данных, тогда это поможет учитывать контекст. Например, найти шишку рядом с ёлкой более вероятно, чем рядом с компьютером.
[arxiv] 🎓 Squeeze-and-Excitation Networks (Hu et al., 2017)
[blog] ✏️ Channel Attention and Squeeze-and-Excitation Networks (SENet)
Основным элементом CNN являются фильтры, которые детектируют группы пикселей, обладающих локальной связностью (рецептивное поле). Сверточный фильтр объединяет:
Он не отделяет эти два типа информации друг от друга. За счет чередования сверточных слоев и операций субдискретизации (pooling) CNN способны получать представления изображений (image representation), которые распознают сложные иерархические паттерны.
Архитектуры сверточных нейронных сетей, рассмотренные нами до этого, концентрировались на поиске лучшего представления изображения за счет улучшения способов поиска зависимости между признаками в пространстве (Inception module, Residual block и т.д.), не затрагивая отношения между каналами.
SENet (Squeeze-and-Excitation Networks) — архитектура нейронной сети, одержавшая победу в ILSVRS-2017. Создатели SENet предложили новую архитектуру блока, называемую Squeeze-and-Excitation (SE-блок), целью которой является поиск лучшего представления изображения за счет моделирования взаимодействия между каналами. Идея состоит в том, что не все каналы одинаково важны, поэтому мы можем выборочно выделять из них более информативные и подавлять менее информативные, создав механизм взвешивания каналов (feature recalibration). SE-блок состоит из следующих процессов:
"Сжатие" (squeeze) каждого канала до единственного числового значения с использованием global pooling. Эта процедура позволяет получить некое глобальное представление результата обработки исходного изображения, сделанного каждым из сверточных фильтров, (global information embedding).
"Возбуждение" (excitation) использует информацию, полученную на этапе "сжатия", для определения взаимодействий между каналами. Для этого используются два полносвязных слоя, первый из которых вводит "узкое место" (bottleneck), уменьшающее размерность в соответствии с параметром сжатия, а второй восстанавливает размерность до исходной. В результате этой операции получается набор активаций, использующийся для взвешивания соответствующих каналов исходного изображения (adaptive recalibration).
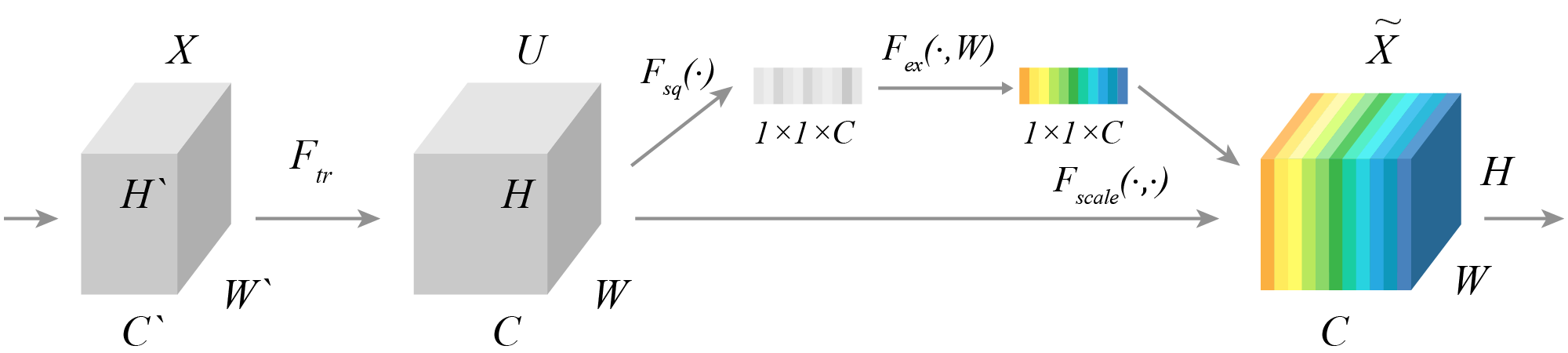
Таким образом, SE-блок использует механизм, идейно напоминающий self-attention, для каналов, чьи отношения не ограничены локальным рецептивным полем соответствующих сверточных фильтров.
Описанный SE-блок может быть интегрирован в современные архитектуры сверточных нейронных сетей, например, входя в состав остаточного блока сети ResNet или Inception модуля, как изображено на рисунке.
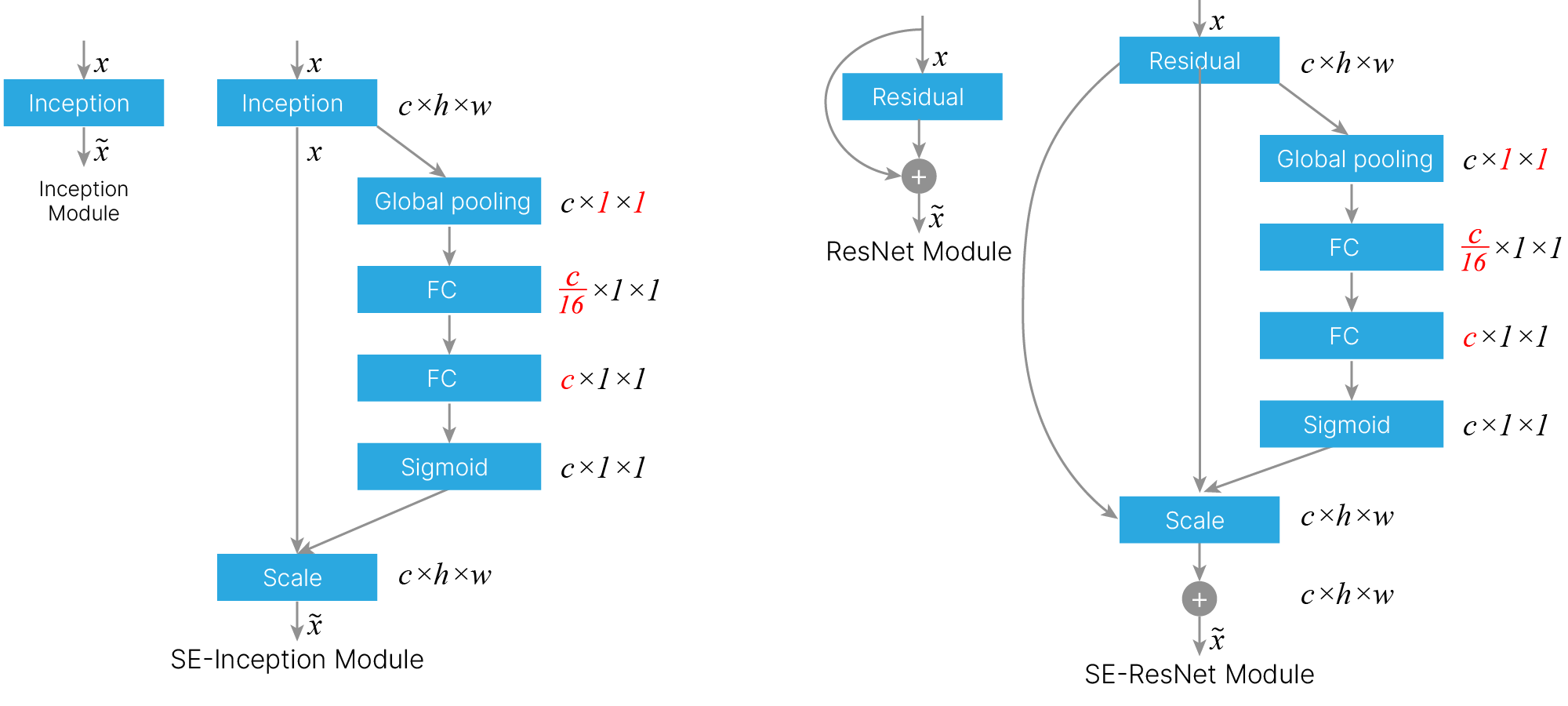
## Custom SE block
class SE_Block(nn.Module):
"credits: https://github.com/moskomule/senet.pytorch/blob/master/senet/se_module.py#L4"
def __init__(self, c, r=16):
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Linear(c, c // r, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c // r, c, bias=False),
nn.Sigmoid(),
)
def forward(self, x):
bs, c, _, _ = x.shape
y = self.squeeze(x).view(bs, c)
y = self.excitation(y).view(bs, c, 1, 1)
print("Coefficients ", y.shape)
return x * y.expand_as(x)
dummy = torch.randn(16, 256, 7, 7)
se_block = SE_Block(256) # for 256 channels
print("Absolute sum", dummy.abs().sum().item())
se_out = se_block(dummy)
print("Sum after se_block", se_out.abs().sum().item())
Absolute sum 160095.890625 Coefficients torch.Size([16, 256, 1, 1]) Sum after se_block 80070.8125
Теперь модель отключает каналы, отвечающие за признаки, которые не важны в текущем контексте:

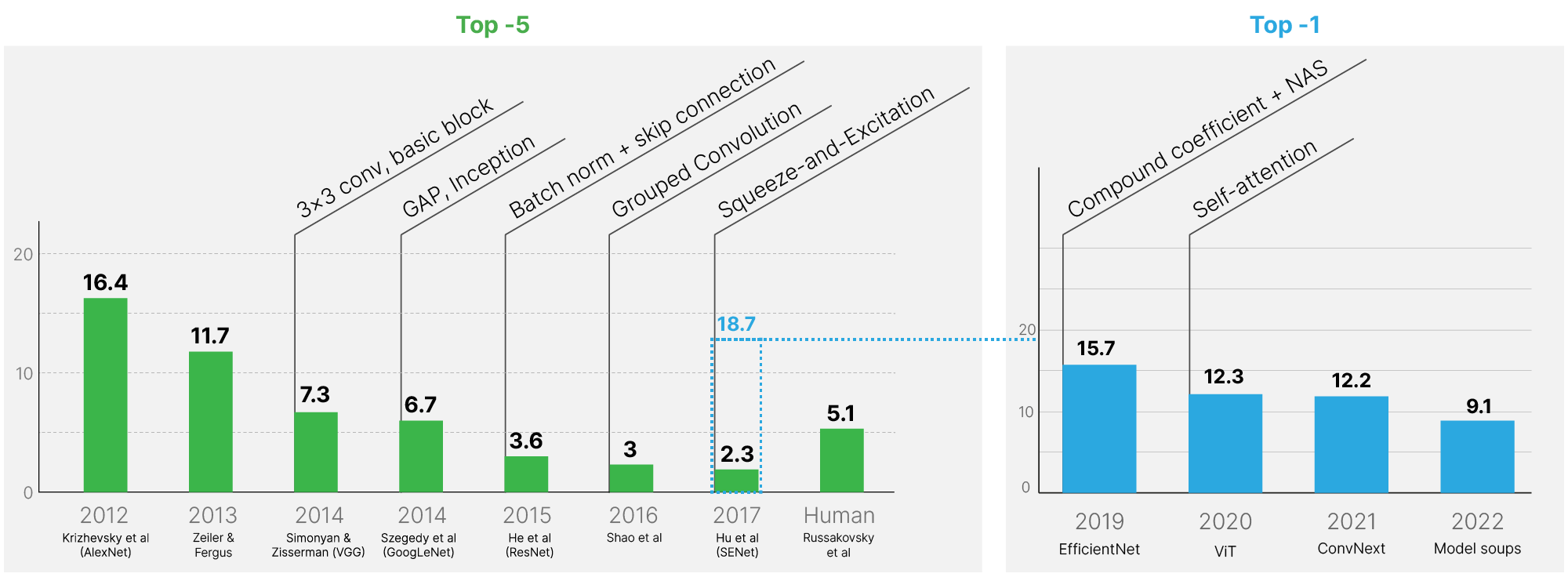
Мы рассмотрели достаточно много блоков, из которых можно построить модель. Но как оптимально их использовать? Надо ли делать сеть максимально глубокой? Или надо стремиться выделить как можно больше признаков?
Исследователи сосредоточились на подборе оптимальной архитектуры.
Идея EfficientNet состоит в том, чтобы получить возможность подбирать оптимальную глубину (число слоев), ширину (число каналов в слое) и разрешение (длину и ширину карты признаков) для конкретной задачи. Например, если мы берём входное изображение больше, чем обычно (например, 1024×1024 вместо привычных 256×256), то сети потребуется больше слоёв для увеличения рецептивного поля и больше каналов для захвата более тонких деталей на большом изображении.

Масштабирование происходит с помощью составного коэффициента (compound coefficient).
Например, если у нас есть возможность использовать в $2^N$ больше вычислительных ресурсов, то мы можем просто увеличить глубину сети на $\alpha^N$, ширину — на $\beta^N$, и размер изображения — на $\gamma^N$, где $\alpha$, $\beta$ и $\gamma$ — постоянные коэффициенты, определяемые grid search на исходной немасштабированной модели.
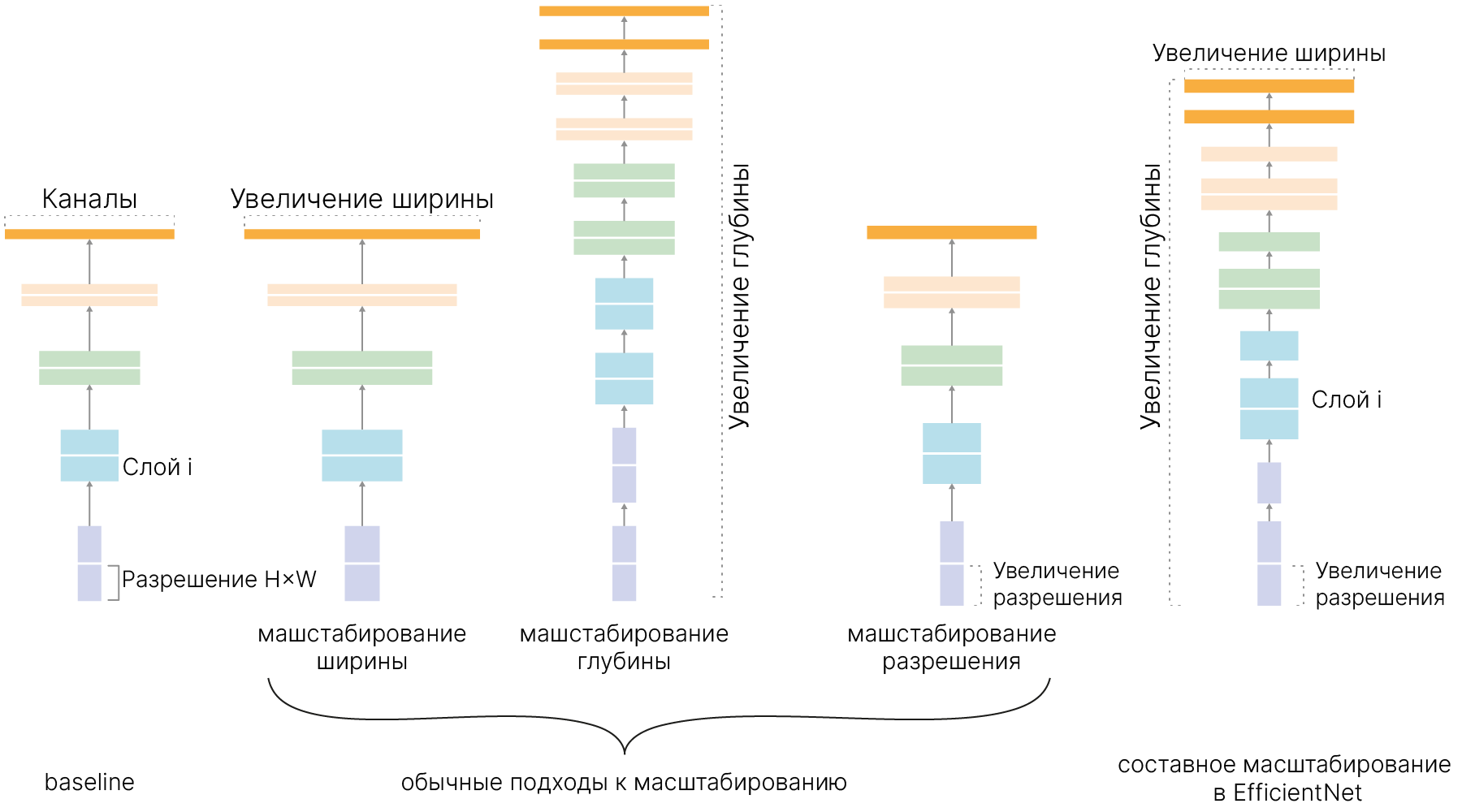
Базовая сеть EfficientNet основана на инвертированных узких остаточных блоках MobileNet в дополнение к блокам сжатия и возбуждения (squeeze-and-excitation blocks).
from torchsummary import summary
from torchvision.models import efficientnet_b0
en_b0 = efficientnet_b0()
print(summary(en_b0, (3, 224, 224), device="cpu"))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 112, 112] 864
BatchNorm2d-2 [-1, 32, 112, 112] 64
SiLU-3 [-1, 32, 112, 112] 0
Conv2d-4 [-1, 32, 112, 112] 288
BatchNorm2d-5 [-1, 32, 112, 112] 64
SiLU-6 [-1, 32, 112, 112] 0
AdaptiveAvgPool2d-7 [-1, 32, 1, 1] 0
Conv2d-8 [-1, 8, 1, 1] 264
SiLU-9 [-1, 8, 1, 1] 0
Conv2d-10 [-1, 32, 1, 1] 288
Sigmoid-11 [-1, 32, 1, 1] 0
SqueezeExcitation-12 [-1, 32, 112, 112] 0
Conv2d-13 [-1, 16, 112, 112] 512
BatchNorm2d-14 [-1, 16, 112, 112] 32
MBConv-15 [-1, 16, 112, 112] 0
Conv2d-16 [-1, 96, 112, 112] 1,536
BatchNorm2d-17 [-1, 96, 112, 112] 192
SiLU-18 [-1, 96, 112, 112] 0
Conv2d-19 [-1, 96, 56, 56] 864
BatchNorm2d-20 [-1, 96, 56, 56] 192
SiLU-21 [-1, 96, 56, 56] 0
AdaptiveAvgPool2d-22 [-1, 96, 1, 1] 0
Conv2d-23 [-1, 4, 1, 1] 388
SiLU-24 [-1, 4, 1, 1] 0
Conv2d-25 [-1, 96, 1, 1] 480
Sigmoid-26 [-1, 96, 1, 1] 0
SqueezeExcitation-27 [-1, 96, 56, 56] 0
Conv2d-28 [-1, 24, 56, 56] 2,304
BatchNorm2d-29 [-1, 24, 56, 56] 48
MBConv-30 [-1, 24, 56, 56] 0
Conv2d-31 [-1, 144, 56, 56] 3,456
BatchNorm2d-32 [-1, 144, 56, 56] 288
SiLU-33 [-1, 144, 56, 56] 0
Conv2d-34 [-1, 144, 56, 56] 1,296
BatchNorm2d-35 [-1, 144, 56, 56] 288
SiLU-36 [-1, 144, 56, 56] 0
AdaptiveAvgPool2d-37 [-1, 144, 1, 1] 0
Conv2d-38 [-1, 6, 1, 1] 870
SiLU-39 [-1, 6, 1, 1] 0
Conv2d-40 [-1, 144, 1, 1] 1,008
Sigmoid-41 [-1, 144, 1, 1] 0
SqueezeExcitation-42 [-1, 144, 56, 56] 0
Conv2d-43 [-1, 24, 56, 56] 3,456
BatchNorm2d-44 [-1, 24, 56, 56] 48
StochasticDepth-45 [-1, 24, 56, 56] 0
MBConv-46 [-1, 24, 56, 56] 0
Conv2d-47 [-1, 144, 56, 56] 3,456
BatchNorm2d-48 [-1, 144, 56, 56] 288
SiLU-49 [-1, 144, 56, 56] 0
Conv2d-50 [-1, 144, 28, 28] 3,600
BatchNorm2d-51 [-1, 144, 28, 28] 288
SiLU-52 [-1, 144, 28, 28] 0
AdaptiveAvgPool2d-53 [-1, 144, 1, 1] 0
Conv2d-54 [-1, 6, 1, 1] 870
SiLU-55 [-1, 6, 1, 1] 0
Conv2d-56 [-1, 144, 1, 1] 1,008
Sigmoid-57 [-1, 144, 1, 1] 0
SqueezeExcitation-58 [-1, 144, 28, 28] 0
Conv2d-59 [-1, 40, 28, 28] 5,760
BatchNorm2d-60 [-1, 40, 28, 28] 80
MBConv-61 [-1, 40, 28, 28] 0
Conv2d-62 [-1, 240, 28, 28] 9,600
BatchNorm2d-63 [-1, 240, 28, 28] 480
SiLU-64 [-1, 240, 28, 28] 0
Conv2d-65 [-1, 240, 28, 28] 6,000
BatchNorm2d-66 [-1, 240, 28, 28] 480
SiLU-67 [-1, 240, 28, 28] 0
AdaptiveAvgPool2d-68 [-1, 240, 1, 1] 0
Conv2d-69 [-1, 10, 1, 1] 2,410
SiLU-70 [-1, 10, 1, 1] 0
Conv2d-71 [-1, 240, 1, 1] 2,640
Sigmoid-72 [-1, 240, 1, 1] 0
SqueezeExcitation-73 [-1, 240, 28, 28] 0
Conv2d-74 [-1, 40, 28, 28] 9,600
BatchNorm2d-75 [-1, 40, 28, 28] 80
StochasticDepth-76 [-1, 40, 28, 28] 0
MBConv-77 [-1, 40, 28, 28] 0
Conv2d-78 [-1, 240, 28, 28] 9,600
BatchNorm2d-79 [-1, 240, 28, 28] 480
SiLU-80 [-1, 240, 28, 28] 0
Conv2d-81 [-1, 240, 14, 14] 2,160
BatchNorm2d-82 [-1, 240, 14, 14] 480
SiLU-83 [-1, 240, 14, 14] 0
AdaptiveAvgPool2d-84 [-1, 240, 1, 1] 0
Conv2d-85 [-1, 10, 1, 1] 2,410
SiLU-86 [-1, 10, 1, 1] 0
Conv2d-87 [-1, 240, 1, 1] 2,640
Sigmoid-88 [-1, 240, 1, 1] 0
SqueezeExcitation-89 [-1, 240, 14, 14] 0
Conv2d-90 [-1, 80, 14, 14] 19,200
BatchNorm2d-91 [-1, 80, 14, 14] 160
MBConv-92 [-1, 80, 14, 14] 0
Conv2d-93 [-1, 480, 14, 14] 38,400
BatchNorm2d-94 [-1, 480, 14, 14] 960
SiLU-95 [-1, 480, 14, 14] 0
Conv2d-96 [-1, 480, 14, 14] 4,320
BatchNorm2d-97 [-1, 480, 14, 14] 960
SiLU-98 [-1, 480, 14, 14] 0
AdaptiveAvgPool2d-99 [-1, 480, 1, 1] 0
Conv2d-100 [-1, 20, 1, 1] 9,620
SiLU-101 [-1, 20, 1, 1] 0
Conv2d-102 [-1, 480, 1, 1] 10,080
Sigmoid-103 [-1, 480, 1, 1] 0
SqueezeExcitation-104 [-1, 480, 14, 14] 0
Conv2d-105 [-1, 80, 14, 14] 38,400
BatchNorm2d-106 [-1, 80, 14, 14] 160
StochasticDepth-107 [-1, 80, 14, 14] 0
MBConv-108 [-1, 80, 14, 14] 0
Conv2d-109 [-1, 480, 14, 14] 38,400
BatchNorm2d-110 [-1, 480, 14, 14] 960
SiLU-111 [-1, 480, 14, 14] 0
Conv2d-112 [-1, 480, 14, 14] 4,320
BatchNorm2d-113 [-1, 480, 14, 14] 960
SiLU-114 [-1, 480, 14, 14] 0
AdaptiveAvgPool2d-115 [-1, 480, 1, 1] 0
Conv2d-116 [-1, 20, 1, 1] 9,620
SiLU-117 [-1, 20, 1, 1] 0
Conv2d-118 [-1, 480, 1, 1] 10,080
Sigmoid-119 [-1, 480, 1, 1] 0
SqueezeExcitation-120 [-1, 480, 14, 14] 0
Conv2d-121 [-1, 80, 14, 14] 38,400
BatchNorm2d-122 [-1, 80, 14, 14] 160
StochasticDepth-123 [-1, 80, 14, 14] 0
MBConv-124 [-1, 80, 14, 14] 0
Conv2d-125 [-1, 480, 14, 14] 38,400
BatchNorm2d-126 [-1, 480, 14, 14] 960
SiLU-127 [-1, 480, 14, 14] 0
Conv2d-128 [-1, 480, 14, 14] 12,000
BatchNorm2d-129 [-1, 480, 14, 14] 960
SiLU-130 [-1, 480, 14, 14] 0
AdaptiveAvgPool2d-131 [-1, 480, 1, 1] 0
Conv2d-132 [-1, 20, 1, 1] 9,620
SiLU-133 [-1, 20, 1, 1] 0
Conv2d-134 [-1, 480, 1, 1] 10,080
Sigmoid-135 [-1, 480, 1, 1] 0
SqueezeExcitation-136 [-1, 480, 14, 14] 0
Conv2d-137 [-1, 112, 14, 14] 53,760
BatchNorm2d-138 [-1, 112, 14, 14] 224
MBConv-139 [-1, 112, 14, 14] 0
Conv2d-140 [-1, 672, 14, 14] 75,264
BatchNorm2d-141 [-1, 672, 14, 14] 1,344
SiLU-142 [-1, 672, 14, 14] 0
Conv2d-143 [-1, 672, 14, 14] 16,800
BatchNorm2d-144 [-1, 672, 14, 14] 1,344
SiLU-145 [-1, 672, 14, 14] 0
AdaptiveAvgPool2d-146 [-1, 672, 1, 1] 0
Conv2d-147 [-1, 28, 1, 1] 18,844
SiLU-148 [-1, 28, 1, 1] 0
Conv2d-149 [-1, 672, 1, 1] 19,488
Sigmoid-150 [-1, 672, 1, 1] 0
SqueezeExcitation-151 [-1, 672, 14, 14] 0
Conv2d-152 [-1, 112, 14, 14] 75,264
BatchNorm2d-153 [-1, 112, 14, 14] 224
StochasticDepth-154 [-1, 112, 14, 14] 0
MBConv-155 [-1, 112, 14, 14] 0
Conv2d-156 [-1, 672, 14, 14] 75,264
BatchNorm2d-157 [-1, 672, 14, 14] 1,344
SiLU-158 [-1, 672, 14, 14] 0
Conv2d-159 [-1, 672, 14, 14] 16,800
BatchNorm2d-160 [-1, 672, 14, 14] 1,344
SiLU-161 [-1, 672, 14, 14] 0
AdaptiveAvgPool2d-162 [-1, 672, 1, 1] 0
Conv2d-163 [-1, 28, 1, 1] 18,844
SiLU-164 [-1, 28, 1, 1] 0
Conv2d-165 [-1, 672, 1, 1] 19,488
Sigmoid-166 [-1, 672, 1, 1] 0
SqueezeExcitation-167 [-1, 672, 14, 14] 0
Conv2d-168 [-1, 112, 14, 14] 75,264
BatchNorm2d-169 [-1, 112, 14, 14] 224
StochasticDepth-170 [-1, 112, 14, 14] 0
MBConv-171 [-1, 112, 14, 14] 0
Conv2d-172 [-1, 672, 14, 14] 75,264
BatchNorm2d-173 [-1, 672, 14, 14] 1,344
SiLU-174 [-1, 672, 14, 14] 0
Conv2d-175 [-1, 672, 7, 7] 16,800
BatchNorm2d-176 [-1, 672, 7, 7] 1,344
SiLU-177 [-1, 672, 7, 7] 0
AdaptiveAvgPool2d-178 [-1, 672, 1, 1] 0
Conv2d-179 [-1, 28, 1, 1] 18,844
SiLU-180 [-1, 28, 1, 1] 0
Conv2d-181 [-1, 672, 1, 1] 19,488
Sigmoid-182 [-1, 672, 1, 1] 0
SqueezeExcitation-183 [-1, 672, 7, 7] 0
Conv2d-184 [-1, 192, 7, 7] 129,024
BatchNorm2d-185 [-1, 192, 7, 7] 384
MBConv-186 [-1, 192, 7, 7] 0
Conv2d-187 [-1, 1152, 7, 7] 221,184
BatchNorm2d-188 [-1, 1152, 7, 7] 2,304
SiLU-189 [-1, 1152, 7, 7] 0
Conv2d-190 [-1, 1152, 7, 7] 28,800
BatchNorm2d-191 [-1, 1152, 7, 7] 2,304
SiLU-192 [-1, 1152, 7, 7] 0
AdaptiveAvgPool2d-193 [-1, 1152, 1, 1] 0
Conv2d-194 [-1, 48, 1, 1] 55,344
SiLU-195 [-1, 48, 1, 1] 0
Conv2d-196 [-1, 1152, 1, 1] 56,448
Sigmoid-197 [-1, 1152, 1, 1] 0
SqueezeExcitation-198 [-1, 1152, 7, 7] 0
Conv2d-199 [-1, 192, 7, 7] 221,184
BatchNorm2d-200 [-1, 192, 7, 7] 384
StochasticDepth-201 [-1, 192, 7, 7] 0
MBConv-202 [-1, 192, 7, 7] 0
Conv2d-203 [-1, 1152, 7, 7] 221,184
BatchNorm2d-204 [-1, 1152, 7, 7] 2,304
SiLU-205 [-1, 1152, 7, 7] 0
Conv2d-206 [-1, 1152, 7, 7] 28,800
BatchNorm2d-207 [-1, 1152, 7, 7] 2,304
SiLU-208 [-1, 1152, 7, 7] 0
AdaptiveAvgPool2d-209 [-1, 1152, 1, 1] 0
Conv2d-210 [-1, 48, 1, 1] 55,344
SiLU-211 [-1, 48, 1, 1] 0
Conv2d-212 [-1, 1152, 1, 1] 56,448
Sigmoid-213 [-1, 1152, 1, 1] 0
SqueezeExcitation-214 [-1, 1152, 7, 7] 0
Conv2d-215 [-1, 192, 7, 7] 221,184
BatchNorm2d-216 [-1, 192, 7, 7] 384
StochasticDepth-217 [-1, 192, 7, 7] 0
MBConv-218 [-1, 192, 7, 7] 0
Conv2d-219 [-1, 1152, 7, 7] 221,184
BatchNorm2d-220 [-1, 1152, 7, 7] 2,304
SiLU-221 [-1, 1152, 7, 7] 0
Conv2d-222 [-1, 1152, 7, 7] 28,800
BatchNorm2d-223 [-1, 1152, 7, 7] 2,304
SiLU-224 [-1, 1152, 7, 7] 0
AdaptiveAvgPool2d-225 [-1, 1152, 1, 1] 0
Conv2d-226 [-1, 48, 1, 1] 55,344
SiLU-227 [-1, 48, 1, 1] 0
Conv2d-228 [-1, 1152, 1, 1] 56,448
Sigmoid-229 [-1, 1152, 1, 1] 0
SqueezeExcitation-230 [-1, 1152, 7, 7] 0
Conv2d-231 [-1, 192, 7, 7] 221,184
BatchNorm2d-232 [-1, 192, 7, 7] 384
StochasticDepth-233 [-1, 192, 7, 7] 0
MBConv-234 [-1, 192, 7, 7] 0
Conv2d-235 [-1, 1152, 7, 7] 221,184
BatchNorm2d-236 [-1, 1152, 7, 7] 2,304
SiLU-237 [-1, 1152, 7, 7] 0
Conv2d-238 [-1, 1152, 7, 7] 10,368
BatchNorm2d-239 [-1, 1152, 7, 7] 2,304
SiLU-240 [-1, 1152, 7, 7] 0
AdaptiveAvgPool2d-241 [-1, 1152, 1, 1] 0
Conv2d-242 [-1, 48, 1, 1] 55,344
SiLU-243 [-1, 48, 1, 1] 0
Conv2d-244 [-1, 1152, 1, 1] 56,448
Sigmoid-245 [-1, 1152, 1, 1] 0
SqueezeExcitation-246 [-1, 1152, 7, 7] 0
Conv2d-247 [-1, 320, 7, 7] 368,640
BatchNorm2d-248 [-1, 320, 7, 7] 640
MBConv-249 [-1, 320, 7, 7] 0
Conv2d-250 [-1, 1280, 7, 7] 409,600
BatchNorm2d-251 [-1, 1280, 7, 7] 2,560
SiLU-252 [-1, 1280, 7, 7] 0
AdaptiveAvgPool2d-253 [-1, 1280, 1, 1] 0
Dropout-254 [-1, 1280] 0
Linear-255 [-1, 1000] 1,281,000
================================================================
Total params: 5,288,548
Trainable params: 5,288,548
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 173.65
Params size (MB): 20.17
Estimated Total Size (MB): 194.40
----------------------------------------------------------------
None
Если вы не знаете, какую модель выбрать, используйте EfficientNet.
Следущее лидерство было у архитектур, которые называются трансформер, с ними мы познакомимся в следующих лекциях. Одна из таких сетей — Vision Transformer.
Нам важно, что, как следует из текста статьи 🎓[arxiv], ViT, обученный на ImageNet, уступал baseline CNN-модели на базе сверточной сети (ResNet). И только при увеличении размера датасета больше, чем ImageNet, преимущество стало заметным.
Вряд ли в вашем распоряжении окажется датасет, сравнимый с JFT-300M 🛠️[doc] (300 миллионов изображений), и GPU/TPU ресурсы, необходимые для обучения с нуля (it could be trained using a standard cloud TPUv3 with 8 cores in approximately 30 days).
Поэтому для работы с пользовательскими данными используется техника дообучения ранее обученной модели на пользовательских данных (fine-tuning).
Авторы продемонстрировали, что сверточная сеть может превзойти трансформер и так же хорошо масштабироваться.
При этом особенных нововведений не потребовалось. Была проведена ревизия процесса обучения. И изменены некоторые параметры модели. За основу был взят обычный ResNet.
Ablation study (абляционное исследование) — это методология исследования, при которой удаляются (или изменяются) различные компоненты или элементы модели с целью оценить их вклад в ее производительность.
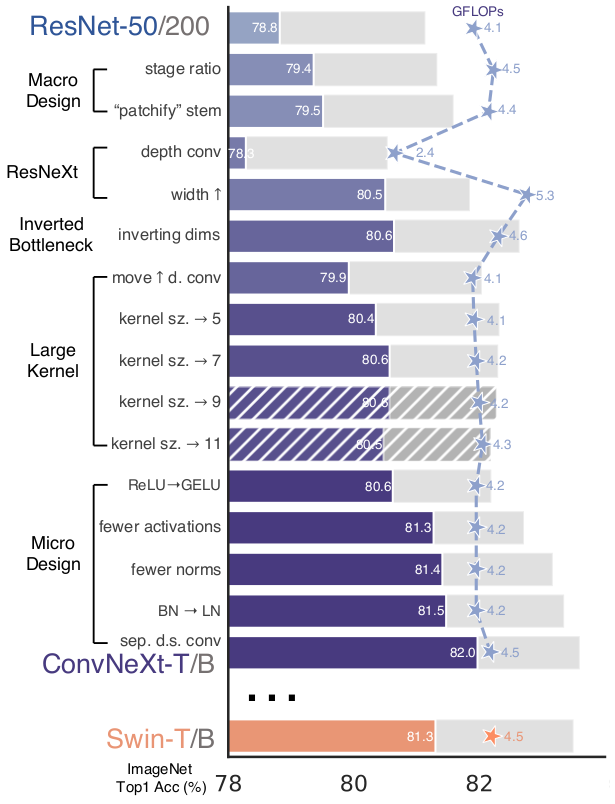
Macro Design:
Micro Design:
Использовали алгоритм обучения такой же, как у трансформера:
Библиотека timm 🛠️[doc] (полное название "PyTorch Image Models") — это набор предварительно обученных моделей для задач компьютерного зрения, разработанный для фреймворка PyTorch. TIMM предоставляет широкий спектр моделей, которые можно использовать для задач, таких как классификация изображений, сегментация, обнаружение объектов и другие задачи обработки изображений.
Основные особенности библиотеки:
Разнообразие моделей. Библиотека содержит различные архитектуры нейронных сетей, включая популярные модели, такие как ResNet, EfficientNet, ViT (Vision Transformer) и многие другие.
Предварительное обучение. Модели предварительно обучены на больших датасетах, таких как ImageNet, что позволяет использовать их как основу для различных задач компьютерного зрения с минимальной настройкой.
Простота использования. Удобный интерфейс для загрузки и использования моделей в PyTorch.
Гибкость. Возможность настраивать и адаптировать модели из библиотеки под свои конкретные задачи, добавлять и изменять слои и т. д.
!pip install -q timm
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.2/2.2 MB 12.3 MB/s eta 0:00:00
import torch
import random
import numpy as np
# fix random_seed
torch.manual_seed(42)
random.seed(42)
np.random.seed(42)
# compute in cpu or gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Для начала посмотрим, сколько моделей есть в библиотеке:
import timm
len(timm.list_models())
1017
Как видим, список довольно большой (все архитектуры со ссылками на статьи 🛠️[doc]). Можем указать параметры, чтобы сузить поиск. Например, посмотрим все предобученные EfficientNet:
timm.list_models("efficientnet*", pretrained=True)
['efficientnet_b0.ra_in1k', 'efficientnet_b1.ft_in1k', 'efficientnet_b1_pruned.in1k', 'efficientnet_b2.ra_in1k', 'efficientnet_b2_pruned.in1k', 'efficientnet_b3.ra2_in1k', 'efficientnet_b3_pruned.in1k', 'efficientnet_b4.ra2_in1k', 'efficientnet_b5.sw_in12k', 'efficientnet_b5.sw_in12k_ft_in1k', 'efficientnet_el.ra_in1k', 'efficientnet_el_pruned.in1k', 'efficientnet_em.ra2_in1k', 'efficientnet_es.ra_in1k', 'efficientnet_es_pruned.in1k', 'efficientnet_lite0.ra_in1k', 'efficientnetv2_rw_m.agc_in1k', 'efficientnetv2_rw_s.ra2_in1k', 'efficientnetv2_rw_t.ra2_in1k']
Как видим, моделей довольно много, можно ознакомиться с их качеством в этой таблице 🛠️[doc].
Загрузим одну из моделей:
model_name = "efficientnet_lite0.ra_in1k"
pretrained_model = timm.create_model(model_name, pretrained=True)
print(pretrained_model)
/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_token.py:88: UserWarning: The secret `HF_TOKEN` does not exist in your Colab secrets. To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session. You will be able to reuse this secret in all of your notebooks. Please note that authentication is recommended but still optional to access public models or datasets. warnings.warn(
model.safetensors: 0%| | 0.00/18.8M [00:00<?, ?B/s]
EfficientNet(
(conv_stem): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNormAct2d(
32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(blocks): Sequential(
(0): Sequential(
(0): DepthwiseSeparableConv(
(conv_dw): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn1): BatchNormAct2d(
32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pw): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNormAct2d(
16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(1): Sequential(
(0): InvertedResidual(
(conv_pw): Conv2d(16, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=96, bias=False)
(bn2): BatchNormAct2d(
96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(96, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(1): InvertedResidual(
(conv_pw): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(bn2): BatchNormAct2d(
144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(144, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(2): Sequential(
(0): InvertedResidual(
(conv_pw): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(144, 144, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=144, bias=False)
(bn2): BatchNormAct2d(
144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(144, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(1): InvertedResidual(
(conv_pw): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(240, 240, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=240, bias=False)
(bn2): BatchNormAct2d(
240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(240, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(3): Sequential(
(0): InvertedResidual(
(conv_pw): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(240, 240, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=240, bias=False)
(bn2): BatchNormAct2d(
240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(240, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(1): InvertedResidual(
(conv_pw): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(bn2): BatchNormAct2d(
480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(480, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(2): InvertedResidual(
(conv_pw): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(bn2): BatchNormAct2d(
480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(480, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(4): Sequential(
(0): InvertedResidual(
(conv_pw): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(480, 480, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=480, bias=False)
(bn2): BatchNormAct2d(
480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(480, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(1): InvertedResidual(
(conv_pw): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(672, 672, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(bn2): BatchNormAct2d(
672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(672, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(2): InvertedResidual(
(conv_pw): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(672, 672, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(bn2): BatchNormAct2d(
672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(672, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(5): Sequential(
(0): InvertedResidual(
(conv_pw): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(672, 672, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=672, bias=False)
(bn2): BatchNormAct2d(
672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(672, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(1): InvertedResidual(
(conv_pw): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(bn2): BatchNormAct2d(
1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(2): InvertedResidual(
(conv_pw): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(bn2): BatchNormAct2d(
1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(3): InvertedResidual(
(conv_pw): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(bn2): BatchNormAct2d(
1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(6): Sequential(
(0): InvertedResidual(
(conv_pw): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNormAct2d(
1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(bn2): BatchNormAct2d(
1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(1152, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNormAct2d(
320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
)
(conv_head): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNormAct2d(
1280, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
(drop): Identity()
(act): ReLU6(inplace=True)
)
(global_pool): SelectAdaptivePool2d(pool_type=avg, flatten=Flatten(start_dim=1, end_dim=-1))
(classifier): Linear(in_features=1280, out_features=1000, bias=True)
)
Если мы захотим применить модель в своей задаче, то, вероятно, нам потребуется заменить количество нейронов в последнем слое. Например, в случае с CIFAR-10 нам потребуется 10 выходов вместо 1000. Сделать это можно сразу при загрузке модели:
pretrained_model = timm.create_model(model_name, pretrained=True, num_classes=10)
pretrained_model.classifier
Linear(in_features=1280, out_features=10, bias=True)
Раньше мы делали это вручную:
pretrained_model.classifier = nn.Linear(1280, 10)
И эта возможность сохраняется. Мы по-прежнему можем изменить любой слой или блок слоев. Посмотрим, из каких верхнеуровневых компонентов состоит сеть:
layers = list(pretrained_model.children())
print("3 layer:", layers[3])
print("layers:", len(layers))
3 layer: Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1), bias=False) layers: 7
Изменим параметры, создав новый слой вместо старого:
new_layer = nn.Conv2d(in_channels=320, out_channels=512, kernel_size=(1, 1), bias=False)
layers[3] = new_layer
modified_model = nn.Sequential(*layers)
print("3 layer:", layers[3])
3 layer: Conv2d(320, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
В timm сеть разделена (условно) на две части: feature_extractor и classifier. Это позволяет использовать более гибкие методы работы. Получим классификационную часть методом get_classifier() (в нашем случае это один слой) и посмотрим, какие параметры на вход ожидает слой:
num_in_features = pretrained_model.get_classifier().in_features
num_in_features
1280
Теперь заменим слой на собственный классификационный блок:
pretrained_model.classifier = nn.Sequential(
nn.Linear(in_features=num_in_features, out_features=512, bias=False),
nn.ReLU(),
nn.BatchNorm1d(512),
nn.Dropout(0.4),
nn.Linear(in_features=512, out_features=10, bias=False),
)
pretrained_model.classifier
Sequential( (0): Linear(in_features=1280, out_features=512, bias=False) (1): ReLU() (2): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (3): Dropout(p=0.4, inplace=False) (4): Linear(in_features=512, out_features=10, bias=False) )
Мы также можем изменить количество входных каналов (параметр in_chans), и timm адаптирует слой для использования тензора с нужной размерностью:
pretrained_model_2 = timm.create_model(
model_name, pretrained=True, num_classes=10, in_chans=8
)
x = torch.rand(1, 8, 224, 224)
pretrained_model_2(x).shape
torch.Size([1, 10])
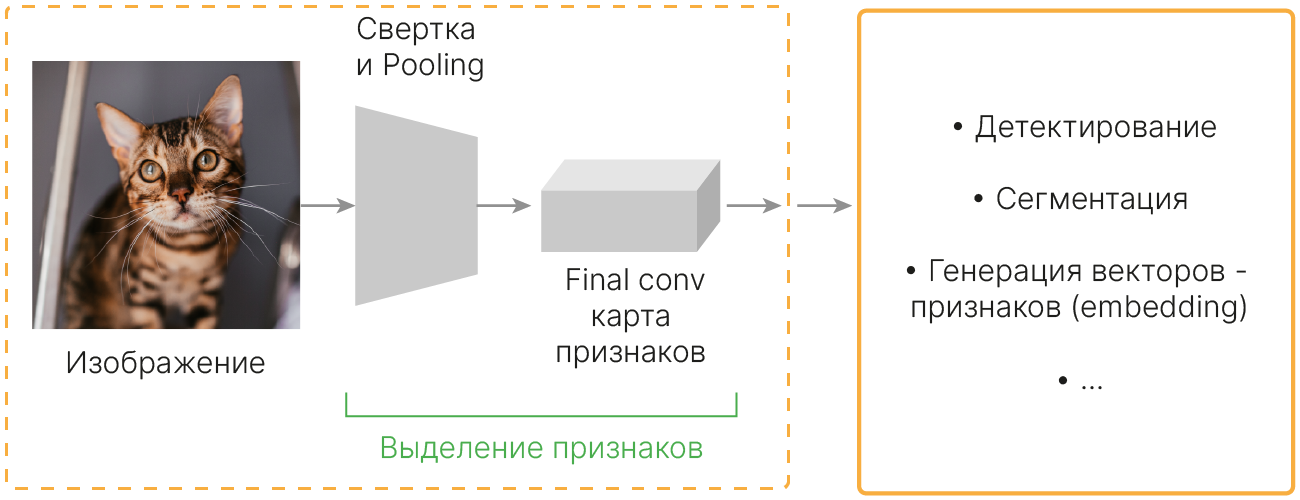
Разберемся теперь с feature_extractor. Используя методы из torchvision.models.feature_extraction, мы можем посмотреть граф модели с названиями элементов и получить output любого элемента. Тут есть некоторые особенности, с которыми можно ознакомиться в документации 🛠️[doc], но в общем случае это работает так:
output;feature_extractor с выбранным элементом.Построим граф и посмотрим, как он выглядит:
from torchvision.models.feature_extraction import get_graph_node_names
from warnings import simplefilter
simplefilter("ignore", UserWarning)
get_graph_node_names(pretrained_model)[0]
['x', 'conv_stem', 'bn1.getattr', 'bn1.eq', 'bn1.getattr_1', 'bn1._assert', 'bn1.bn1_weight', 'bn1.bn1_bias', 'bn1.batch_norm', 'bn1.drop', 'bn1.act', 'blocks.0.0.conv_dw', 'blocks.0.0.bn1.getattr', 'blocks.0.0.bn1.eq', 'blocks.0.0.bn1.getattr_1', 'blocks.0.0.bn1._assert', 'blocks.0.0.bn1.blocks_0_0_bn1_weight', 'blocks.0.0.bn1.blocks_0_0_bn1_bias', 'blocks.0.0.bn1.batch_norm', 'blocks.0.0.bn1.drop', 'blocks.0.0.bn1.act', 'blocks.0.0.se', 'blocks.0.0.conv_pw', 'blocks.0.0.bn2.getattr', 'blocks.0.0.bn2.eq', 'blocks.0.0.bn2.getattr_1', 'blocks.0.0.bn2._assert', 'blocks.0.0.bn2.blocks_0_0_bn2_weight', 'blocks.0.0.bn2.blocks_0_0_bn2_bias', 'blocks.0.0.bn2.batch_norm', 'blocks.0.0.bn2.drop', 'blocks.0.0.bn2.act', 'blocks.1.0.conv_pw', 'blocks.1.0.bn1.getattr', 'blocks.1.0.bn1.eq', 'blocks.1.0.bn1.getattr_1', 'blocks.1.0.bn1._assert', 'blocks.1.0.bn1.blocks_1_0_bn1_weight', 'blocks.1.0.bn1.blocks_1_0_bn1_bias', 'blocks.1.0.bn1.batch_norm', 'blocks.1.0.bn1.drop', 'blocks.1.0.bn1.act', 'blocks.1.0.conv_dw', 'blocks.1.0.bn2.getattr', 'blocks.1.0.bn2.eq', 'blocks.1.0.bn2.getattr_1', 'blocks.1.0.bn2._assert', 'blocks.1.0.bn2.blocks_1_0_bn2_weight', 'blocks.1.0.bn2.blocks_1_0_bn2_bias', 'blocks.1.0.bn2.batch_norm', 'blocks.1.0.bn2.drop', 'blocks.1.0.bn2.act', 'blocks.1.0.se', 'blocks.1.0.conv_pwl', 'blocks.1.0.bn3.getattr', 'blocks.1.0.bn3.eq', 'blocks.1.0.bn3.getattr_1', 'blocks.1.0.bn3._assert', 'blocks.1.0.bn3.blocks_1_0_bn3_weight', 'blocks.1.0.bn3.blocks_1_0_bn3_bias', 'blocks.1.0.bn3.batch_norm', 'blocks.1.0.bn3.drop', 'blocks.1.0.bn3.act', 'blocks.1.1.conv_pw', 'blocks.1.1.bn1.getattr', 'blocks.1.1.bn1.eq', 'blocks.1.1.bn1.getattr_1', 'blocks.1.1.bn1._assert', 'blocks.1.1.bn1.blocks_1_1_bn1_weight', 'blocks.1.1.bn1.blocks_1_1_bn1_bias', 'blocks.1.1.bn1.batch_norm', 'blocks.1.1.bn1.drop', 'blocks.1.1.bn1.act', 'blocks.1.1.conv_dw', 'blocks.1.1.bn2.getattr', 'blocks.1.1.bn2.eq', 'blocks.1.1.bn2.getattr_1', 'blocks.1.1.bn2._assert', 'blocks.1.1.bn2.blocks_1_1_bn2_weight', 'blocks.1.1.bn2.blocks_1_1_bn2_bias', 'blocks.1.1.bn2.batch_norm', 'blocks.1.1.bn2.drop', 'blocks.1.1.bn2.act', 'blocks.1.1.se', 'blocks.1.1.conv_pwl', 'blocks.1.1.bn3.getattr', 'blocks.1.1.bn3.eq', 'blocks.1.1.bn3.getattr_1', 'blocks.1.1.bn3._assert', 'blocks.1.1.bn3.blocks_1_1_bn3_weight', 'blocks.1.1.bn3.blocks_1_1_bn3_bias', 'blocks.1.1.bn3.batch_norm', 'blocks.1.1.bn3.drop', 'blocks.1.1.bn3.act', 'blocks.1.1.drop_path', 'blocks.1.1.add', 'blocks.2.0.conv_pw', 'blocks.2.0.bn1.getattr', 'blocks.2.0.bn1.eq', 'blocks.2.0.bn1.getattr_1', 'blocks.2.0.bn1._assert', 'blocks.2.0.bn1.blocks_2_0_bn1_weight', 'blocks.2.0.bn1.blocks_2_0_bn1_bias', 'blocks.2.0.bn1.batch_norm', 'blocks.2.0.bn1.drop', 'blocks.2.0.bn1.act', 'blocks.2.0.conv_dw', 'blocks.2.0.bn2.getattr', 'blocks.2.0.bn2.eq', 'blocks.2.0.bn2.getattr_1', 'blocks.2.0.bn2._assert', 'blocks.2.0.bn2.blocks_2_0_bn2_weight', 'blocks.2.0.bn2.blocks_2_0_bn2_bias', 'blocks.2.0.bn2.batch_norm', 'blocks.2.0.bn2.drop', 'blocks.2.0.bn2.act', 'blocks.2.0.se', 'blocks.2.0.conv_pwl', 'blocks.2.0.bn3.getattr', 'blocks.2.0.bn3.eq', 'blocks.2.0.bn3.getattr_1', 'blocks.2.0.bn3._assert', 'blocks.2.0.bn3.blocks_2_0_bn3_weight', 'blocks.2.0.bn3.blocks_2_0_bn3_bias', 'blocks.2.0.bn3.batch_norm', 'blocks.2.0.bn3.drop', 'blocks.2.0.bn3.act', 'blocks.2.1.conv_pw', 'blocks.2.1.bn1.getattr', 'blocks.2.1.bn1.eq', 'blocks.2.1.bn1.getattr_1', 'blocks.2.1.bn1._assert', 'blocks.2.1.bn1.blocks_2_1_bn1_weight', 'blocks.2.1.bn1.blocks_2_1_bn1_bias', 'blocks.2.1.bn1.batch_norm', 'blocks.2.1.bn1.drop', 'blocks.2.1.bn1.act', 'blocks.2.1.conv_dw', 'blocks.2.1.bn2.getattr', 'blocks.2.1.bn2.eq', 'blocks.2.1.bn2.getattr_1', 'blocks.2.1.bn2._assert', 'blocks.2.1.bn2.blocks_2_1_bn2_weight', 'blocks.2.1.bn2.blocks_2_1_bn2_bias', 'blocks.2.1.bn2.batch_norm', 'blocks.2.1.bn2.drop', 'blocks.2.1.bn2.act', 'blocks.2.1.se', 'blocks.2.1.conv_pwl', 'blocks.2.1.bn3.getattr', 'blocks.2.1.bn3.eq', 'blocks.2.1.bn3.getattr_1', 'blocks.2.1.bn3._assert', 'blocks.2.1.bn3.blocks_2_1_bn3_weight', 'blocks.2.1.bn3.blocks_2_1_bn3_bias', 'blocks.2.1.bn3.batch_norm', 'blocks.2.1.bn3.drop', 'blocks.2.1.bn3.act', 'blocks.2.1.drop_path', 'blocks.2.1.add', 'blocks.3.0.conv_pw', 'blocks.3.0.bn1.getattr', 'blocks.3.0.bn1.eq', 'blocks.3.0.bn1.getattr_1', 'blocks.3.0.bn1._assert', 'blocks.3.0.bn1.blocks_3_0_bn1_weight', 'blocks.3.0.bn1.blocks_3_0_bn1_bias', 'blocks.3.0.bn1.batch_norm', 'blocks.3.0.bn1.drop', 'blocks.3.0.bn1.act', 'blocks.3.0.conv_dw', 'blocks.3.0.bn2.getattr', 'blocks.3.0.bn2.eq', 'blocks.3.0.bn2.getattr_1', 'blocks.3.0.bn2._assert', 'blocks.3.0.bn2.blocks_3_0_bn2_weight', 'blocks.3.0.bn2.blocks_3_0_bn2_bias', 'blocks.3.0.bn2.batch_norm', 'blocks.3.0.bn2.drop', 'blocks.3.0.bn2.act', 'blocks.3.0.se', 'blocks.3.0.conv_pwl', 'blocks.3.0.bn3.getattr', 'blocks.3.0.bn3.eq', 'blocks.3.0.bn3.getattr_1', 'blocks.3.0.bn3._assert', 'blocks.3.0.bn3.blocks_3_0_bn3_weight', 'blocks.3.0.bn3.blocks_3_0_bn3_bias', 'blocks.3.0.bn3.batch_norm', 'blocks.3.0.bn3.drop', 'blocks.3.0.bn3.act', 'blocks.3.1.conv_pw', 'blocks.3.1.bn1.getattr', 'blocks.3.1.bn1.eq', 'blocks.3.1.bn1.getattr_1', 'blocks.3.1.bn1._assert', 'blocks.3.1.bn1.blocks_3_1_bn1_weight', 'blocks.3.1.bn1.blocks_3_1_bn1_bias', 'blocks.3.1.bn1.batch_norm', 'blocks.3.1.bn1.drop', 'blocks.3.1.bn1.act', 'blocks.3.1.conv_dw', 'blocks.3.1.bn2.getattr', 'blocks.3.1.bn2.eq', 'blocks.3.1.bn2.getattr_1', 'blocks.3.1.bn2._assert', 'blocks.3.1.bn2.blocks_3_1_bn2_weight', 'blocks.3.1.bn2.blocks_3_1_bn2_bias', 'blocks.3.1.bn2.batch_norm', 'blocks.3.1.bn2.drop', 'blocks.3.1.bn2.act', 'blocks.3.1.se', 'blocks.3.1.conv_pwl', 'blocks.3.1.bn3.getattr', 'blocks.3.1.bn3.eq', 'blocks.3.1.bn3.getattr_1', 'blocks.3.1.bn3._assert', 'blocks.3.1.bn3.blocks_3_1_bn3_weight', 'blocks.3.1.bn3.blocks_3_1_bn3_bias', 'blocks.3.1.bn3.batch_norm', 'blocks.3.1.bn3.drop', 'blocks.3.1.bn3.act', 'blocks.3.1.drop_path', 'blocks.3.1.add', 'blocks.3.2.conv_pw', 'blocks.3.2.bn1.getattr', 'blocks.3.2.bn1.eq', 'blocks.3.2.bn1.getattr_1', 'blocks.3.2.bn1._assert', 'blocks.3.2.bn1.blocks_3_2_bn1_weight', 'blocks.3.2.bn1.blocks_3_2_bn1_bias', 'blocks.3.2.bn1.batch_norm', 'blocks.3.2.bn1.drop', 'blocks.3.2.bn1.act', 'blocks.3.2.conv_dw', 'blocks.3.2.bn2.getattr', 'blocks.3.2.bn2.eq', 'blocks.3.2.bn2.getattr_1', 'blocks.3.2.bn2._assert', 'blocks.3.2.bn2.blocks_3_2_bn2_weight', 'blocks.3.2.bn2.blocks_3_2_bn2_bias', 'blocks.3.2.bn2.batch_norm', 'blocks.3.2.bn2.drop', 'blocks.3.2.bn2.act', 'blocks.3.2.se', 'blocks.3.2.conv_pwl', 'blocks.3.2.bn3.getattr', 'blocks.3.2.bn3.eq', 'blocks.3.2.bn3.getattr_1', 'blocks.3.2.bn3._assert', 'blocks.3.2.bn3.blocks_3_2_bn3_weight', 'blocks.3.2.bn3.blocks_3_2_bn3_bias', 'blocks.3.2.bn3.batch_norm', 'blocks.3.2.bn3.drop', 'blocks.3.2.bn3.act', 'blocks.3.2.drop_path', 'blocks.3.2.add', 'blocks.4.0.conv_pw', 'blocks.4.0.bn1.getattr', 'blocks.4.0.bn1.eq', 'blocks.4.0.bn1.getattr_1', 'blocks.4.0.bn1._assert', 'blocks.4.0.bn1.blocks_4_0_bn1_weight', 'blocks.4.0.bn1.blocks_4_0_bn1_bias', 'blocks.4.0.bn1.batch_norm', 'blocks.4.0.bn1.drop', 'blocks.4.0.bn1.act', 'blocks.4.0.conv_dw', 'blocks.4.0.bn2.getattr', 'blocks.4.0.bn2.eq', 'blocks.4.0.bn2.getattr_1', 'blocks.4.0.bn2._assert', 'blocks.4.0.bn2.blocks_4_0_bn2_weight', 'blocks.4.0.bn2.blocks_4_0_bn2_bias', 'blocks.4.0.bn2.batch_norm', 'blocks.4.0.bn2.drop', 'blocks.4.0.bn2.act', 'blocks.4.0.se', 'blocks.4.0.conv_pwl', 'blocks.4.0.bn3.getattr', 'blocks.4.0.bn3.eq', 'blocks.4.0.bn3.getattr_1', 'blocks.4.0.bn3._assert', 'blocks.4.0.bn3.blocks_4_0_bn3_weight', 'blocks.4.0.bn3.blocks_4_0_bn3_bias', 'blocks.4.0.bn3.batch_norm', 'blocks.4.0.bn3.drop', 'blocks.4.0.bn3.act', 'blocks.4.1.conv_pw', 'blocks.4.1.bn1.getattr', 'blocks.4.1.bn1.eq', 'blocks.4.1.bn1.getattr_1', 'blocks.4.1.bn1._assert', 'blocks.4.1.bn1.blocks_4_1_bn1_weight', 'blocks.4.1.bn1.blocks_4_1_bn1_bias', 'blocks.4.1.bn1.batch_norm', 'blocks.4.1.bn1.drop', 'blocks.4.1.bn1.act', 'blocks.4.1.conv_dw', 'blocks.4.1.bn2.getattr', 'blocks.4.1.bn2.eq', 'blocks.4.1.bn2.getattr_1', 'blocks.4.1.bn2._assert', 'blocks.4.1.bn2.blocks_4_1_bn2_weight', 'blocks.4.1.bn2.blocks_4_1_bn2_bias', 'blocks.4.1.bn2.batch_norm', 'blocks.4.1.bn2.drop', 'blocks.4.1.bn2.act', 'blocks.4.1.se', 'blocks.4.1.conv_pwl', 'blocks.4.1.bn3.getattr', 'blocks.4.1.bn3.eq', 'blocks.4.1.bn3.getattr_1', 'blocks.4.1.bn3._assert', 'blocks.4.1.bn3.blocks_4_1_bn3_weight', 'blocks.4.1.bn3.blocks_4_1_bn3_bias', 'blocks.4.1.bn3.batch_norm', 'blocks.4.1.bn3.drop', 'blocks.4.1.bn3.act', 'blocks.4.1.drop_path', 'blocks.4.1.add', 'blocks.4.2.conv_pw', 'blocks.4.2.bn1.getattr', 'blocks.4.2.bn1.eq', 'blocks.4.2.bn1.getattr_1', 'blocks.4.2.bn1._assert', 'blocks.4.2.bn1.blocks_4_2_bn1_weight', 'blocks.4.2.bn1.blocks_4_2_bn1_bias', 'blocks.4.2.bn1.batch_norm', 'blocks.4.2.bn1.drop', 'blocks.4.2.bn1.act', 'blocks.4.2.conv_dw', 'blocks.4.2.bn2.getattr', 'blocks.4.2.bn2.eq', 'blocks.4.2.bn2.getattr_1', 'blocks.4.2.bn2._assert', 'blocks.4.2.bn2.blocks_4_2_bn2_weight', 'blocks.4.2.bn2.blocks_4_2_bn2_bias', 'blocks.4.2.bn2.batch_norm', 'blocks.4.2.bn2.drop', 'blocks.4.2.bn2.act', 'blocks.4.2.se', 'blocks.4.2.conv_pwl', 'blocks.4.2.bn3.getattr', 'blocks.4.2.bn3.eq', 'blocks.4.2.bn3.getattr_1', 'blocks.4.2.bn3._assert', 'blocks.4.2.bn3.blocks_4_2_bn3_weight', 'blocks.4.2.bn3.blocks_4_2_bn3_bias', 'blocks.4.2.bn3.batch_norm', 'blocks.4.2.bn3.drop', 'blocks.4.2.bn3.act', 'blocks.4.2.drop_path', 'blocks.4.2.add', 'blocks.5.0.conv_pw', 'blocks.5.0.bn1.getattr', 'blocks.5.0.bn1.eq', 'blocks.5.0.bn1.getattr_1', 'blocks.5.0.bn1._assert', 'blocks.5.0.bn1.blocks_5_0_bn1_weight', 'blocks.5.0.bn1.blocks_5_0_bn1_bias', 'blocks.5.0.bn1.batch_norm', 'blocks.5.0.bn1.drop', 'blocks.5.0.bn1.act', 'blocks.5.0.conv_dw', 'blocks.5.0.bn2.getattr', 'blocks.5.0.bn2.eq', 'blocks.5.0.bn2.getattr_1', 'blocks.5.0.bn2._assert', 'blocks.5.0.bn2.blocks_5_0_bn2_weight', 'blocks.5.0.bn2.blocks_5_0_bn2_bias', 'blocks.5.0.bn2.batch_norm', 'blocks.5.0.bn2.drop', 'blocks.5.0.bn2.act', 'blocks.5.0.se', 'blocks.5.0.conv_pwl', 'blocks.5.0.bn3.getattr', 'blocks.5.0.bn3.eq', 'blocks.5.0.bn3.getattr_1', 'blocks.5.0.bn3._assert', 'blocks.5.0.bn3.blocks_5_0_bn3_weight', 'blocks.5.0.bn3.blocks_5_0_bn3_bias', 'blocks.5.0.bn3.batch_norm', 'blocks.5.0.bn3.drop', 'blocks.5.0.bn3.act', 'blocks.5.1.conv_pw', 'blocks.5.1.bn1.getattr', 'blocks.5.1.bn1.eq', 'blocks.5.1.bn1.getattr_1', 'blocks.5.1.bn1._assert', 'blocks.5.1.bn1.blocks_5_1_bn1_weight', 'blocks.5.1.bn1.blocks_5_1_bn1_bias', 'blocks.5.1.bn1.batch_norm', 'blocks.5.1.bn1.drop', 'blocks.5.1.bn1.act', 'blocks.5.1.conv_dw', 'blocks.5.1.bn2.getattr', 'blocks.5.1.bn2.eq', 'blocks.5.1.bn2.getattr_1', 'blocks.5.1.bn2._assert', 'blocks.5.1.bn2.blocks_5_1_bn2_weight', 'blocks.5.1.bn2.blocks_5_1_bn2_bias', 'blocks.5.1.bn2.batch_norm', 'blocks.5.1.bn2.drop', 'blocks.5.1.bn2.act', 'blocks.5.1.se', 'blocks.5.1.conv_pwl', 'blocks.5.1.bn3.getattr', 'blocks.5.1.bn3.eq', 'blocks.5.1.bn3.getattr_1', 'blocks.5.1.bn3._assert', 'blocks.5.1.bn3.blocks_5_1_bn3_weight', 'blocks.5.1.bn3.blocks_5_1_bn3_bias', 'blocks.5.1.bn3.batch_norm', 'blocks.5.1.bn3.drop', 'blocks.5.1.bn3.act', 'blocks.5.1.drop_path', 'blocks.5.1.add', 'blocks.5.2.conv_pw', 'blocks.5.2.bn1.getattr', 'blocks.5.2.bn1.eq', 'blocks.5.2.bn1.getattr_1', 'blocks.5.2.bn1._assert', 'blocks.5.2.bn1.blocks_5_2_bn1_weight', 'blocks.5.2.bn1.blocks_5_2_bn1_bias', 'blocks.5.2.bn1.batch_norm', 'blocks.5.2.bn1.drop', 'blocks.5.2.bn1.act', 'blocks.5.2.conv_dw', 'blocks.5.2.bn2.getattr', 'blocks.5.2.bn2.eq', 'blocks.5.2.bn2.getattr_1', 'blocks.5.2.bn2._assert', 'blocks.5.2.bn2.blocks_5_2_bn2_weight', 'blocks.5.2.bn2.blocks_5_2_bn2_bias', 'blocks.5.2.bn2.batch_norm', 'blocks.5.2.bn2.drop', 'blocks.5.2.bn2.act', 'blocks.5.2.se', 'blocks.5.2.conv_pwl', 'blocks.5.2.bn3.getattr', 'blocks.5.2.bn3.eq', 'blocks.5.2.bn3.getattr_1', 'blocks.5.2.bn3._assert', 'blocks.5.2.bn3.blocks_5_2_bn3_weight', 'blocks.5.2.bn3.blocks_5_2_bn3_bias', 'blocks.5.2.bn3.batch_norm', 'blocks.5.2.bn3.drop', 'blocks.5.2.bn3.act', 'blocks.5.2.drop_path', 'blocks.5.2.add', 'blocks.5.3.conv_pw', 'blocks.5.3.bn1.getattr', 'blocks.5.3.bn1.eq', 'blocks.5.3.bn1.getattr_1', 'blocks.5.3.bn1._assert', 'blocks.5.3.bn1.blocks_5_3_bn1_weight', 'blocks.5.3.bn1.blocks_5_3_bn1_bias', 'blocks.5.3.bn1.batch_norm', 'blocks.5.3.bn1.drop', 'blocks.5.3.bn1.act', 'blocks.5.3.conv_dw', 'blocks.5.3.bn2.getattr', 'blocks.5.3.bn2.eq', 'blocks.5.3.bn2.getattr_1', 'blocks.5.3.bn2._assert', 'blocks.5.3.bn2.blocks_5_3_bn2_weight', 'blocks.5.3.bn2.blocks_5_3_bn2_bias', 'blocks.5.3.bn2.batch_norm', 'blocks.5.3.bn2.drop', 'blocks.5.3.bn2.act', 'blocks.5.3.se', 'blocks.5.3.conv_pwl', 'blocks.5.3.bn3.getattr', 'blocks.5.3.bn3.eq', 'blocks.5.3.bn3.getattr_1', 'blocks.5.3.bn3._assert', 'blocks.5.3.bn3.blocks_5_3_bn3_weight', 'blocks.5.3.bn3.blocks_5_3_bn3_bias', 'blocks.5.3.bn3.batch_norm', 'blocks.5.3.bn3.drop', 'blocks.5.3.bn3.act', 'blocks.5.3.drop_path', 'blocks.5.3.add', 'blocks.6.0.conv_pw', 'blocks.6.0.bn1.getattr', 'blocks.6.0.bn1.eq', 'blocks.6.0.bn1.getattr_1', 'blocks.6.0.bn1._assert', 'blocks.6.0.bn1.blocks_6_0_bn1_weight', 'blocks.6.0.bn1.blocks_6_0_bn1_bias', 'blocks.6.0.bn1.batch_norm', 'blocks.6.0.bn1.drop', 'blocks.6.0.bn1.act', 'blocks.6.0.conv_dw', 'blocks.6.0.bn2.getattr', 'blocks.6.0.bn2.eq', 'blocks.6.0.bn2.getattr_1', 'blocks.6.0.bn2._assert', 'blocks.6.0.bn2.blocks_6_0_bn2_weight', 'blocks.6.0.bn2.blocks_6_0_bn2_bias', 'blocks.6.0.bn2.batch_norm', 'blocks.6.0.bn2.drop', 'blocks.6.0.bn2.act', 'blocks.6.0.se', 'blocks.6.0.conv_pwl', 'blocks.6.0.bn3.getattr', 'blocks.6.0.bn3.eq', 'blocks.6.0.bn3.getattr_1', 'blocks.6.0.bn3._assert', 'blocks.6.0.bn3.blocks_6_0_bn3_weight', 'blocks.6.0.bn3.blocks_6_0_bn3_bias', 'blocks.6.0.bn3.batch_norm', 'blocks.6.0.bn3.drop', 'blocks.6.0.bn3.act', 'conv_head', 'bn2.getattr', 'bn2.eq', 'bn2.getattr_1', 'bn2._assert', 'bn2.bn2_weight', 'bn2.bn2_bias', 'bn2.batch_norm', 'bn2.drop', 'bn2.act', 'global_pool.pool', 'global_pool.flatten', 'classifier.0', 'classifier.1', 'classifier.2', 'classifier.3', 'classifier.4']
Для демонстрации возьмем output с первого слоя в нашем классификационном блоке:
from torchvision.models.feature_extraction import create_feature_extractor
features = {"classifier.0": "out"}
custom_fe = create_feature_extractor(pretrained_model, return_nodes=features)
custom_fe
EfficientNet(
(conv_stem): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(blocks): Module(
(0): Module(
(0): Module(
(conv_dw): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pw): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): Module(
(drop): Identity()
(act): Identity()
)
)
)
(1): Module(
(0): Module(
(conv_pw): Conv2d(16, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=96, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(96, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
)
(1): Module(
(conv_pw): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(144, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(2): Module(
(0): Module(
(conv_pw): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(144, 144, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=144, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(144, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
)
(1): Module(
(conv_pw): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(240, 240, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=240, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(240, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(3): Module(
(0): Module(
(conv_pw): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(240, 240, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=240, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(240, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
)
(1): Module(
(conv_pw): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(480, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(2): Module(
(conv_pw): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(480, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(4): Module(
(0): Module(
(conv_pw): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(480, 480, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=480, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(480, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
)
(1): Module(
(conv_pw): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(672, 672, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(672, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(2): Module(
(conv_pw): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(672, 672, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(672, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(5): Module(
(0): Module(
(conv_pw): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(672, 672, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=672, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(672, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
)
(1): Module(
(conv_pw): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(2): Module(
(conv_pw): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
(3): Module(
(conv_pw): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
(drop_path): Identity()
)
)
(6): Module(
(0): Module(
(conv_pw): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(conv_dw): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(se): Identity()
(conv_pwl): Conv2d(1152, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): Module(
(drop): Identity()
(act): Identity()
)
)
)
)
(conv_head): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): Module(
(drop): Identity()
(act): ReLU6(inplace=True)
)
(global_pool): Module(
(pool): AdaptiveAvgPool2d(output_size=1)
(flatten): Flatten(start_dim=1, end_dim=-1)
)
(classifier): Module(
(0): Linear(in_features=1280, out_features=512, bias=False)
)
)
x = torch.rand(1, 3, 224, 224)
custom_fe(x)["out"].shape
torch.Size([1, 512])
Другой, более верхнеуровневый способ — это использовать модель в режиме features_only. Загрузим модель:
fe_model = timm.create_model(model_name, pretrained=True, features_only=True)
Посмотрим параметры блоков:
list(fe_model.feature_info)
[{'stage': 1, 'reduction': 2, 'module': 'blocks.0', 'num_chs': 16, 'index': 0},
{'stage': 2, 'reduction': 4, 'module': 'blocks.1', 'num_chs': 24, 'index': 1},
{'stage': 3, 'reduction': 8, 'module': 'blocks.2', 'num_chs': 40, 'index': 2},
{'stage': 5,
'reduction': 16,
'module': 'blocks.4',
'num_chs': 112,
'index': 3},
{'stage': 7,
'reduction': 32,
'module': 'blocks.6',
'num_chs': 320,
'index': 4}]
Получим все карты признаков из этих блоков:
out = fe_model(x)
for output in out:
print(output.shape)
torch.Size([1, 16, 112, 112]) torch.Size([1, 24, 56, 56]) torch.Size([1, 40, 28, 28]) torch.Size([1, 112, 14, 14]) torch.Size([1, 320, 7, 7])
При использовании предобученной модели важно знать, как и на каких данных она обучалась. В частности нас могут интересовать примененные аугментации (transform).
В timm каждая модель содержит описание своей конфигурации default_cfg (без обучения) и pretrained_cfg (предобученная). Посмотрим на pretrained_cfg:
pretrained_model.pretrained_cfg
{'url': 'https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_lite0_ra-37913777.pth',
'hf_hub_id': 'timm/efficientnet_lite0.ra_in1k',
'architecture': 'efficientnet_lite0',
'tag': 'ra_in1k',
'custom_load': False,
'input_size': (3, 224, 224),
'fixed_input_size': False,
'interpolation': 'bicubic',
'crop_pct': 0.875,
'crop_mode': 'center',
'mean': (0.485, 0.456, 0.406),
'std': (0.229, 0.224, 0.225),
'num_classes': 1000,
'pool_size': (7, 7),
'first_conv': 'conv_stem',
'classifier': 'classifier'}
Создадим transform:
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
transform = create_transform(
**resolve_data_config(pretrained_model.pretrained_cfg, model=pretrained_model)
)
transform
Compose(
Resize(size=256, interpolation=bicubic, max_size=None, antialias=warn)
CenterCrop(size=(224, 224))
ToTensor()
Normalize(mean=tensor([0.4850, 0.4560, 0.4060]), std=tensor([0.2290, 0.2240, 0.2250]))
)
Мы кратко познакомились с библиотекой timm. Возможностей у нее гораздо больше, но в рамках лекции мы никак не успеем с ними познакомиться.
Рекомендуем для самостоятельного изучения:
Все перечисленные выше модели учились при помощи классического обучения с учителем: на размеченных данных из ImageNet.
Однако данных как в открытом, так и закрытом доступе с каждым годом становится все больше. Логично предположить, что из этих данных можно извлечь дополнительную информацию, которая поможет лучше классифицировать старый добрый ImageNet.
Модели и алгоритмы, о которых пойдет речь дальше, тем или иным образом используют эти внешние данные.
Knowledge distillation 📚[wiki] — техника, которая используется для обучения одной модели маленькой (student) при помощи другой большой (teacher).
Представим, что у нас нет больше доступа к ImageNet, но на диске осталась модель, которую на нем учили, например EfficientNet B7 🛠️[doc]. Модель большая и точная, а нам нужно решить некоторую простую задачу, например, отличать котов от собак. Но делать это на мобильном устройстве и очень быстро.
Можно воспользоваться большой моделью, и с ее помощью разметить имеющиеся неразмеченные изображения, а затем на этих данных учить маленькую и быструю модель.
Подход, описанный выше, будет работать, но можно поступить и хитрее.
Предположим, большая сеть классифицирует MNIST, и для цифры:
мы получили вот такой вектор логитов:
from matplotlib import pyplot as plt
logits = [0.1, 0.1, 0.4, 5, 0.1, 0.2, 0.1, 0.2, 3, 0.7]
plt.figure(figsize=(6, 3))
plt.bar(range(0, 10), logits)
plt.xticks(range(0, 10))
plt.show()

Самый большой логит у тройки, что верно. Но и у восьмерки он большой, так как эти цифры похожи.

То есть логиты содержат дополнительную полезную информацию.
Когда мы превратим их в вероятности, она сохранится.
import torch
from torch.nn.functional import softmax
probs = softmax(torch.tensor(logits), dim=0)
plt.figure(figsize=(6, 3))
plt.bar(range(0, 10), probs)
plt.xticks(range(0, 10))
plt.show()

А вот после того, как мы превратим вектор вероятностей в метку (one_hot вектор), эта дополнительная информация пропадет при округлении.
one_hot = (probs >= probs.max()).int()
print("One hot ", one_hot)
One hot tensor([0, 0, 0, 1, 0, 0, 0, 0, 0, 0], dtype=torch.int32)
import numpy as np
f, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(15, 4), sharey=False)
def bar(ax, y, title):
x = range(0, 10)
ax.bar(x, np.array(y))
ax.set_title(title)
ax.set_yticks([])
bar(ax1, logits, "Logits")
bar(ax2, probs, "Probs")
bar(ax3, one_hot, "Label")
plt.plot()
plt.show()

Чтобы не терять информацию, можно предсказывать не метку, а весь вектор вероятностей, который получается на выходе большой модели.
Contrastive Language-Image Pre-training
Для обучения модели был создан новый датасет, включающий 400M пар изображение–текст.
Для использования в качестве классификатора достаточно создать текстовый эмбеддинг для слова, описывающего каждый класс, а затем сравнить его с эмбеддингом изображения.
Точность классификации не дотягивает до SOTA supervised моделей, но зато работает без дообучения на различных датасетах.
Установка:
!pip install -q git+https://github.com/openai/CLIP.git
Preparing metadata (setup.py) ... done
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 53.4/53.4 kB 1.9 MB/s eta 0:00:00
Building wheel for clip (setup.py) ... done
img, class_num = microImgNet[200]
show(img, microImgNet.labels[200][1], 0)

На вход CLIP надо подать список текстов, на выходе получим оценку того, какой из них больше всего подходит к изображению.
texts = [
"A man with a gasoline saw is getting firewood",
"Santa Claus sleigh",
"chain saw",
"cat",
"dog",
]
Можно использовать разные backbone:
import clip
print(clip.available_models())
['RN50', 'RN101', 'RN50x4', 'RN50x16', 'RN50x64', 'ViT-B/32', 'ViT-B/16', 'ViT-L/14', 'ViT-L/14@336px']
Создаем экземпляр модели:
model, preprocess = clip.load("ViT-B/32", device="cpu")
100%|███████████████████████████████████████| 338M/338M [00:03<00:00, 95.9MiB/s]
Дополнительно получили объект preprocess с необходимыми трансформациями. Подготовим с их помощью изображение и токенизируем текст:
image = preprocess(img).unsqueeze(0)
text = clip.tokenize(texts)
Теперь можно запускать
Given a batch of images and a batch of text tokens, returns two Tensors, containing the logit scores corresponding to each image and text input. The values are cosine similarities between the corresponding image and text features, times 100.
with torch.no_grad():
logits_per_image, _ = model(image, text)
probs = logits_per_image.softmax(dim=-1).numpy()
print(probs)
plt.figure(figsize=(6, 3))
plt.bar(range(len(texts)), probs.flatten())
plt.show()
[[9.912793e-01 5.492549e-06 8.714993e-03 5.615143e-08 2.927707e-07]]

Вот так можно извлечь признаки для картинки и для текста:
image_features = model.encode_image(image).detach().cpu()
text_features = model.encode_text(text).detach().cpu()
print("Image", image_features.shape)
print("Text", text_features.shape)
Image torch.Size([1, 512]) Text torch.Size([5, 512])
Чтобы сравнить вектора признаков изображений и текстов, нам нужна какая-то метрика расстояния между ними. Удобно использовать косинусное расстояние 📚[wiki]:
$ \large \text{cosine_similarity} = \cos(\theta) = \dfrac{a \cdot b }{|a||b|} $
Если вектора имеют единичную длину, то косинус угла между ними равен скалярному произведению :
$\large \text{cosine_similarity} = a \cdot b $
Эмбеддинги на выходе CLIP не нормализованы:
print(np.linalg.norm(image_features[0]))
10.169521
Нормализуем их:
from torch.nn.functional import normalize
image_features = normalize(image_features)
text_features = normalize(text_features)
print(np.linalg.norm(image_features[0].cpu()))
print(np.linalg.norm(text_features.cpu(), axis=1))
0.99999994 [1. 1.0000001 1. 1. 1.0000001]
Теперь мы можем посчитать скалярное произведение вектора признаков для каждого текста с картинкой и понять, насколько они похожи:
similarities = []
for t in text_features:
sim = torch.dot(image_features[0], t)
similarities.append(sim.item())
print(similarities)
[0.3043335974216461, 0.18330000340938568, 0.2569941282272339, 0.1374690979719162, 0.15398246049880981]
Аналогичный результат получится при матричном умножении признаков:
sims = torch.matmul(text_features, image_features.T)
print(sims.detach().cpu().tolist())
[[0.3043336272239685], [0.18330001831054688], [0.2569941580295563], [0.137469083070755], [0.15398246049880981]]
Разрыв уже не такой внушительный, как после softmax:
plt.figure(figsize=(6, 3))
plt.bar(range(len(similarities)), similarities)
plt.show()

Но можно умножить расстояния на константу перед отправкой в softmax:
chilled_sims = sims.flatten() * 100
И тогда результат совпадет с тем, что выдал CLIP:
s = chilled_sims.softmax(dim=0).numpy()
print(s)
plt.figure(figsize=(8, 6))
plt.bar(range(len(s)), s)
plt.show()
[9.912793e-01 5.492538e-06 8.715026e-03 5.615143e-08 2.927707e-07]

Создадим из названий классов простые текстовые описания и напечатаем 10 штук для примера:
descriptions = []
for val in imagenet_labels.values():
name = val[1].replace("_", " ")
descriptions.append(f"a photo of {name}")
print(descriptions[0:10])
['a photo of tench', 'a photo of goldfish', 'a photo of great white shark', 'a photo of tiger shark', 'a photo of hammerhead', 'a photo of electric ray', 'a photo of stingray', 'a photo of cock', 'a photo of hen', 'a photo of ostrich']
import clip
img, label = microImgNet[0]
model, preprocess = clip.load("ViT-B/32", device=device)
for i in range(6):
img, label = microImgNet[i * 6]
name = microImgNet.labels[i * 6][1]
image = preprocess(img).unsqueeze(0).to(device)
text = clip.tokenize(descriptions).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
class_num = probs.argmax()
descr = descriptions[class_num]
show(img, descr, i)

Литература
AlexNet:
ZFNet:
VGG:
GoogLeNet:
Global Average Pooling:
ResNet:
Fixup Initialization:
ResNeXt:
DenseNet:
WideResNet:
SENet:
MobileNet:
EfficientNet:
Visual Transformer:
Дополнительно: