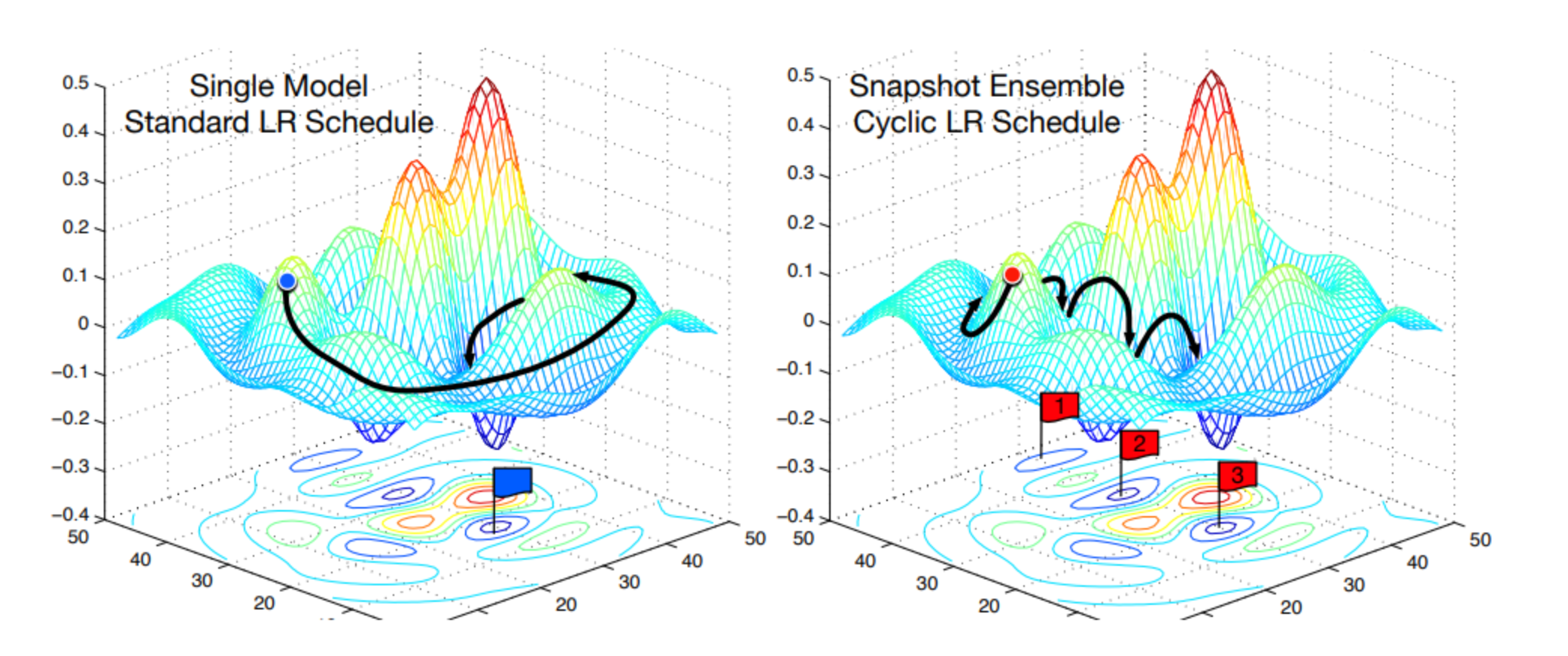
Улучшение сходимости нейросетей и борьба с переобучением
В предыдущих лекциях мы познакомились с теоремой о нейронной сети в качестве универсального аппроксиматора 🥨[colab] и теми преимуществами, которые может дать использование глубоких нейронных сетей. Кроме того, мы познакомились с алгоритмом стохастического градиентного спуска 🥨[colab], при помощи которого мы можем обучать нейронные сети решать интересующие нас задачи. К сожалению, описанный нами ранее подход в обучении глубоких сетей является не полным и на практике редко приводит к успешному решению.
В этой лекции мы продемонстрируем модельный пример такой проблемы с обучением глубокой сети и последовательно рассмотрим ряд идей, которые позволят её исправить.
Код для визуализации результатов обучения моделей:
def exponential_smoothing(scalars, weight):
last = scalars[0]
smoothed = []
for point in scalars:
smoothed_val = last * weight + (1 - weight) * point
smoothed.append(smoothed_val)
last = smoothed_val
return smoothed
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
class HistoryPlotter:
def __init__(self):
# dict for safe learning history
self._history_dict = {}
def add(self, history):
"""
Save learning history.
history: dict with keys: model_name, epoсhs, loss_on_train, loss_on_test
"""
self._history_dict[history["model_name"]] = history
self.color_list = list(mcolors.TABLEAU_COLORS.keys())
def plot(self, models, show_smooth=True, smooth_val=0.90):
"""
Plot informatiom from self._history_dict.
models: list of model_name (len <= 5, or extend color_list)
"""
fig, ax = plt.subplots(3, 1, figsize=(10, 10))
for model_num, model_name in enumerate(models):
history = self._history_dict[model_name]
for idx, (key, title) in enumerate(
zip(["loss_on_train", "loss_on_test"], ["train loss", "test loss"])
):
epoch_len = len(history[key]) // history["epoсhs"]
loss_len = len(history[key])
ticks_positions = np.arange(history["epoсhs"] + 1)
if show_smooth:
x = np.arange(len(history[key])) / epoch_len
# Plot train loss and test loss:
# 1. plot smoothing vals
ax[idx].plot(
x,
exponential_smoothing(history[key], smooth_val),
label=model_name + " smoothed",
color=self.color_list[2 * model_num + idx],
)
# 2. plot raw vals
ax[idx].plot(
x,
history[key],
label=model_name + " raw",
alpha=0.2,
color=self.color_list[2 * model_num + idx],
)
# 3. add descriptions if it is nesessary
if not ax[idx].title.get_text():
ax[idx].set_title(title)
ax[idx].set_xlabel("epochs")
ax[idx].set_ylabel("loss")
ax[idx].set_xticks(ticks_positions)
ax[idx].set_xticklabels(np.arange(history["epoсhs"] + 1))
ax[idx].legend()
# Plot mean train and test loss combined:
# 1. calculate mean and std
mean_loss_on_epoch = [
np.mean(history[key][i : i + epoch_len])
for i in range(0, loss_len, epoch_len)
]
std_loss_on_epoch = [
np.std(history[key][i : i + epoch_len])
for i in range(0, loss_len, epoch_len)
]
# 2. plot
ax[2].errorbar(
np.arange(history["epoсhs"]) + idx / 30.0,
mean_loss_on_epoch,
yerr=std_loss_on_epoch,
capsize=5,
fmt="X--",
label=model_name + " " + title,
)
# 3. add descriptions if it is necessary
if not ax[2].title.get_text():
ax[2].set_title("\nAverage loss per epoch", {"fontsize": 12})
ax[2].set_xticks(np.arange(history["epoсhs"]))
ax[2].set_xticklabels(np.arange(history["epoсhs"]))
ax[2].set_xlabel("epochs")
ax[2].set_ylabel("loss")
ax[2].legend()
plt.subplots_adjust(hspace=0.4)
plt.show()
history_plotter = HistoryPlotter()
Загрузим данные, создадим сеть, обучим ее и посмотрим на практике, как проходит обучение.
Загрузим датасет MNIST:
import torchvision
import torchvision.transforms as transforms
from IPython.display import clear_output
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
# transforms for data
transform = torchvision.transforms.Compose(
[torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.13), (0.3))]
)
train_set = MNIST(root="./MNIST", train=True, download=True, transform=transform)
test_set = MNIST(root="./MNIST", train=False, download=True, transform=transform)
batch_size = 32
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=2)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=2)
clear_output()
print("Already downloaded!")
Already downloaded!
Создадим сеть с сигмоидой в качестве функции активации:
import torch.nn as nn
class SimpleMNIST_NN(nn.Module):
def __init__(self, n_layers, activation=nn.Sigmoid):
super().__init__()
self.n_layers = n_layers # Num of layers
self.activation = activation()
layers = [nn.Linear(28 * 28, 100), self.activation] # input layer
for _ in range(n_layers - 1): # append num of layers
layers.append(nn.Linear(100, 100))
layers.append(self.activation)
layers.append(nn.Linear(100, 10)) # 10 classes
self.layers = nn.Sequential(*layers)
def forward(self, x):
x = x.view(-1, 28 * 28) # reshape to [-1, 784]
x = self.layers(x)
return x
Реализуем пайплан обучения модели на Lightning:
!pip install -q pytorch-lightning tbparse
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 801.9/801.9 kB 8.0 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 841.5/841.5 kB 14.3 MB/s eta 0:00:00
import torch
import pytorch_lightning as pl
class Pipeline(pl.LightningModule):
def __init__(
self,
model,
exp_name="baseline",
criterion=nn.CrossEntropyLoss(),
optimizer_class=torch.optim.SGD,
optimizer_kwargs={"lr": 0.001},
) -> None:
super().__init__()
self.model = model
self.criterion = criterion
self.optimizer_class = optimizer_class
self.optimizer_kwargs = optimizer_kwargs
# Additionally, we will save training logs “manually”
# for visualization within the lecture. Please limit yourself
# to the native training logging tools from PytorchLightning
# when training your own models.
self.history = {"loss_on_train": [], "loss_on_test": [], "model_name": exp_name}
def configure_optimizers(self):
optimizer = self.optimizer_class(
self.model.parameters(), **self.optimizer_kwargs
)
return optimizer
def training_step(self, batch, batch_idx):
x, y = batch
out = self.model(x)
loss = self.criterion(out, y)
self.log("loss_on_train", loss, prog_bar=True)
# aux logging for lecture visualization
self.history["loss_on_train"].append(loss.cpu().detach().item())
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
out = self.model(x)
loss = self.criterion(out, y)
self.log("loss_on_test", loss, prog_bar=True)
# aux logging for lecture visualization
self.history["loss_on_test"].append(loss.cpu().detach().item())
Создадим и запустим обучение модели с 2-мя скрытыми слоями и одним выходным слоем:
model_name = "n_layers2_sigmoid"
model = SimpleMNIST_NN(n_layers=2)
print(model)
SimpleMNIST_NN(
(activation): Sigmoid()
(layers): Sequential(
(0): Linear(in_features=784, out_features=100, bias=True)
(1): Sigmoid()
(2): Linear(in_features=100, out_features=100, bias=True)
(3): Sigmoid()
(4): Linear(in_features=100, out_features=10, bias=True)
)
)
from pytorch_lightning.loggers import TensorBoardLogger
from warnings import simplefilter
simplefilter("ignore", RuntimeWarning)
trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = Pipeline(model=model, exp_name=model_name)
trainer.fit(
model=pipeline,
train_dataloaders=train_loader,
val_dataloaders=test_loader,
)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/n_layers2_sigmoid/lightning_logs INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ----------------------------------------------- 0 | model | SimpleMNIST_NN | 89.6 K 1 | criterion | CrossEntropyLoss | 0 ----------------------------------------------- 89.6 K Trainable params 0 Non-trainable params 89.6 K Total params 0.358 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.plot([model_name])

А теперь посмотрим на модель с 3-мя скрытыми слоями и одним выходным слоем:
model_name = "n_layers3_sigmoid"
model = SimpleMNIST_NN(n_layers=3)
print(model)
SimpleMNIST_NN(
(activation): Sigmoid()
(layers): Sequential(
(0): Linear(in_features=784, out_features=100, bias=True)
(1): Sigmoid()
(2): Linear(in_features=100, out_features=100, bias=True)
(3): Sigmoid()
(4): Linear(in_features=100, out_features=100, bias=True)
(5): Sigmoid()
(6): Linear(in_features=100, out_features=10, bias=True)
)
)
trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = Pipeline(model=model, exp_name=model_name)
trainer.fit(model=pipeline, train_dataloaders=train_loader, val_dataloaders=test_loader)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/n_layers3_sigmoid/lightning_logs INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ----------------------------------------------- 0 | model | SimpleMNIST_NN | 99.7 K 1 | criterion | CrossEntropyLoss | 0 ----------------------------------------------- 99.7 K Trainable params 0 Non-trainable params 99.7 K Total params 0.399 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.plot(["n_layers2_sigmoid", model_name])

Замечание: На самом деле, если увеличить learning rate, размер батча или число нейронов, то нейросеть начнет учиться. Это учебный пример, чтобы показать, что такое бывает.
Нейросеть с тремя слоями вообще не учится. Почему? Можем попробовать разобраться.
Для этого напишем функции, которые будут следить за распределением градиентов и активаций на наших слоях.
Воспользуемся методами register_forward_hook и register_backward_hook из библиотеки PyTorch для того, чтобы выполнять эти функции при запуске прямого или обратного распространения через нашу сеть.
from collections import defaultdict
def get_forward_hook(history_dict, key):
def forward_hook(self, input_, output):
history_dict[key] = input_[0].cpu().detach().numpy().flatten()
return forward_hook
def get_backward_hook(history_dict, key):
def backward_hook(grad): # for tensors
history_dict[key] = grad.abs().cpu().detach().numpy().flatten()
return backward_hook
def register_model_hooks(model):
cur_ind = 0
hooks_data_history = defaultdict(list)
for child in model.layers.children():
if isinstance(child, nn.Linear):
forward_hook = get_forward_hook(
hooks_data_history, f"sigmoid_out_{cur_ind}"
)
child.register_forward_hook(forward_hook)
cur_ind += 1
backward_hook = get_backward_hook(
hooks_data_history, f"gradient_linear_{cur_ind}"
)
child.weight.register_hook(backward_hook)
return hooks_data_history
Запустим обучение модели с 3 слоями:
model_name = "n_layers3_sigmoid2"
model = SimpleMNIST_NN(n_layers=3)
hooks_data_history = register_model_hooks(model)
trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = Pipeline(model=model, exp_name=model_name)
trainer.fit(model=pipeline, train_dataloaders=train_loader, val_dataloaders=test_loader)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/n_layers3_sigmoid2/lightning_logs INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ----------------------------------------------- 0 | model | SimpleMNIST_NN | 99.7 K 1 | criterion | CrossEntropyLoss | 0 ----------------------------------------------- 99.7 K Trainable params 0 Non-trainable params 99.7 K Total params 0.399 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.plot(["n_layers2_sigmoid", model_name])

def plot_hooks_data(hooks_data_history):
keys = hooks_data_history.keys()
n_layers = len(keys) // 2
activation_names = [f"sigmoid_out_{i}" for i in range(1, n_layers)]
activations_on_layers = [
hooks_data_history[activation] for activation in activation_names
]
gradient_names = [f"gradient_linear_{i + 1}" for i in range(n_layers)]
gradients_on_layers = [hooks_data_history[gradient] for gradient in gradient_names]
for plot_name, values, labels in zip(
["activations", "gradients"],
[activations_on_layers, gradients_on_layers],
[activation_names, gradient_names],
):
fig, ax = plt.subplots(1, len(labels), figsize=(14, 4), sharey="row")
for label_idx, label in enumerate(labels):
ax[label_idx].boxplot(values[label_idx], labels=[label])
plt.show()
plot_hooks_data(hooks_data_history)


Мы видим, что градиент нашей модели стремительно затухает. Первые слои (до которых градиент доходит последним), получают значения градиента, мало отличимые от нуля.
Причем, это будет верно с самых первых шагов обучения нашей модели.
Откуда оно берется?
Посмотрим на обычную сигмоиду
$$\sigma(z) = \dfrac 1 {1 + e^{-z}}$$Ее производная, как мы уже выводили, равна
$$\dfrac {\partial \sigma(z)} {\partial z} = \sigma(z) (1 - \sigma(z))$$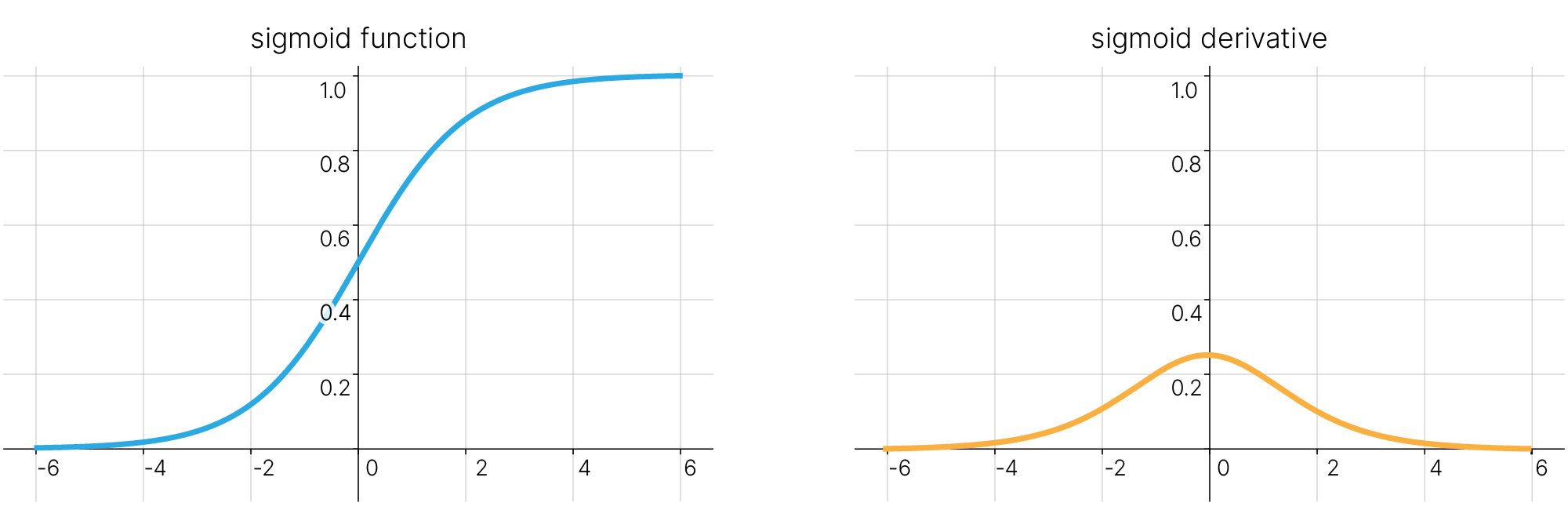
Какое максимальное значение у такой функции?
Сигмоида находится в пределах от $0$ до $1$. Максимальное значение производной по сигмоиде $=\dfrac 1 4$.
Теперь возьмем простую нейронную сеть:
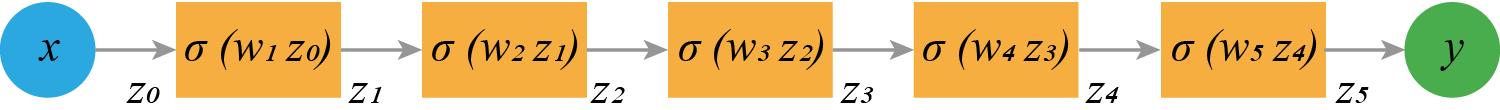
Посчитаем у нее градиент
$$\dfrac {\partial L} {\partial z_4} = \dfrac {\partial L} {\partial y} \dfrac {\partial y} {\partial z_4} = \dfrac {\partial L} {\partial y} \dfrac {\partial \sigma(w_5z)} {\partial z} w_5 \le \dfrac 1 4 \dfrac {\partial L} {\partial y} w_5 $$Аналогично можно посчитать градиент для $z_3$
$$\dfrac {\partial L} {\partial z_3} = \dfrac {\partial L} {\partial z_4} \dfrac {\partial z_4} {\partial z_3} \le \dfrac {\partial L} {\partial y} \dfrac {\partial \sigma(w_4z)} {\partial z} w_5 \le \left({\dfrac 1 4}\right)^2 \dfrac {\partial L} {\partial y} w_5 w_4$$И так далее
$$\dfrac {\partial L} {\partial x} \le \left({\dfrac 1 4}\right)^5 \dfrac {\partial L} {\partial y} w_5 w_4 w_3 w_2 w_1$$Таким образом:
градиент начинает экспоненциально затухать, если веса маленькие;
если веса большие, то градиент начинает экспоненциально возрастать (взрыв градиента).
Для некоторых функций активации картина будет не столь катастрофична, но тоже неприятна. При выполнении заданий вы посмотрите, например, как ведет себя функция ReLU в этом случае.
Давайте подумаем, что можно сделать с нейронной сетью, чтобы она начала учиться. В начале рассмотрим методы, не изменяющие структуру сети (без добавления дополнительных слоев), также зафиксируем количество нейронов и параметры оптимизатора.
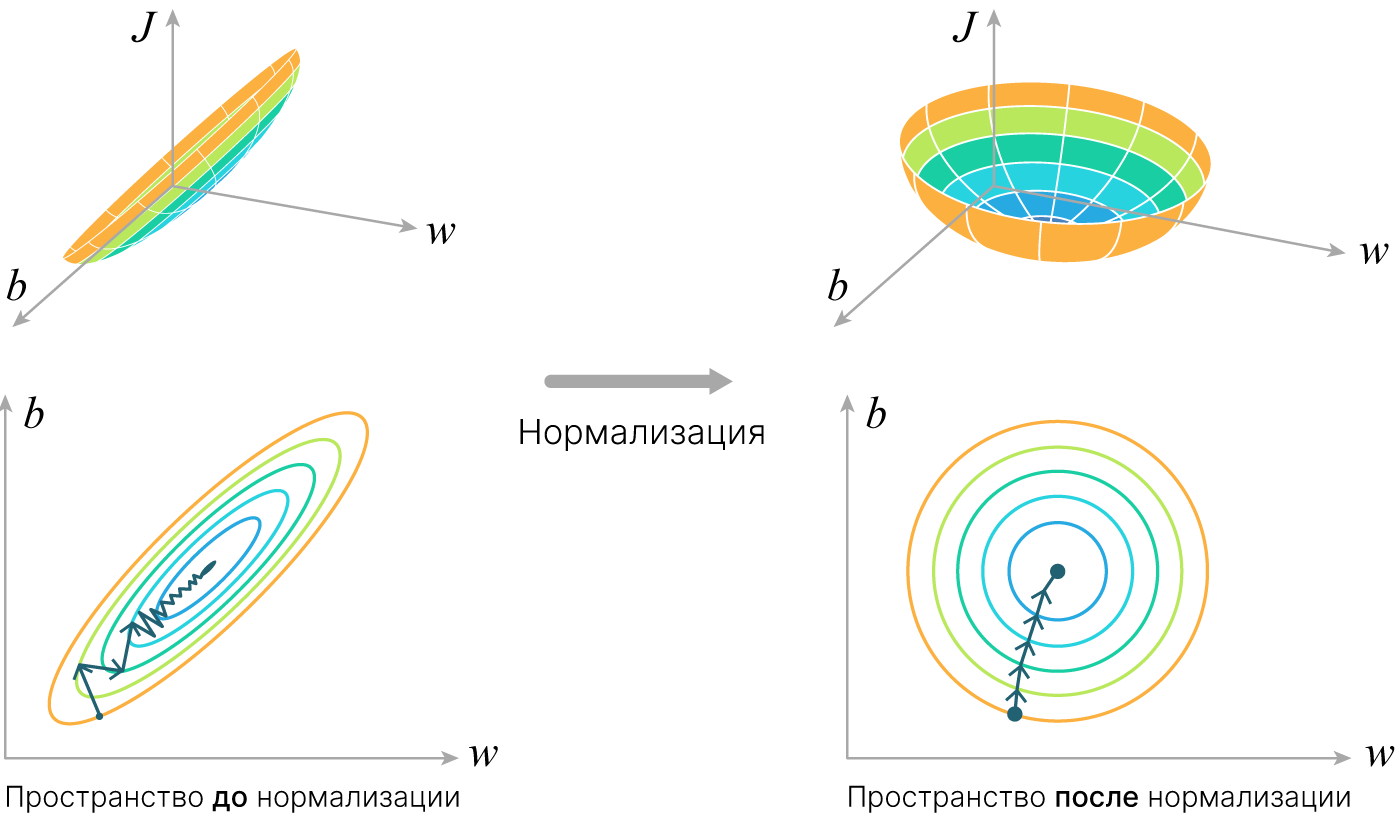
Начнем с уже знакомого: нормализация.
Представим себе, что данные, которые мы подаем в нейросеть, распределены следующим образом:

Фактически нейросети работают со скалярными произведениями. В этом плане два вектора, изображенные на рисунке, не сильно отличаются. Также и точки нашего датасета слабо разделимы. Чтобы с этим работать, нейросеть сначала должна подобрать удобное преобразование, а затем сравнивать объекты. Понятно, что это усложняет задачу.
Для того, чтобы облегчить нейросети задачу, входные признаки часто нормируют:
$$x1' = \dfrac {x1 - \mu_{x1}} {\sigma_{x1}}$$$$x2' = \dfrac {x2 - \mu_{x2}} {\sigma_{x2}}$$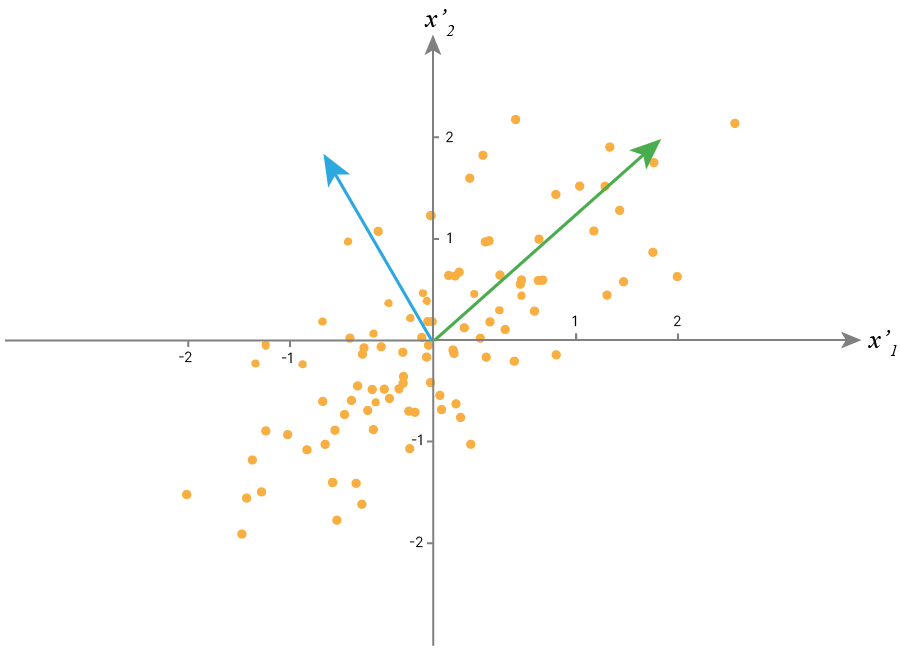
Такое преобразование действительно помогает нейросети:
В ряде приложений также нужна нормализация выходных значений, например, в задаче регрессии. Существует несколько причин, почему это необходимо.
В большинстве случаев мы нормализуем входные данные, чтобы среднее значение было равно $0$.
import torch
import matplotlib.pyplot as plt
x = torch.randn((512, 100)) # Fake normalized data
plt.hist(x.mean(dim=0), bins=20)
plt.show()
print(f"X mean: {x.mean().item():.2f} X variance: {x.var().item():.2f}")

X mean: -0.01 X variance: 1.01
Кроме этого мы определенным случайным образом инициализируем веса.
from torch import nn
net = nn.Sequential(
nn.Linear(100, 50), # weights randomly sampled from some random distribution
nn.Sigmoid(),
nn.Linear(50, 1),
)
Веса нормально распределены вокруг нуля:
weights = net[0].weight.data.numpy()
plt.hist(weights.flatten(), bins=20)
plt.show()
print(f"Weights mean: {weights.mean():.2f}, Weights variance: {weights.var():.2f}")

Weights mean: -0.00, Weights variance: 0.00
Необученная сеть будет чаще всего предсказывать значения порядка $10^{-1}$.
out = net(x)
plt.hist(out.detach().numpy(), bins=20)
plt.show()
print(f"Out mean: {out.mean().item():.2f}, Out variance: {out.var().item():.2f}")

Out mean: -0.21, Out variance: 0.01
Предположим, мы предсказываем какую-то большую величину. Например, стоимость дома в штате Калифорния в долларах 🛠️[doc] (в датасете в Sklearn целевое значение нормировано на $100\ 000\$$). Стоимость лежит в диапазоне от $15\ 000\$$ до $500\ 000\$$.
Выберем случайные значения в этом диапазоне.
# fake cost
targets = torch.randint(15_000, 500_000, (512, 1), dtype=torch.float32)
print(f"Target example: {targets[:10].flatten()}")
Target example: tensor([420452., 334842., 101781., 156010., 394764., 285088., 378961., 56029.,
214563., 454530.])
Если мы будем пытаться предсказывать эти значения, мы получим очень большую ошибку.
criterion = nn.MSELoss()
loss = criterion(out, targets)
loss.backward()
print(f"Loss: {loss.item():.2f}")
Loss: 91326431232.00
Эта ошибка приведет к большим значениям градиента (cмотрим на значения по $x$), большим значениям весов и нестабильному обучению.
import pandas as pd
import seaborn as sns
layer_names = ("Linear 1", "Sigmoid", "Linear 2", "Loss")
gradient_values = {}
for layer_name, p in zip(layer_names, net.parameters()):
gradient_values[layer_name] = pd.Series(p.grad.detach().flatten().numpy())
# print(f"{layer_name} grad: \n {p.grad}")
gradient_values = pd.DataFrame(gradient_values)
data_to_plot = gradient_values.melt(value_name="Gradient value", var_name="Layer name")
plt.figure(figsize=(10, 4))
sns.boxplot(data=data_to_plot, x="Gradient value", y="Layer name")
plt.grid()
plt.title(f"Large gradient values in the case of learning on a nonnormalized target")
plt.show()

Если мы стандартизуем целевые значения:
mean = targets.float().mean()
std = targets.float().std()
transformed_targets = (targets - mean) / std
print(transformed_targets.flatten()[:10])
tensor([ 1.0909, 0.4781, -1.1899, -0.8018, 0.9070, 0.1221, 0.7939, -1.5173,
-0.3827, 1.3348])
То получим ошибку на 10 порядков меньше:
net.zero_grad()
out = net(x)
loss = criterion(out, transformed_targets)
loss.backward()
print(f"Loss: {loss.item():.2f}")
Loss: 1.05
И небольшие градиенты (cмотрим на значения по $x$):
layer_names = ("Linear 1", "Sigmoid", "Linear 2", "Loss")
gradient_values = {}
for layer_name, p in zip(layer_names, net.parameters()):
gradient_values[layer_name] = pd.Series(p.grad.detach().flatten().numpy())
# print(f"{layer_name} grad: \n {p.grad}")
gradient_values = pd.DataFrame(gradient_values)
data_to_plot = gradient_values.melt(value_name="Gradient value", var_name="Layer name")
plt.figure(figsize=(10, 4))
sns.boxplot(data=data_to_plot, x="Gradient value", y="Layer name")
plt.grid()
plt.title(f"Large gradient values in the case of learning on a nonnormalized target")
plt.show()

В ряде задач, например, при использовании нейронных сетей для моделирования физических процессов 🎓[arxiv], в задаче регрессии необходимо вычислять несколько целевых значений. При этом необходимо помнить, что в качестве функционала ошибки в задачах регрессии часто выбирается метрика расстояния, а физические величины могут иметь различный порядок и диапазон значений. Не самая лучшая идея — считать расстояние, когда по одной оси отложены нанометры, а по другой — килограммы.
В физических задачах полезно изучить, какие нормировки используют в численных методах для получения безразмерных (dimensionless) величин 📚[book]. Это может подсказать хорошую, физически обоснованную нормировку.
Одним из способов борьбы с затухающим градиентом является правильная инициализация весов. Как это сделать?
Идея 1: инициализировать все веса константой.
Проблема: градиент по всем весам будет одинаков, как и обновление весов. Все нейроны в слое будут учить одно и то же, или, в случае $\text{const} = 0$ и активации $\text{ReLU}$, не будут учиться вообще ✏️[blog].
Вывод: в качестве начальных весов нужно выбирать различные значения.
Идея 2: инициализировать веса нормальным (Гауссовским) шумом с матожиданием $0$ и маленькой дисперсией.
Маленькая дисперсия нужна, чтобы не получить огромные градиенты за большие изначальные ошибки в предсказании.
# Normal distribution: mu = 0, sigma = 1
x = np.arange(-4, 4.1, 0.1)
y = np.exp(-np.square(x) / 2) / np.sqrt(2 * np.pi)
plt.style.use("seaborn-v0_8-whitegrid")
plt.title("Normal distribution: mu = 0, sigma = 1", size=15)
plt.plot(x, y)
plt.show()

Проблема: инициализация нормальным шумом не гарантирует отсутствие взрыва или затухания градиета.
Идея 3: формализуем условия, при которых взрыв или затухание градиентов не будут происходить.
Это важно, т.к. значения признаков используются при расчете градиента. Например, для линейного слоя: $$y = wx+b$$ $$\dfrac{\partial y} {\partial w} = x$$
Запишем это условие:
$$Dz^i = Dz^j. \tag{1}$$При выполнении этих условий градиент не затухает и не взрывается.
Инициализации Ксавье и Каймин Хе пытаются выполнить эти условия.
Рассмотрим функцию активации гиперболический тангенс ($\tanh$).

Это — нечетная функция 📚[wiki] с единичной производной в нуле. Функция и ее производная изображены ниже.
x = np.arange(-10, 10.1, 0.1)
y = np.tanh(x)
dy = 1 / np.cosh(x)
plt.style.use("seaborn-v0_8-whitegrid")
fig, (im1, im2) = plt.subplots(2, 1, figsize=(7, 7))
im1.set(title="tanh(x)")
# fmt: off
im1.plot(x[0:51], y[0:51], "#F9B041",
x[150:201], y[150:201], "#F9B041",
x[50:96], y[50:96], "#2DA9E1",
x[105:151], y[105:151], "#2DA9E1",
x[95:106], y[95:106], "#4AAE4D",)
im1.grid(True)
im2.set(title="tanh'(x)")
im2.plot(x[0:51], dy[0:51], "#F9B041",
x[150:201], dy[150:201], "#F9B041",
x[50:96], dy[50:96], "#2DA9E1",
x[105:151], dy[105:151], "#2DA9E1",
x[95:106], dy[95:106], "#4AAE4D",)
# fmt: on
im2.grid(True)
plt.show()

Третья интуиция, которая нам понадобится: нам важно не попасть в **оранжевые** зоны с почти нулевой производной, т.к. в этих областях градиент затухает. Мы хотим инициализировать веса таким образом, чтобы признаки, поступающие на слой активации, находились в **зеленой** области в окрестности нуля. Матожидание признаков, поступающих на слой активации, будет равно нулю: $$E(z^i_t w_{kt})=0.$$
В **зеленой** области условия $(1)$ и $(2)$ можно переписать как:
$$n_iDW^i = 1,$$$$n_{i+1}DW^i = 1,$$где $n_i$ — размерность выхода слоя i-го слоя.
Если размерность слоев отличается, то условия невыполнимы одновременно:
$$n_i \ne n_{i+1}. $$
На практике хорошо работает компромисс — среднее гармоническое решений первого $\dfrac 1 {n_i}$ и второго $\dfrac 1 {n_{i+1}}$ уравнения:
$$DW^i = \dfrac 2 {n_i + n_{i+1}}.$$Итого: нам нужно инициализировать веса нейронов случайными величинами со следующими матожиданием и дисперсией:
$$ EW^i = 0,$$$$DW^i = \dfrac 2 {n_i + n_{i+1}}.$$Мы можем взять равномерное распределение 📚[wiki]. Именно такое распределение было предложено в Understanding the difficulty of training deep feedforward neural networks 🎓[article]:
$$W_i \sim U[a, b ],$$где $a=-b$, так как матожидание равно $0$.
Дисперсия которого выражается формулой: $$D(U[a, b]) = \dfrac 1 {12} (b -a)^2 = \dfrac 4 {12} b^2 = \dfrac 1 {3} b^2.$$
Получим:
$$ b = \sqrt{\dfrac {6} {n_i + n_{i + 1}}}$$Итого:
$$W_i \sim U[-\sqrt{\dfrac {6} {n_i + n_{i + 1}}}, \sqrt{\dfrac {6} {n_i + n_{i + 1}}}],$$где $n_i$ — размерность выхода слоя n-го слоя.
Можно использовать и другие распределения, например нормальное 📚[wiki]. Для него получится: $$W_i \sim N (0, std=\sqrt{\dfrac{2}{n_i + n_{i + 1}}})$$ Результат получится аналогичный.
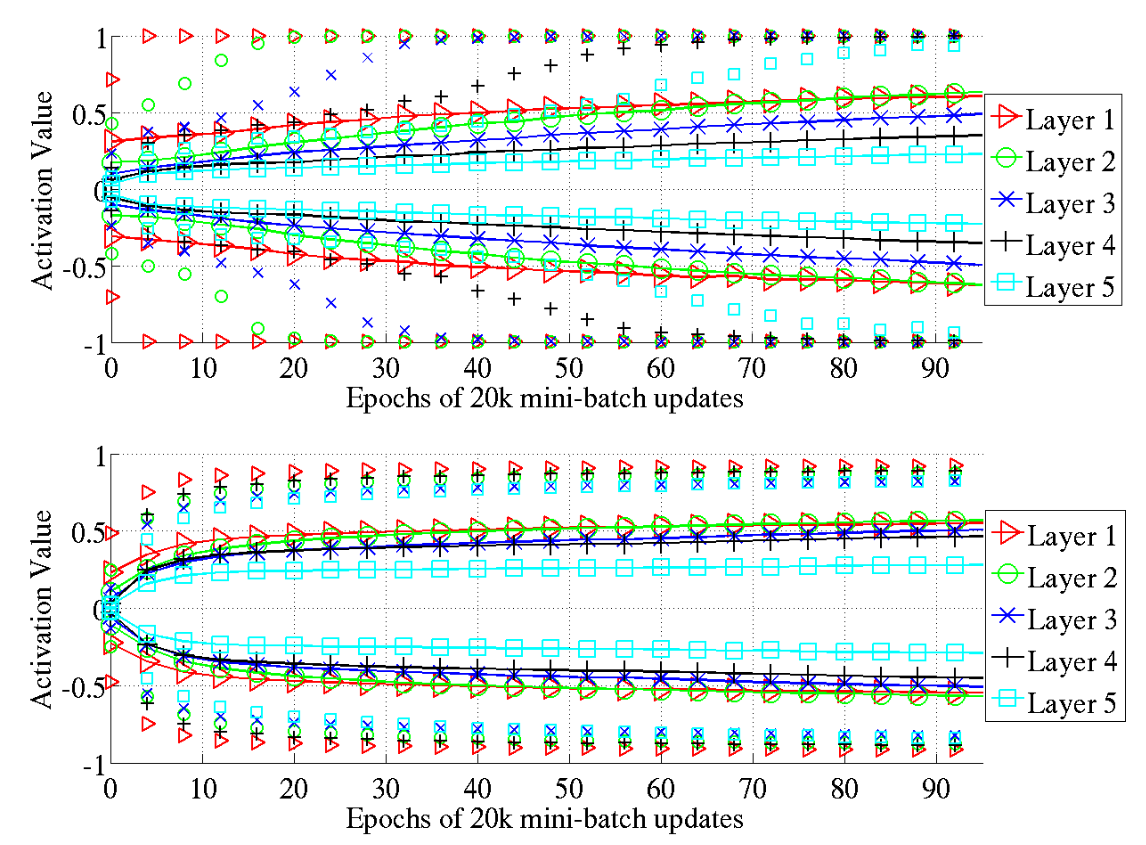
Чтобы понять, что происходит с выходами слоя активации при использовании инициализации Xavier, рассмотрим картинку из оригинальной статьи Understanding the difficulty of training deep feedforward neural networks (Xavier, Yoshua, 2010) 🎓[article]:
На картинке изображена зависимость 98-процентиля 📚[wiki] (отдельные маркеры) и стандартного отклонения (соединенные маркеры) значений на выходе слоя активации $\text{tanh}$ от эпохи обучения для различных слоев нейросети.
Верхнее изображение — инициализация весов с помощью нормального распределения $W_i \sim U[-\dfrac {1} {\sqrt{n_i}}, \dfrac {1} {\sqrt{n_i}} ]$. Нижнее — с использованием инициализации Xavier.
На верхнем изображении видно, как значения $98$-процентиля уходят в значения $+1$ и $-1$ (сначала на выходе первого слоя, потом на выходе второго и т.д.). Это значит, что для части нейронов происходит затухание градиентов (они переходят в область, отмеченную на графиках $\text{tanh}(x)$, $\text{tanh}’(x)$ **оранжевым** и перестают учиться). На нижней картинке такого не происходит.
Xavier используется для симметричных функций активаций, таких как tanh и sigmoid.
Вообще говоря, коэффициенты в инициализациях (числитель в формуле для дисперсии) зависят от конкретной выбранной функции активации. В PyTorch есть функции 🛠️[doc] для вычисления этих коэффициентов.
Для функции активации ReLU и ее модификаций (PReLU, Leaky ReLU и т.д.) аналогично инициализации Xavier можно расписать условия $(1)$, $(2)$. Так вводится He-инициализация.
Условия $(1)$, $(2)$ эквивалентны условиям:
$$ \dfrac {n_iDW^i} {2} = 1, $$$$\dfrac {n_{i+1}DW^i} {2} = 1.$$Можно опять взять среднее гармоническое. Но на практике берут либо $\displaystyle \frac 2 {n_i}$, либо $\displaystyle \frac 2 {n_i + 1}$.
Итого получим для нормального распределения:
$$W^i \sim N(0, std=\sqrt{\frac 2 {n_i}})$$Для равномерного распределения: $$W^i \sim U(-\sqrt{\frac 3 {n_i}}, \sqrt{\frac 3 {n_i}})$$
Более подробно о выводе инициализации Каймин Хе:

Обучение нейронной сети с 22 слоями при использовании инициализации He и Xavier
Source: Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification

Обучение нейронной сети с 30 слоями при использовании инициализации He и Xavier
Source: Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
Другой идеей является ортогональная инициализация. Преобразование 📚[wiki], заданное ортогональной матрицей 📚[wiki], не изменяет расстояние между точками. Можно представить ортогональную матрицу как матрицу поворота 📚[wiki] (это не совсем верно, т.к. матрицы перестановки тоже ортогональны), т.е. линейный слой будет разворачивать карту признаков, чтобы собирать их линейные комбинации, не изменяя масштаб признаков.
Для каждого слоя мы убеждаемся, что изначальная матрица весов является ортогональной.
Выберем ортогональную матрицу весов: $$W: WW^T = 1$$
Тогда:
Норма активации сохраняется (активации между слоями остаются в одном масштабе): $$||s_{i+1}|| = ||W_{i}s_i|| = ||s_i||$$
Все нейроны делают «разные» преобразования: $$ ⟨W_i, W_j⟩ = 0~i \ne j$$ $$ ⟨W_i, W_j⟩ = 1~i = j$$
Замечание: т.к. ортогональные матрицы бывают только квадратные, то этот метод подходит только для слоев с одинаковым количеством входных и выходных значений.
Иногда такая инициализация обеспечивает значительно лучшую сходимость. Подробнее:
Для инициализации весов в PyTorch используется модуль torch.nn.init, в котором для этого определены разные функции.
Нюанс состоит в том, что обычно для слоев разного типа может требоваться разная инициализация. Поэтому в функции, которая инициализирует слои вашей нейронной сети, желательно прописывать разное поведение для разных слоев.
Попробуем, например, добавить в нашу нейросеть инициализацию. Нам нужна инициализация Xavier, так как у нас nn.Sigmoid.
Метод torch.nn.init.calculate_gain возвращает рекомендуемое значение коэффициента масштабирования для стандартного отклонения заданной функции активации.
class SimpleMNIST_NN(nn.Module):
def __init__(self, n_layers, activation=nn.Sigmoid, init_form="normal"):
super().__init__()
self.n_layers = n_layers
self.activation = activation()
layers = [nn.Linear(28 * 28, 100), self.activation]
for _ in range(0, n_layers - 1):
layers.append(nn.Linear(100, 100))
layers.append(self.activation)
layers.append(nn.Linear(100, 10))
self.layers = nn.Sequential(*layers)
self.init_form = init_form
if self.init_form is not None:
self.init()
def forward(self, x):
x = x.view(-1, 28 * 28)
x = self.layers(x)
return x
# xavier weight initialization
def init(self):
sigmoid_gain = torch.nn.init.calculate_gain("sigmoid")
for child in self.layers.children():
if isinstance(child, nn.Linear):
if self.init_form == "normal":
torch.nn.init.xavier_normal_(child.weight, gain=sigmoid_gain)
if child.bias is not None:
torch.nn.init.zeros_(child.bias)
elif self.init_form == "uniform":
torch.nn.init.xavier_uniform_(child.weight, gain=sigmoid_gain)
if child.bias is not None:
torch.nn.init.zeros_(child.bias)
else:
raise NotImplementedError()
Запустим обучение модели с инициализацией весов Xavier:
model_name = "n3_layers_sigmoid_havier"
odel = SimpleMNIST_NN(n_layers=3, init_form="normal")
# plotting weights values of first(input layer)
plt.figure(figsize=(12, 4))
plt.hist(
list(model.layers.children())[0].weight.cpu().detach().numpy().reshape(-1), bins=100
)
plt.title("weights histogram")
plt.xlabel("values")
plt.ylabel("counts")
plt.show()

trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = Pipeline(model=model, exp_name=model_name)
trainer.fit(model=pipeline, train_dataloaders=train_loader, val_dataloaders=test_loader)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/n3_layers_sigmoid_havier/lightning_logs INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ----------------------------------------------- 0 | model | SimpleMNIST_NN | 99.7 K 1 | criterion | CrossEntropyLoss | 0 ----------------------------------------------- 99.7 K Trainable params 0 Non-trainable params 99.7 K Total params 0.399 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.plot(["n_layers3_sigmoid", model_name])

Видим, что нейросеть стала хоть как-то учиться.
В статье про Batch Normalization 🎓[arxiv] авторы предположили, что похожее явление имеет место внутри нейросети, назвав его internal covariate shift.
Internal covariate shift — это изменение распределения выхода слоя активации из-за изменения обучаемых параметров во время обучения.
Пусть у нас $k$-ый нейрон $i$-го слоя переводит выход $i$−1 слоя с распределениями $f^{(j)}_{i-1}(x)$ в новое пространство с распределением $f^{(k)}_{i}(x)$.
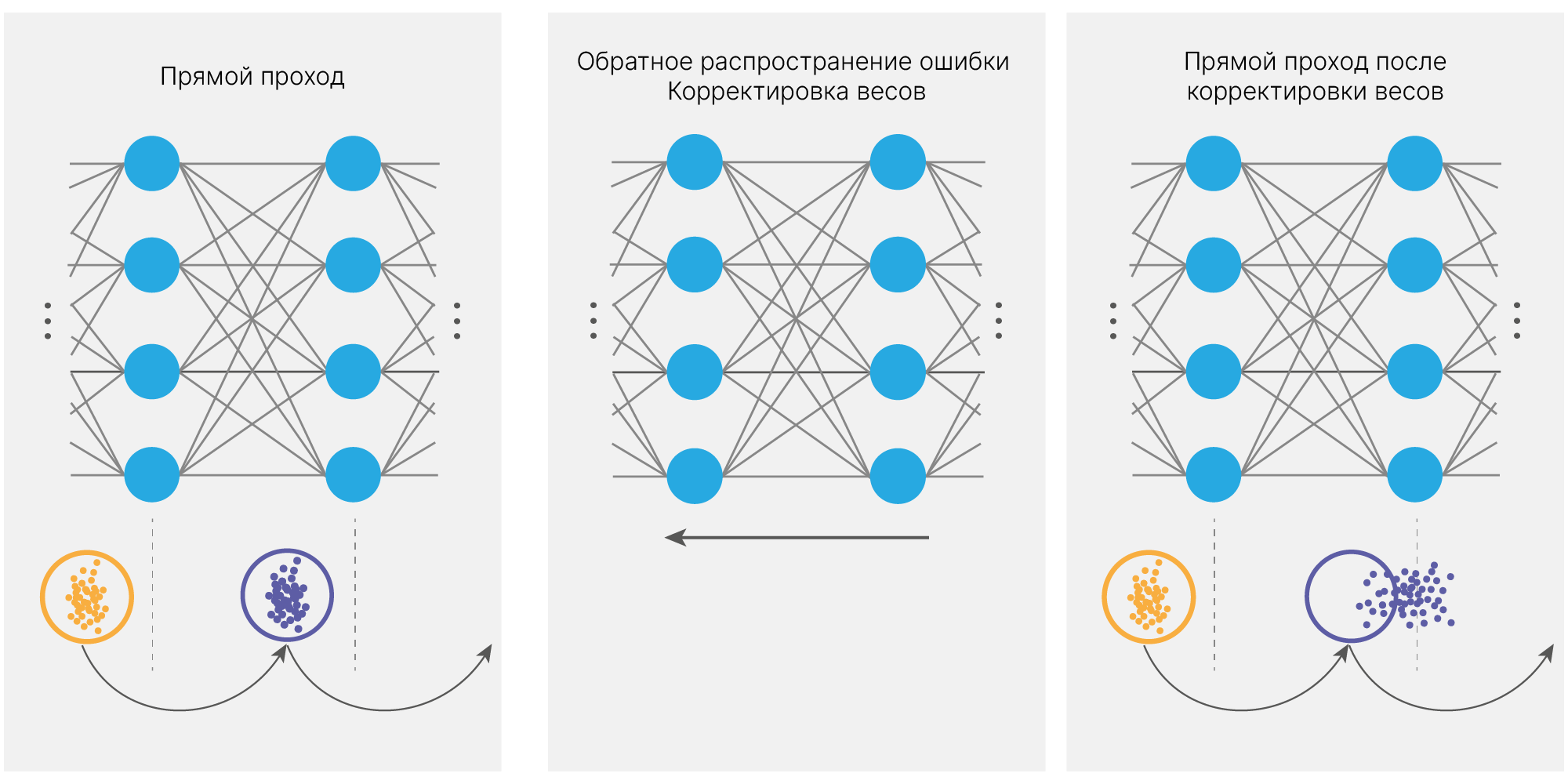
При обучении:
После обновления весов $k$-ый нейрон $i$-го слоя будет переводить выходы $i$−1 слоя $f^{(j)}_{i-1}(x)$ в пространство с другим распределением $f^{*(k)}_{i}(x)$.
При этом $i$+1 слой учился работать со старым распределением $f^{(k)}_{i}(x)$, и будет хуже обрабатывать $f^{*(k)}_{i}(x)$.
Давайте на каждом слое просто нормировать каждый признак (выход каждого нейрона), используя среднее и дисперсию по батчу:
$$ \hat{x}_{i} = \frac{x_{i} - \mu_{B}}{\sigma_{B} + \epsilon}$$Проблема в том, что таким образом мы можем попасть в область линейной составляющей нашей функции. Например, в случае сигмоиды:

Получаем набор линейных слоев фактически без функций активации, следовательно, все вырождается в однослойную сеть. Не то, что нам надо.
Нам надо дать нейронной сети возможность перемещать распределение выходов слоя из области $0$ и самой подбирать дисперсию. Для этой цели используется батч-нормализация (batch normalization), которая вводит в нейронную сеть дополнительную операцию между соседними скрытыми слоями. Она состоит из нормализации входящих (в слой батч-нормализации) значений, полученных от скрытого слоя, масштабирования и сдвига с применением двух новых параметров и передачи полученных значений на вход следующему скрытому слою.

Параметры, используемые в батч-нормализации ($\gamma$ — отвечающий за сжатие и $\beta$ — отвечающий за сдвиг), являются обучаемыми параметрами (наподобие весов и смещений скрытых слоев).
Помимо обучаемых параметров $\gamma$ и $\beta$ в слое батч-нормализации существуют также необучаемые параметры: скользящее среднее матожидания (Mean Moving Average) и скользящее среднее дисперсий (Variance Moving Average), служащие для сохранения состояния слоя батч-нормализации.
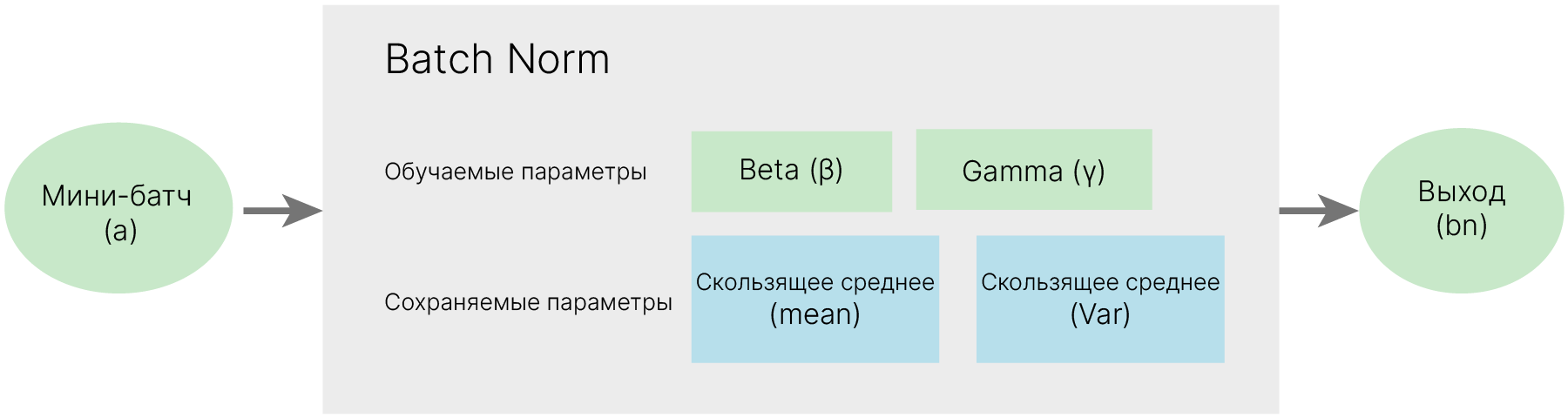
Параметры $\gamma$, $\beta$, а также оба скользящих средних вычисляются для каждого слоя батч-нормализации отдельно и являются векторами с длиной, равной количеству входящих признаков.
В процессе обучения мы подаем в нейронную сеть по одному мини-батчу за раз. Процедуру обработки значений одного признака $x^{(k)}$ (фиолетовая колонка на изображении ниже), который для краткости мы будем обозначать $x$, из одного мини-батча $ B = \{x_{1},\ldots, x_{m}\} $ можно представить следующим образом:

Шаг масштабирования Gamma ($γ$) и шаг сдвига Beta ($β$) являются главным новшеством батч-нормализации, поскольку, в отличие от предыдущего рассмотренного примера, нормированные значения больше не обязаны иметь среднее, равное $0$, и единичную дисперсию. Батч-нормализация позволяет сдвигать среднее нормированных значений и масштабировать дисперсию. Фактически, теперь нейросеть даже может отменить нормализацию входных данных, если считает ее ненужной.
Для наглядности проиллюстрируем размерности промежуточных переменных на следующем изображении:
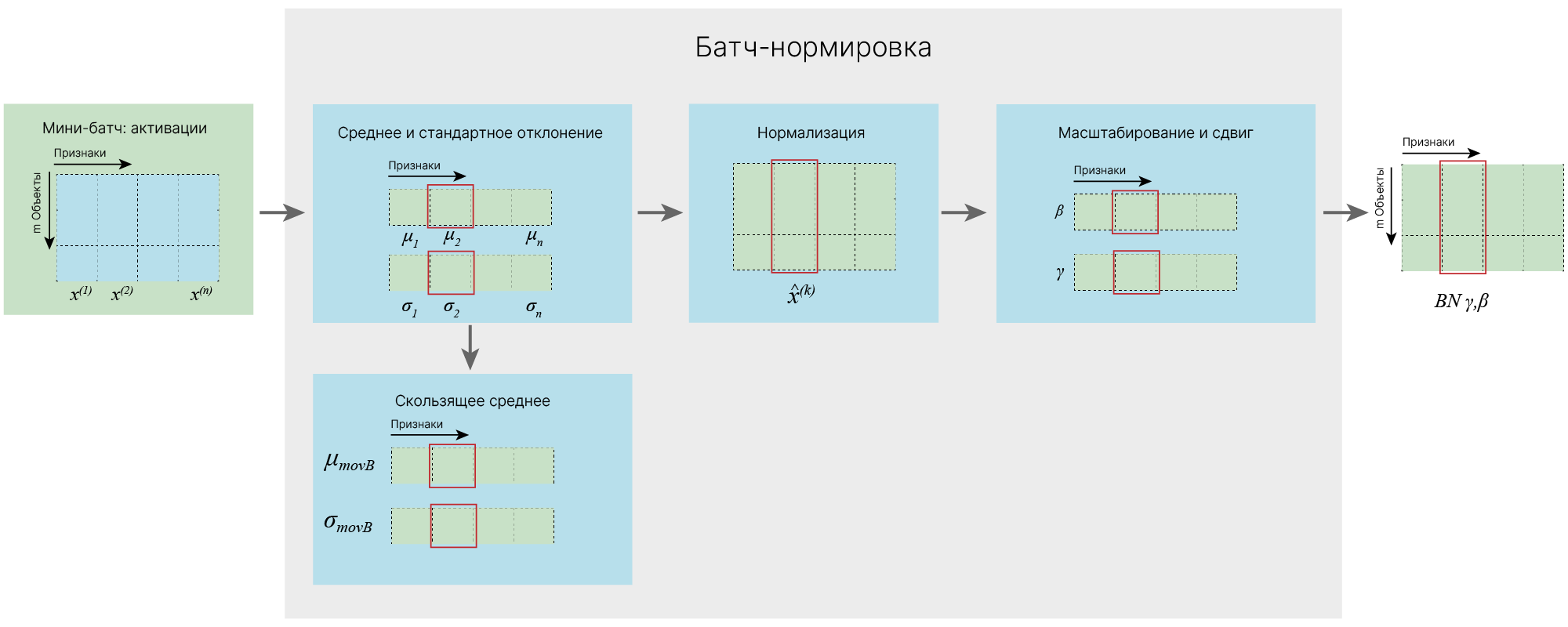
После прямого прохода параметры $\gamma$ и $\beta$ обновляются через обратное распространение ошибки так же, как и веса скрытых слоев.
Выше мы обсуждали то, что в процессе обучения слой батч-нормализации рассчитывает значение среднего и дисперсии каждого признака в соответствующем мини-батче. Предположим, нам нужно сделать предсказание на одном объекте. Во время предсказания батч у нас уже отсутствует. Откуда брать среднее и дисперсию?
Во время предсказания используется скользящее среднее, которое было рассчитано и сохранено в процессе обучения.
$$\large \mu_{mov_{B}} = (1-\alpha)\mu_{mov_{B-1}}+\alpha\mu_{B} $$$$\large \sigma_{mov_{B}} = (1-\alpha)\sigma_{mov_{B-1}}+\alpha\sigma_{B} $$Обычно используется параметр $\alpha = 0.1$
Для перевода модели из режима обучения в режим тестирования и обратно в PyTorch используются model.train() и model.eval().
Почему используется именно скользящее среднее, а не статистика всей обучающей выборки?
При таком подходе нам бы пришлось хранить средние всех признаков для всех батчей, пропущенных через нейросеть в ходе обучения. Это ужасно невыгодно по памяти. Вместо этого скользящее среднее выступает в качестве приближенной оценки среднего и дисперсии обучающего набора. В этом случае эффективность использования ресурсов увеличивается: нам нужно хранить в памяти только одно число — значение скользящего среднего, полученное на последнем шаге.
Проиллюстрировать преимущество использования скользящего среднего можно на следующем примере:
Предположим, что у нас есть массив объектов, обладающих некоторым признаком $x$ (обучающая выборка), и некоторый черный ящик, извлекающий по $k$ объектов из этого массива (Dataloader). Наша задача — дать оценку ожидаемому среднему этих $k$ объектов. В данном примере для простоты будем извлекать $k$ объектов из некоего распределения случайным образом:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
k = 500 # sample size
n = 2
p = 0.5
sample = np.random.negative_binomial(n, p, k)
sns.histplot(data=sample, discrete=True)
plt.show()

Оценить ожидаемое среднее теоретически, не зная, как распределен признак $x$ наших объектов, трудно. Мы можем собрать большое количество средних и произвести оценку с их помощью, но для этого нам потребуется хранить в памяти все эти значения, что приведет к неэффективному расходу ресурсов. Более эффективным решением будет воспользоваться скользящим средним. Давайте сравним эти два метода:
ema = 0
alpha = 0.01
means = np.array([])
for i in range(10000):
sample = np.random.negative_binomial(n, p, 50)
ema = (1 - alpha) * ema + alpha * sample.mean()
means = np.append(means, sample.mean())
Посчитаем количество памяти, затрачиваемое на хранение списка средних значений признака $x$ по выборкам из $k$ объектов, и количество памяти, затрачиваемое на хранение скользящего среднего:
import sys
print(f"{sys.getsizeof(ema)} bytes")
32 bytes
Количество памяти для хранения списка средних:
print(f"{sys.getsizeof(means)} bytes")
80112 bytes
Видно, что на хранение массива средних значений расходуется на порядки больше памяти, чем на хранение одного скользящего среднего. Теперь давайте воспользуемся тем, что мы сэмплировали случайные выборки из известного распределения, и можем теоретически рассчитать их среднее. В нашем примере мы извлекали выборки из негативного биномиального распределения с параметрами $n=2$ и $p=0.5$, для которого среднее рассчитывается по формуле: $$\text{mean}=\dfrac{np}{1-p}=2.$$
Мы знаем, что при достаточно большом количестве сэмплированных выборок среднее распределения выборочных средних будет стремиться к среднему генеральной совокупности. Сравним результаты, полученные с использованием сохраненных выборочных средних и скользящего среднего с теоретическим расчетом:
Среднее признака $x$ по $k$ объектам, оцененное с помощью скользящего среднего:
print(f"{ema:.8f}")
1.98288149
Среднее признака $x$ по $k$ объектам, оцененное по всем сэмплированным выборкам:
print(f"{means.mean():.8f}")
2.00273800
Видно, что мы получили довольно точную оценку, использовав скользящее среднее.
Чтобы у нас не мог возникнуть $0$ в знаменателе, добавляем маленькое число — $\epsilon$. Например, $\epsilon = 10^{-5}$.
$$ \hat{x}_{i} = \frac{x_{i} - \mu_{B}}{\sigma_{B} + \epsilon}$$$$ \text{BN}_{\gamma, \beta}(x_{i}) = \gamma \hat{x}_{i} + \beta $$Сверточный слой можно свести к линейному слою. BatchNorm можно применять и для линейных слоев, и для сверточных.
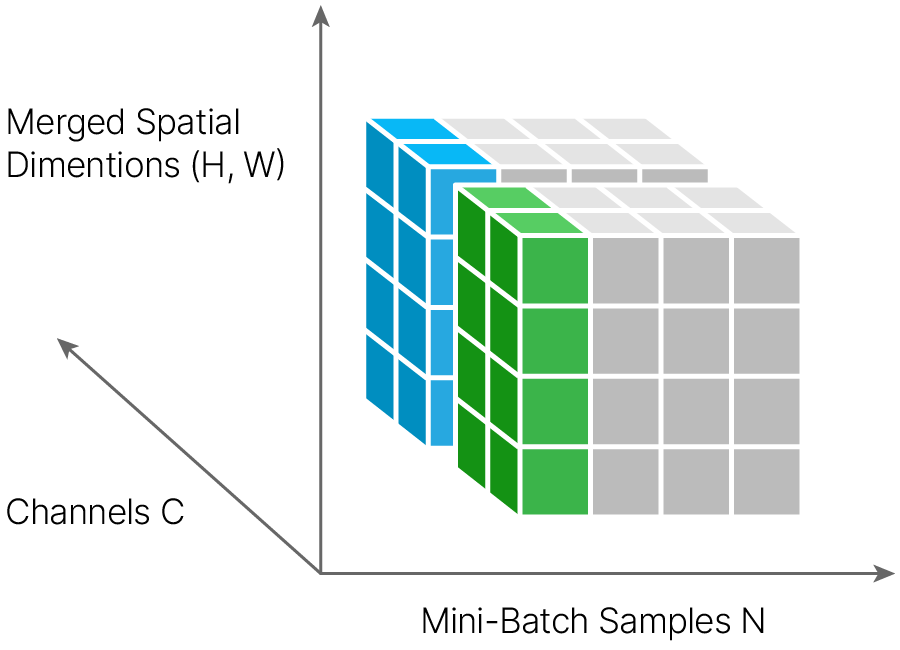
Признаки внутри одного канала (одной карты признаков) получаются путем применения к исходному изображению одних и тех же преобразований. По сути 1 канал — это карта одного признака. Поэтому логично, что нормализация будет происходить по каналам, а одним признаком считается одна feature map. Нормализация идет по всей такой feature map (по всему каналу) для всех объектов батча.

Графически нормализации часто объясняют при помощи следующей схемы:
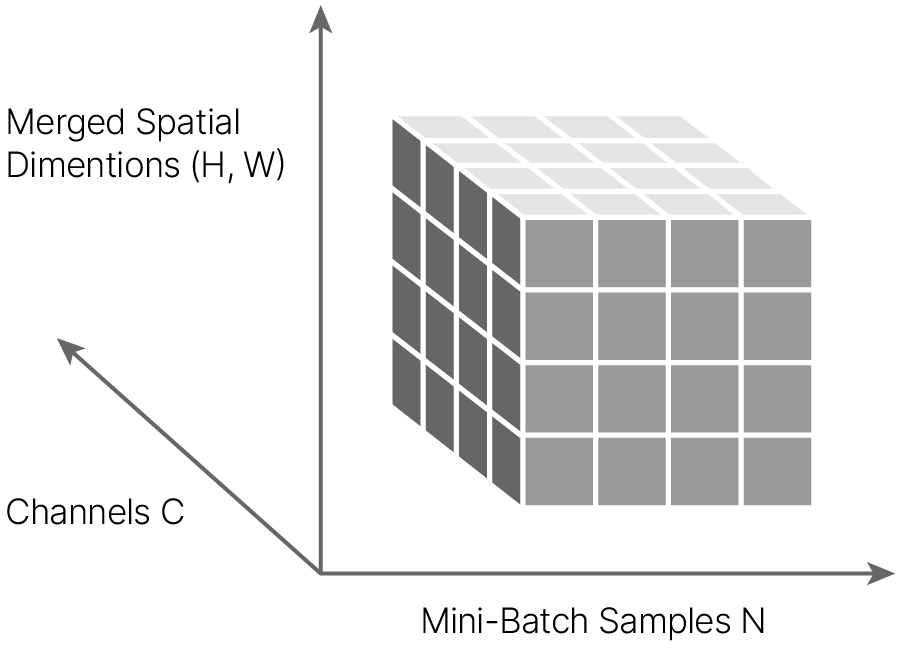
По оси абсцисс расположены объекты из батча, по оси ординат — feature map, преобразованный в вектор, по оси аппликат — каналы (feature maps).
В этом представлении BatchNorm для свертки выглядит следующим образом:

Source: Batch Normalization

Обучение нейронной сети с BN позвляет увеличить lr в 30 раз, сохранив стабильность обучения
Source: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shiftn
Этот метод действительно работает. Видим, что нейросети с батч-нормализацией:
Вычисление градиента BatchNorm — интересное упражнение на понимание того, как работает backpropagation. В лекции мы это опускаем, можете ознакомиться самостоятельно:
[blog] ✏️ Deriving the Gradient for the Backward Pass of Batch Normalization
Почему для нейросети с батчнормализацией можно использовать более высокие learning rate?
Оказывается, батч-нормализация делает неявную регуляризацию на веса.
Допустим, мы решили увеличить веса в $a$ раз.
Так как мы шкалируем, то домножение весов $W$ на константу выходных значений слоя не меняет
$$BN((aW)u) = BN(Wu)$$Градиент слоя по входу не меняется
$$\dfrac {\partial BN((aW)u)} {\partial u} = \dfrac {\partial BN(Wu)} {\partial u}$$А градиент по весам уменьшается в $a$ раз
$$\dfrac {\partial BN((aW)u)} {\partial aW} = \dfrac 1 a \dfrac {\partial BN(Wu)} {\partial W} $$Таким образом нейросеть автоматически не дает большим весам расти
Batch Normalization была разработана на идее необходимости коррекции Internal covariate shift. В 2019 году вышла статья 🎓[arxiv], которая показала, что влияние коррекции Internal covariate shift на качество обучения не так велико, как считали авторы Batch Normalization.
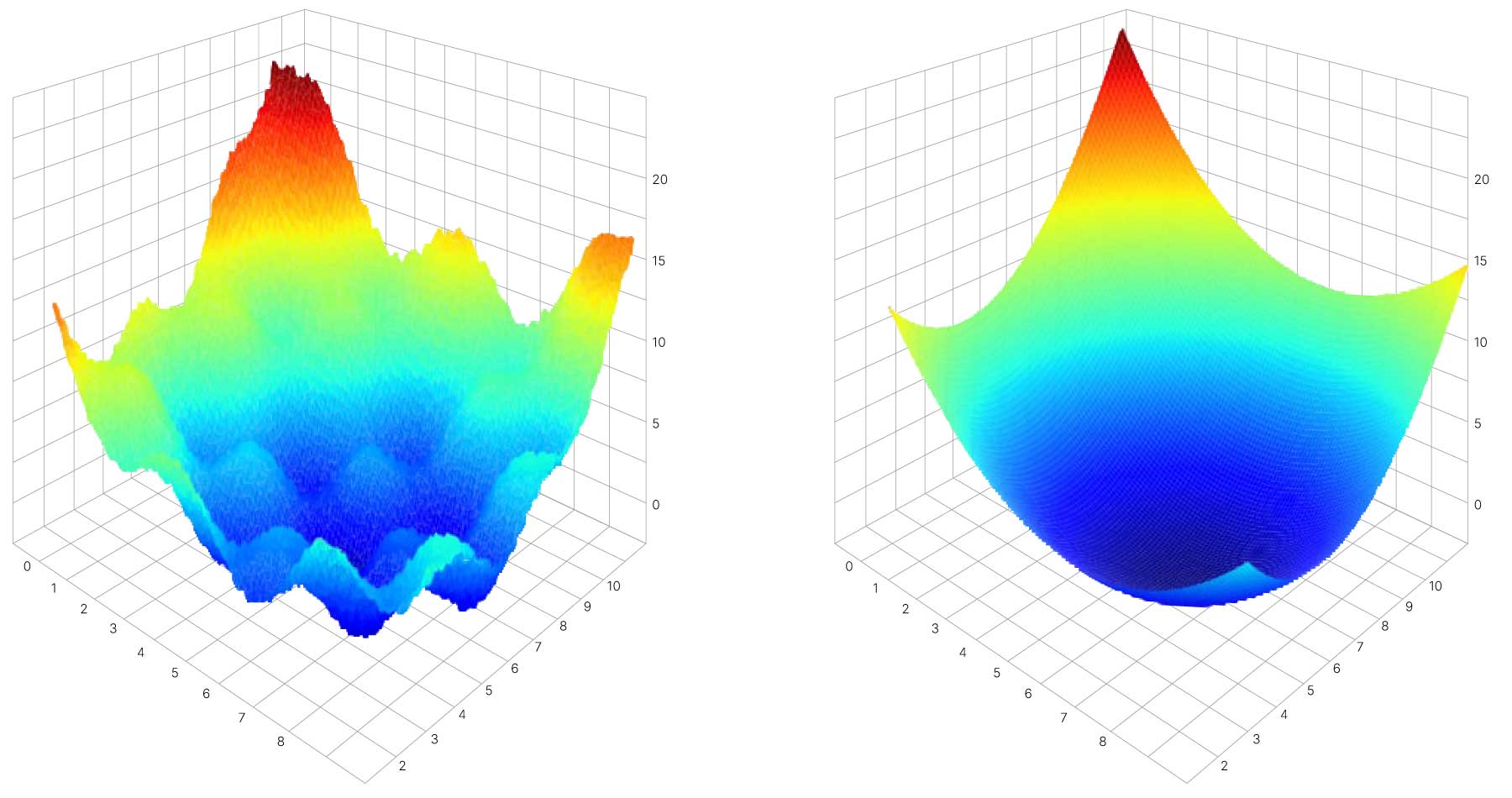
Другим интересным эффектом Batch Normalization оказалось сглаживание ландшафта функции потерь. Batch Normalization улучшает гладкость пространства решений и облегчает поиск в нем минимума. Именно благодаря сглаживанию ландшафта Batch Normalization справляется с затуханием и взрывом градиента.
Стоит помнить, что с батч-нормализацией:
Крайне важно перемешивать объекты (составлять новые батчи) между эпохами. Единицей обучения параметров $\beta$ и $\gamma$ являются батчи. Если их не перемешивать, то из 6400 объектов в тренировочном датасете получим лишь 100 объектов (при условии, что в батче 64 объекта) для обучения $\beta$ и $\gamma$. Данное требование учитывается автоматически при использовании стохастического градиентного спуска в качестве алгоритма оптимизации параметров сети.
В слое, после которого поставили Batch Normalization, можно убрать bias (параметр $\beta$ в BatchNormalization берет эту роль на себя).
Source: Group Normalization
Так как наша модель из-за Batch Normalization ведет себя по-разному во время обучения и во время тестирования, то мы должны прямо ей сообщать, обучается она сейчас или нет. Делается это при помощи функций model.train и model.eval
# pseudocode for training a model in pure pytorch
def train(model, optimizer, criterion, train_loader, test_loader):
for epoch in range(epochs):
model.train()
for train_batch in train_loader:
do_train_step(model, train_batch, optimizer, criterion)
model.eval()
for test_batch in test_loader:
do_test_step(model, test_batch, optimizer, criterion)При использовании для обучения PyTorch Lightning гарантируется, что связанный с обучением training_step() будет выполнен для модели в состоянии model.train() и что связанный с запуском модели на тестовой выборке validation_step() будет выполнен для модели в состоянии model.eval(). Это позволяет нам проще не допустить ошибку.
class SimpleMNIST_NN_Init_Batchnorm(nn.Module):
def __init__(self, n_layers):
super().__init__()
self.n_layers = n_layers
layers = [
nn.Linear(28 * 28, 100, bias=False),
nn.BatchNorm1d(100),
nn.Sigmoid(),
]
for _ in range(0, n_layers - 1):
layers.append(nn.Linear(100, 100, bias=False))
layers.append(nn.BatchNorm1d(100))
layers.append(nn.Sigmoid())
layers.append(nn.Linear(100, 10))
self.layers = nn.Sequential(*layers)
self.init()
def forward(self, x):
x = x.view(-1, 28 * 28)
x = self.layers(x)
return x
def init(self):
sigmoid_gain = torch.nn.init.calculate_gain("sigmoid")
for child in self.layers.children():
if isinstance(child, nn.Linear):
torch.nn.init.xavier_normal_(child.weight, gain=sigmoid_gain)
if child.bias is not None:
torch.nn.init.zeros_(child.bias)
model_name = "batchnorm2"
model = SimpleMNIST_NN_Init_Batchnorm(n_layers=3)
trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = Pipeline(model=model, exp_name=model_name)
trainer.fit(model=pipeline, train_dataloaders=train_loader, val_dataloaders=test_loader)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/batchnorm2/lightning_logs INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ------------------------------------------------------------ 0 | model | SimpleMNIST_NN_Init_Batchnorm | 100 K 1 | criterion | CrossEntropyLoss | 0 ------------------------------------------------------------ 100 K Trainable params 0 Non-trainable params 100 K Total params 0.400 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.add(history)
history_plotter.plot(["n_layers3_sigmoid", "n3_layers_sigmoid_havier", model_name])

Попробуем, согласно советам, увеличить learning rate:
model_name = "batchnorm_increased_lr"
model = SimpleMNIST_NN_Init_Batchnorm(n_layers=3)
trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = Pipeline(model=model, exp_name=model_name, optimizer_kwargs={"lr": 1e-2})
trainer.fit(model=pipeline, train_dataloaders=train_loader, val_dataloaders=test_loader)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/batchnorm_increased_lr/lightning_logs INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ------------------------------------------------------------ 0 | model | SimpleMNIST_NN_Init_Batchnorm | 100 K 1 | criterion | CrossEntropyLoss | 0 ------------------------------------------------------------ 100 K Trainable params 0 Non-trainable params 100 K Total params 0.400 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.plot(["n3_layers_sigmoid_havier", "batchnorm2", model_name])

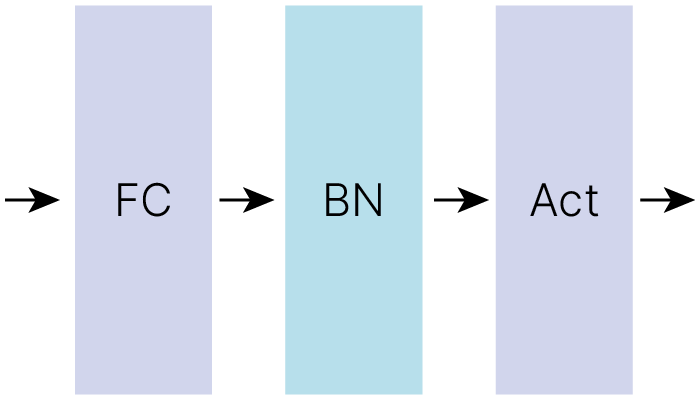

Вывод: В общем случае стоит располагать слой BN перед активацией, но с этим можно экспериментировать.
Существует большое количество иных нормализаций, их неполный список можно найти здесь 🎓[article]. В данной секции мы рассмотрим самые популярные виды нормализации помимо BatchNorm.

Помимо свёрточных нейронных сетей, существует специальный тип нейронных сетей, используемых для обработки последовательностей. Называется он "рекуррентные нейронные сети", ему будет посвящена одна из следующих лекций.
Когда оказалось, что BatchNorm положительно сказывается на обучении нейронных сетей, его попытались применить для различных архитектур. BatchNorm нельзя было использовать "из коробки" для рекуррентных нейронных сетей (работающих с последовательными данными), пришлось придумывать различные адаптации, среди которых наиболее удачной оказалась Layer Normalization.
По сути, теперь нормализация происходит внутри одного объекта из батча, а не поканально в рамках батча. С математической точки зрения данная "адаптация" отличается от BatchNorm, однако экспериментально она превзошла своих конкурентов в задаче нормализации при обработке последовательных данных.
Впоследствии данный метод нормализации хорошо проявил себя в трансформерах — наследниках рекуррентных нейронных сетей в вопросах обработки последовательных данных (об этом типе нейросетей мы также поговорим на одной из следующих лекций). После успешного применения трансформеров в задачах компьютерного зрения, LayerNorm стал использоваться и в компьютерном зрении (хотя и уступал BatchNorm при использовании в свёрточных нейронных сетях).

Source: Layer Normalization
Следующий вид нормализации был предложен отечественными исследователями (из Сколтеха), занимавшимися разработкой быстрого и эффективного способа переноса стиля с одного изображения на другое.
При использовании BatchNorm теряется информация о контрастах на конкретном изображении, поскольку нормализация производится по нескольким объектам. Для сохранения контрастов в экземпляре (instance) изображения была предложена специальная нормализация, рассматривающая конкретный канал одного конкретного объекта. Было предложено два названия нормализации: связанное с мотивацией (contrast normalization) и связанное с принципом работы (instance normalization).

Source: Instance Normalization
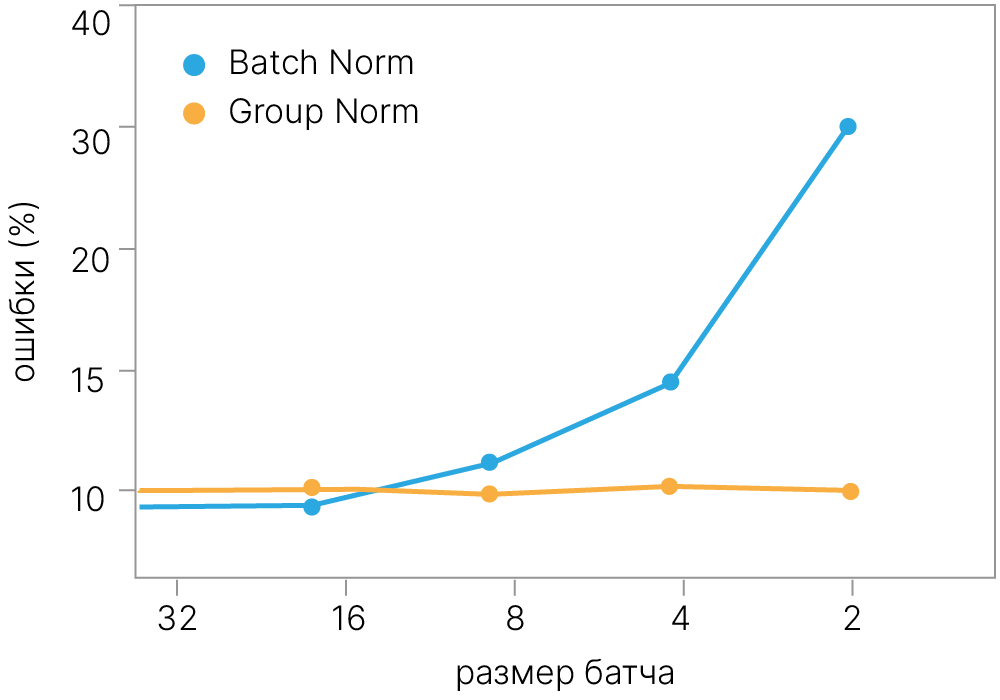
В течение долгого времени BatchNorm оставался однозначным фаворитом для использования в задачах компьютерного зрения, однако:
В связи с необходимостью точно считать статистики внутри batch при обучении приходилось использовать большой batch size.
Ограниченность размера памяти видеокарты вынуждает разработчиков идти на компромисс между сложностью модели и размером батча.
Таким образом, использование BatchNorm приводило к невозможности использовать сложные модели*, поскольку им просто не хватало места на видеокарте.
Необходимость использовать большой batch size могут решать различные нормализации, не использующие batch-размерность. К примеру, уже известные нам Layer Norm и Instance Norm. Эмпирически оказалось, что данные нормализации уступают BatchNorm по качеству работы: в то время как LayerNorm предполагает одинаковую важность и суть различных каналов (рассматривая данные излишне глобально), InstanceNorm упускает межканальные взаимодействия (рассматривая данные слишком локально).
Успешным обобщением данных методов является Group Normalization: данный метод разбивает каналы на $G \in [1; C]$ групп, присваивая каждой из них примерно равное количество каналов. Отметим, что при $G = 1$ GroupNorm идентичен LayerNorm, а при $G = C$ GroupNorm идентичен InstanceNorm.
Эмпирически оказалось, что при замене BatchNorm на GroupNorm качество модели падает в разы менее значительно, чем при использовании LayerNorm либо InstanceNorm. Более того, при изменении batch size качество работы GroupNorm не изменялось, что открыло перспективы для создания более сложных моделей компьютерного зрения.
* — подразумевается, что уменьшение batch size позволило бы создать более сложные модели.
Source: Group Normalization
Второй способ улучшения сходимости нейросетей и борьбы с переобучением — введение регуляризации. Ее можно вводить несколькими способами.
Мы уже разбирали самый простой способ — добавление штрафа к весам в функцию потерь. На сходимость нейросети это, правда, влияет слабо.
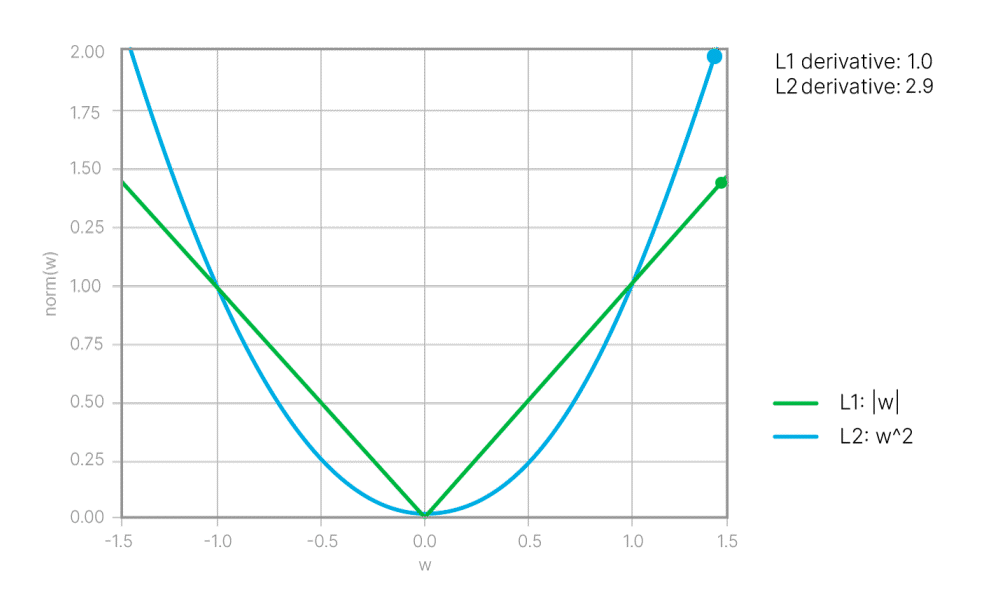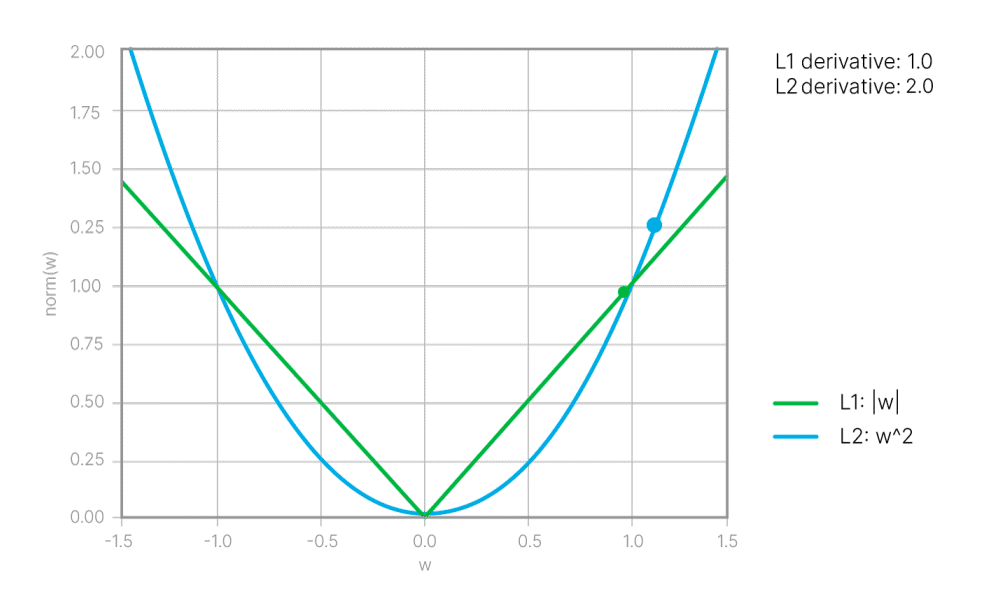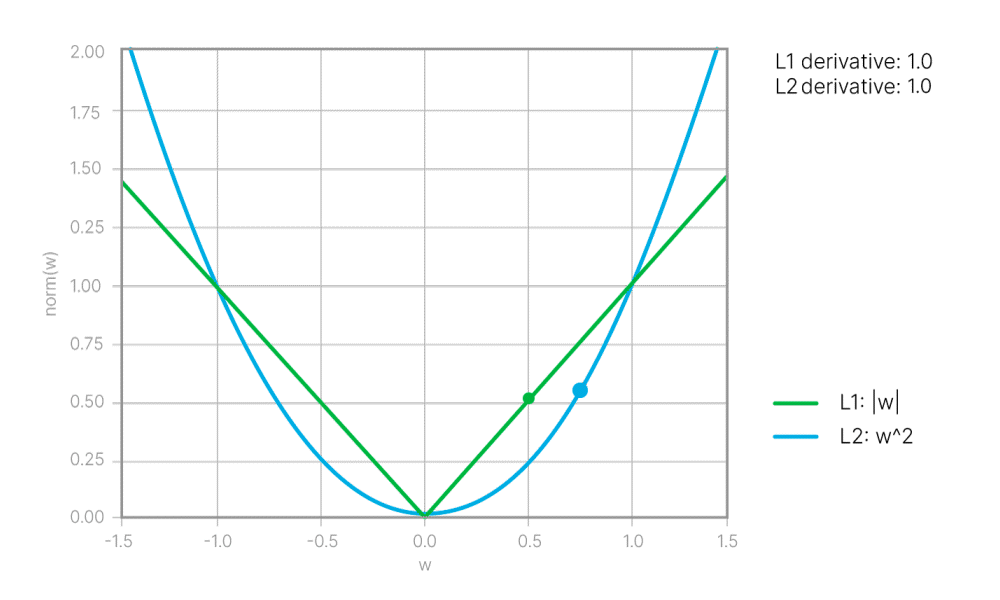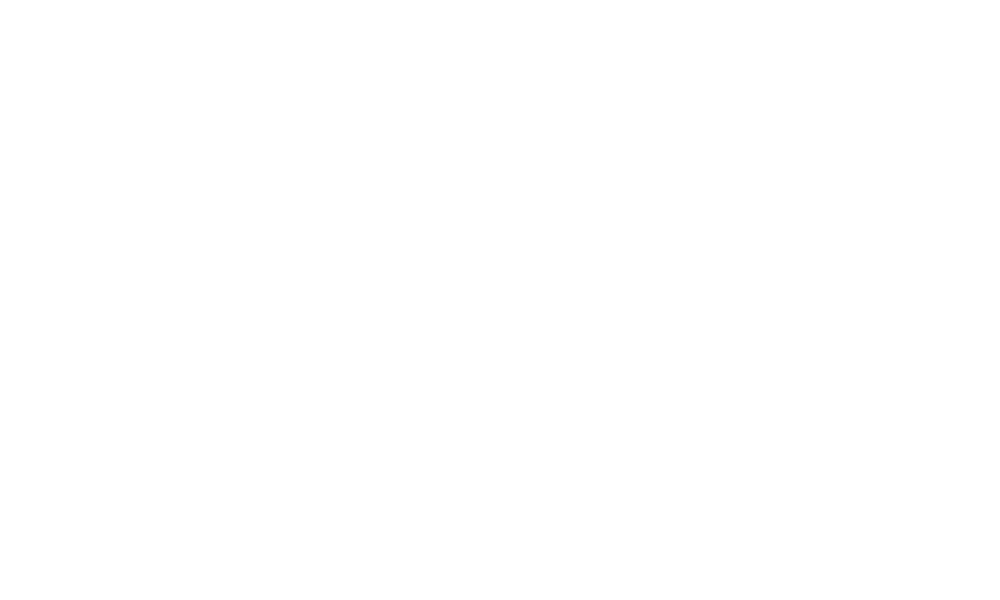
Иногда уже его хватает, чтобы решить все проблемы. Напомним, что L2 Loss приводит к большому числу маленьких ненулевых весов в сети. А L1 Loss — к маленькому числу ненулевых весов (разреженной нейросети).
В PyTorch L2 регуляризация (или её аналоги) часто "встроена" в оптимизаторы и связана с параметром weight_decay. Подробнее различия между weight_decay и L2 мы обсудим ниже.
sgd = torch.optim.SGD(model.parameters(), lr=0.001, weight_decay=0.001)
Одним из распространенных именно в нейросетях методом регуляризации является Dropout.
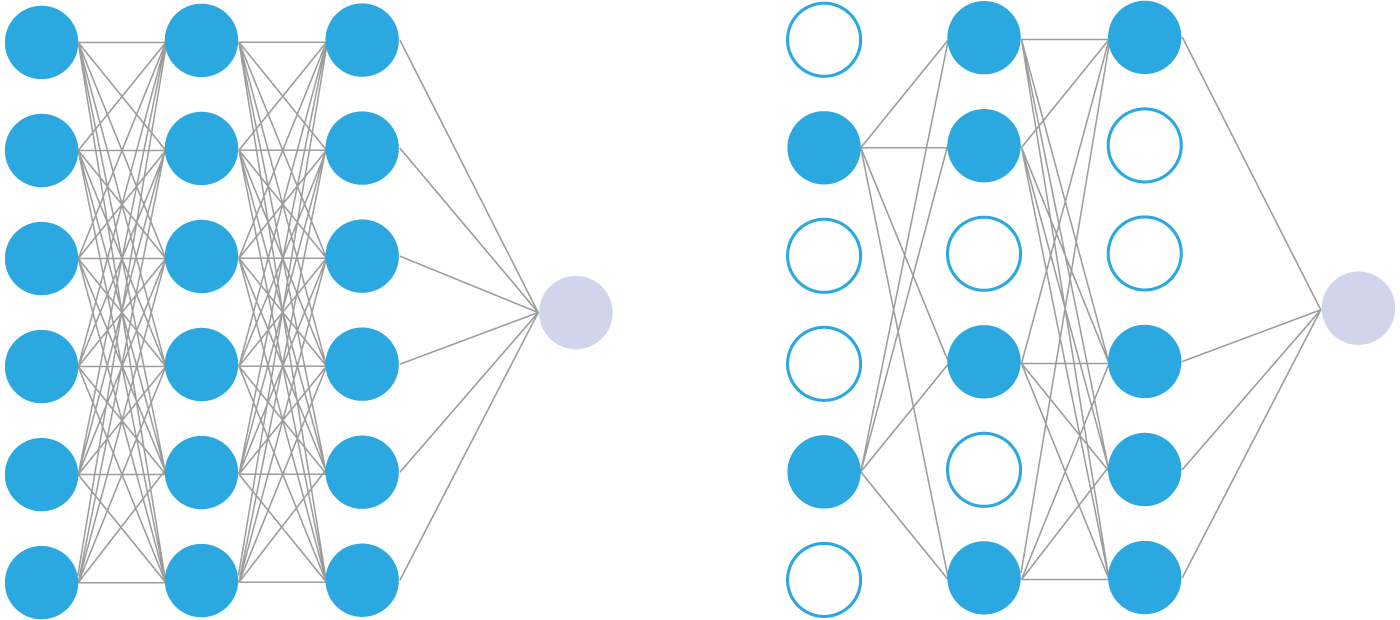
Состоит этот метод в следующем:
forward, и поэтому градиент к ним при backward не идет.
Одной из проблем при работе с глубокими сетями является совместная адаптация нейронов. Если все весовые коэффициенты обучаются вместе, некоторые соединения будут иметь больше возможностей прогнозирования, чем другие.
Часть нейронов делает основную работу — предсказывает, а остальные могут вообще не вносить никакого вклада в итоговое предсказание. Или же другая картина: один нейрон делает неверное предсказание, другие его исправляют, и в итоге первый нейрон свои ошибки не исправляет.
Это явление называется коадаптацией. Его нельзя было предотвратить с помощью традиционной регуляризации, такой как L1 и L2. А вот Dropout с этим хорошо борется.
Отключая хорошо обученные нейроны, мы заставляем плохо обученные нейроны учиться. Отключая нейроны, которые исправляют ошибки других нейронов, мы заставляем ошибающиеся нейроны исправлять ошибки.
Dropout гарантирует, что выучиваемые индивидуальными нейронами функции хорошо работают со случайно выбранными подмножествами функций, выученных другими нейронами, улучшая обобщающую способность нейронов.
На следующем рисунке, извлеченном из статьи про Dropout 🎓[article], мы находим сравнение признаков, изученных в наборе данных MNIST нейросетью с одним скрытым слоем в автоэнкодере, имеющем $256$ признаков после ReLU без Dropout (слева), и признаков, изученных той же структурой с использованием Dropout в ее скрытом слое с $p = 0.5$ (справа).
Первый показывает неструктурированные, беспорядочные паттерны, которые невозможно интерпретировать. Второй явно демонстрирует целенаправленное распределение весов, которое обнаруживает штрихи, края и пятна самостоятельно, нарушая их взаимозависимость с другими нейронами для выполнения этой работы.
Фактически, Dropout штрафует слишком сложные, неустойчивые решения. Добавляя в нейросеть Dropout, мы сообщаем ей, что решение, которое мы ожидаем, должно быть устойчиво к шуму.
Можно рассматривать Dropout как ансамбль нейросетей со схожими параметрами, которые мы учим одновременно, вместо того, чтобы учить каждую в отдельности, а затем результат их предсказания усредняем, выключая Dropout в режиме eval ✏️[blog].
Таким образом, возникает аналогия со случайным лесом: каждая из наших нейросетей легко выучивает выборку и переобучается — имеет низкий bias, но высокий variance. При этом, за счет временного отключения активаций, каждая нейросеть видит не все объекты, а только часть. Усредняя все эти предсказания, мы уменьшаем variance.
Dropout, в силу указанного выше, может хорошо помогать бороться с переобучением.
И в случае линейных слоев:
И в случае свёрточных слоёв:
class BadDropout(nn.Module):
def __init__(self, p: float = 0.5):
super().__init__()
if p < 0 or p > 1:
raise ValueError(
f"Dropout probability has to be between 0 and 1, but got {p}"
)
self.p = p
def forward(self, x):
if self.training:
keep = torch.rand(x.size()) > self.p
if x.is_cuda:
keep = keep.to(device)
return x * keep
# in test time, expectation is calculated
return x * (1 - self.p)
Приведенная реализация неоптимальна, так как в режиме инференса (когда training = False) функция forward совершает дополнительное умножение. Одним из приоритетов при создании модели является скорость работы в режиме инференса. Поэтому по возможности все "лишние" операции выполняют только в режиме обучения. В данном случае можно целиком убрать коэффициент нормировки из режима инференса, перенеся его в режим обучения в знаменатель.
Дополнительным плюсом такого подхода является то, что при удалении модуля из архитектуры сети функция прогнозирования не изменится.
class Dropout(nn.Module):
def __init__(self, p: float = 0.2):
super().__init__()
if p < 0 or p > 1:
raise ValueError(
f"Dropout probability has to be between 0 and 1, but got {p}"
)
self.p = p
def forward(self, x):
if self.training:
keep = torch.rand(x.size()) > self.p
if x.is_cuda:
keep = keep.to(x)
return x * keep / (1 - self.p)
return x # in test time, expectation is calculated intrinsically - we just not divide weights
Попробуем применить Dropout в нашей нейросети:
class SimpleMNIST_NN_Dropout(nn.Module):
def __init__(self, n_layers, activation=nn.Sigmoid, init_form="normal"):
super().__init__()
self.n_layers = n_layers
self.activation = activation()
layers = [nn.Linear(28 * 28, 100), self.activation]
for _ in range(0, n_layers - 1):
layers.append(nn.Linear(100, 100))
layers.append(Dropout()) # add Dropout
layers.append(self.activation)
layers.append(nn.Linear(100, 10))
self.layers = nn.Sequential(*layers)
self.init_form = init_form
if self.init_form is not None:
self.init()
def forward(self, x):
x = x.view(-1, 28 * 28)
x = self.layers(x)
return x
def init(self):
sigmoid_gain = torch.nn.init.calculate_gain("sigmoid")
for child in self.layers.children():
if isinstance(child, nn.Linear):
if self.init_form == "normal":
torch.nn.init.xavier_normal_(child.weight, gain=sigmoid_gain)
if child.bias is not None:
torch.nn.init.zeros_(child.bias)
elif self.init_form == "uniform":
torch.nn.init.xavier_uniform_(child.weight, gain=sigmoid_gain)
if child.bias is not None:
torch.nn.init.zeros_(child.bias)
else:
raise NotImplementedError()
Так как наша модель из-за Dropout ведет себя по-разному во время обучения и во время тестирования, мы должны прямо ей сообщать, обучается она сейчас или нет.
$$ \begin{array}{c|c} \large{\text{model.train()}}&\ \large{\text{model.eval()}}\\ \hline \large{\text{Активируются Dropout слои}}&\large{\text{Слои Dropout отключены}}\\ \large{\text{Выход части нейронов обнуляется, выходы нормируются}}&\large{\text{Все нейроны работают}} \end{array} $$Обучим модель с Dropout:
model_name = "nn3_dropout"
model = SimpleMNIST_NN_Dropout(n_layers=3)
trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = Pipeline(model=model, exp_name=model_name, optimizer_kwargs={"lr": 1e-2})
trainer.fit(model=pipeline, train_dataloaders=train_loader, val_dataloaders=test_loader)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/nn3_dropout/lightning_logs INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ----------------------------------------------------- 0 | model | SimpleMNIST_NN_Dropout | 99.7 K 1 | criterion | CrossEntropyLoss | 0 ----------------------------------------------------- 99.7 K Trainable params 0 Non-trainable params 99.7 K Total params 0.399 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.plot(["n_layers3_sigmoid", "n3_layers_sigmoid_havier", model_name])

В данном случае выигрыша мы не получили. Возможно, если учить нейросеть больше эпох, эффект бы заметили
Чтобы увидеть эффект и при этом не учить нейросеть 100+ эпох, сделаем искусственный пример.
Просто добавим к линейной зависимости шум и попробуем выучить ее нейронной сетью.
N = 50 # number of data points
noise = 0.3
# generate the train data
x_train = torch.unsqueeze(torch.linspace(-1, 1, N), 1)
y_train = x_train + noise * torch.normal(torch.zeros(N, 1), torch.ones(N, 1))
# generate the test data
x_test = torch.unsqueeze(torch.linspace(-1, 1, N), 1)
y_test = x_test + noise * torch.normal(torch.zeros(N, 1), torch.ones(N, 1))
print(f"x_train shape: {x_train.shape}\nx_test shape: {x_test.shape}")
x_train shape: torch.Size([50, 1]) x_test shape: torch.Size([50, 1])
plt.scatter(
x_train.data.numpy(), y_train.data.numpy(), c="purple", alpha=0.5, label="train"
)
plt.scatter(
x_test.data.numpy(), y_test.data.numpy(), c="yellow", alpha=0.5, label="test"
)
x_real = np.arange(-1, 1, 0.01)
y_real = x_real
plt.plot(x_real, y_real, c="green", label="true")
plt.legend()
plt.show()

Модель без Dropout:
N_h = 100 # num of neurons
model = torch.nn.Sequential(
torch.nn.Linear(1, N_h),
torch.nn.ReLU(),
torch.nn.Linear(N_h, N_h),
torch.nn.ReLU(),
torch.nn.Linear(N_h, 1),
)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
Модель с Dropout:
N_h = 100 # num of neurons
model_dropout = nn.Sequential(
nn.Linear(1, N_h),
nn.Dropout(0.5), # 50 % probability
nn.ReLU(),
torch.nn.Linear(N_h, N_h),
nn.Dropout(0.2), # 20% probability
nn.ReLU(),
torch.nn.Linear(N_h, 1),
)
optimizer_dropout = torch.optim.Adam(model_dropout.parameters(), lr=0.01)
num_epochs = 1500
criterion = torch.nn.MSELoss()
for epoch in range(num_epochs):
# train without dropout
y_pred = model(x_train) # look at the entire data in a single shot
loss = criterion(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# train with dropout
y_pred_dropout = model_dropout(x_train)
loss_dropout = criterion(y_pred_dropout, y_train)
optimizer_dropout.zero_grad()
loss_dropout.backward()
optimizer_dropout.step()
if epoch % 300 == 0:
model.eval() # not train mode
model_dropout.eval() # not train mode
# get predictions
y_test_pred = model(x_test)
test_loss = criterion(y_test_pred, y_test)
y_test_pred_dropout = model_dropout(x_test)
test_loss_dropout = criterion(y_test_pred_dropout, y_test)
# plotting data and predictions
plt.scatter(
x_train.data.numpy(),
y_train.data.numpy(),
c="purple",
alpha=0.5,
label="train",
)
plt.scatter(
x_test.data.numpy(),
y_test.data.numpy(),
c="yellow",
alpha=0.5,
label="test",
)
plt.plot(
x_test.data.numpy(), y_test_pred.data.numpy(), "r-", lw=3, label="normal"
)
plt.plot(
x_test.data.numpy(),
y_test_pred_dropout.data.numpy(),
"b--",
lw=3,
label="dropout",
)
plt.title(
"Epoch %d, Loss = %0.4f, Loss with dropout = %0.4f"
% (epoch, test_loss, test_loss_dropout)
)
plt.legend()
model.train() # train mode
model_dropout.train() # train mode
plt.pause(0.05)





Видим, что нейросеть без Dropout сильно переобучилась.
Можно, используя нейросеть с Dropout, получить доверительный интервал для нашего предсказания (как делали в лекции по ML). Просто не "замораживаем" dropout-слои во время предсказания, а делаем предсказания с активными dropout.
Делаем предсказание для каждого объекта 1000 раз, после чего получаем распределение предсказаний, на основе которого можно делать доверительные интервалы и ловить аномалии — те объекты, на которых нейросеть вообще не понимает, что ей делать, и потому предсказывает метку или еще что-то с сильной дисперсией.

Если занулять не нейроны (активации), а случайные веса с вероятностью $p$, получится DropConnect.
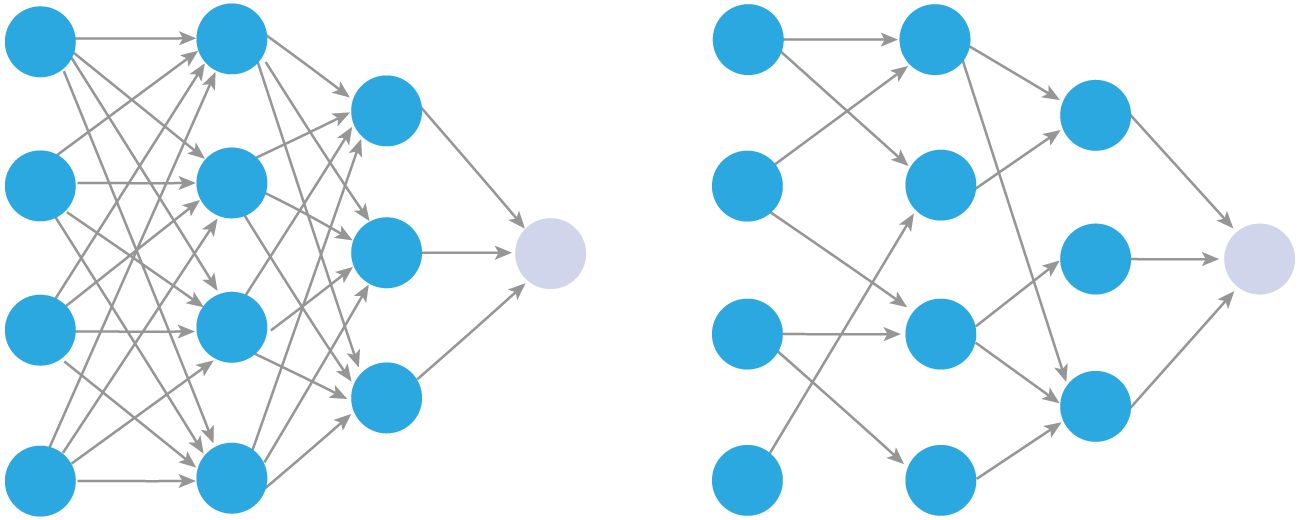
DropConnect похож на Dropout, поскольку он вводит динамическую разреженность в модель, но отличается тем, что разреженность зависит от весов W, а не от выходных векторов слоя. Другими словами, полностью связанный слой с DropConnect становится разреженно связанным слоем, в котором соединения выбираются случайным образом на этапе обучения.
В принципе, вариантов зануления чего-то в нейронной сети можно предложить великое множество, в разных ситуациях будут работать разные способы (в этом списке 🎓[article] много Drop...).
Например, можно убирать для каждого батча из нейросети случайные блоки из слоев. И это будет работать!
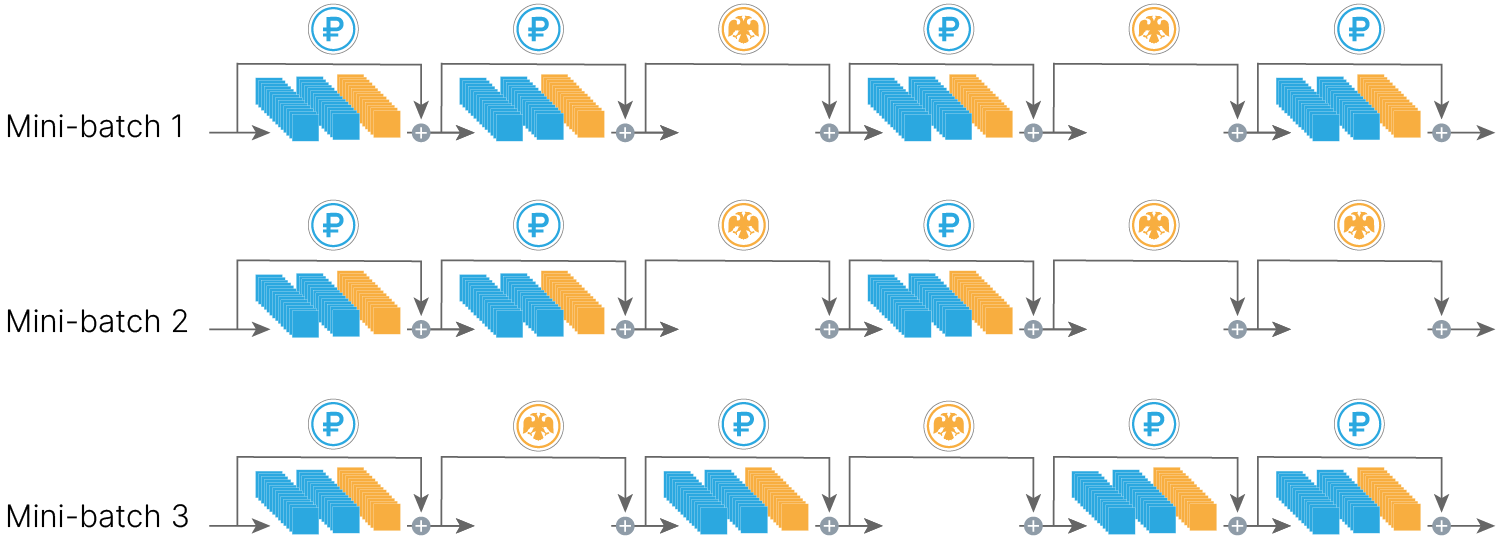
Подробно:

В процессе обучения мы пытаемся подобрать параметры модели, при которых она будет работать лучше всего. Это — оптимизационная задача (задача подбора оптимальных параметров). Мы уже ознакомились с одним алгоритмом оптимизации параметров — градиентным спуском.
Существует множество алгоритмов оптимизации, которые можно применять для поиска минимума функционала ошибки (неполный список 🎓[article]). Эти алгоритмы реализованы в модуле torch.optim 🛠️[doc].
Важно отметить, что выбор оптимизатора не влияет на расчет градиента. Градиент в PyTorch вычисляется автоматически на основе графа вычислений.
При градиентном спуске мы:
домножая антиградиент на постоянный коэффициент $\text{lr}$ (гиперпараметр обучения — learning rate).
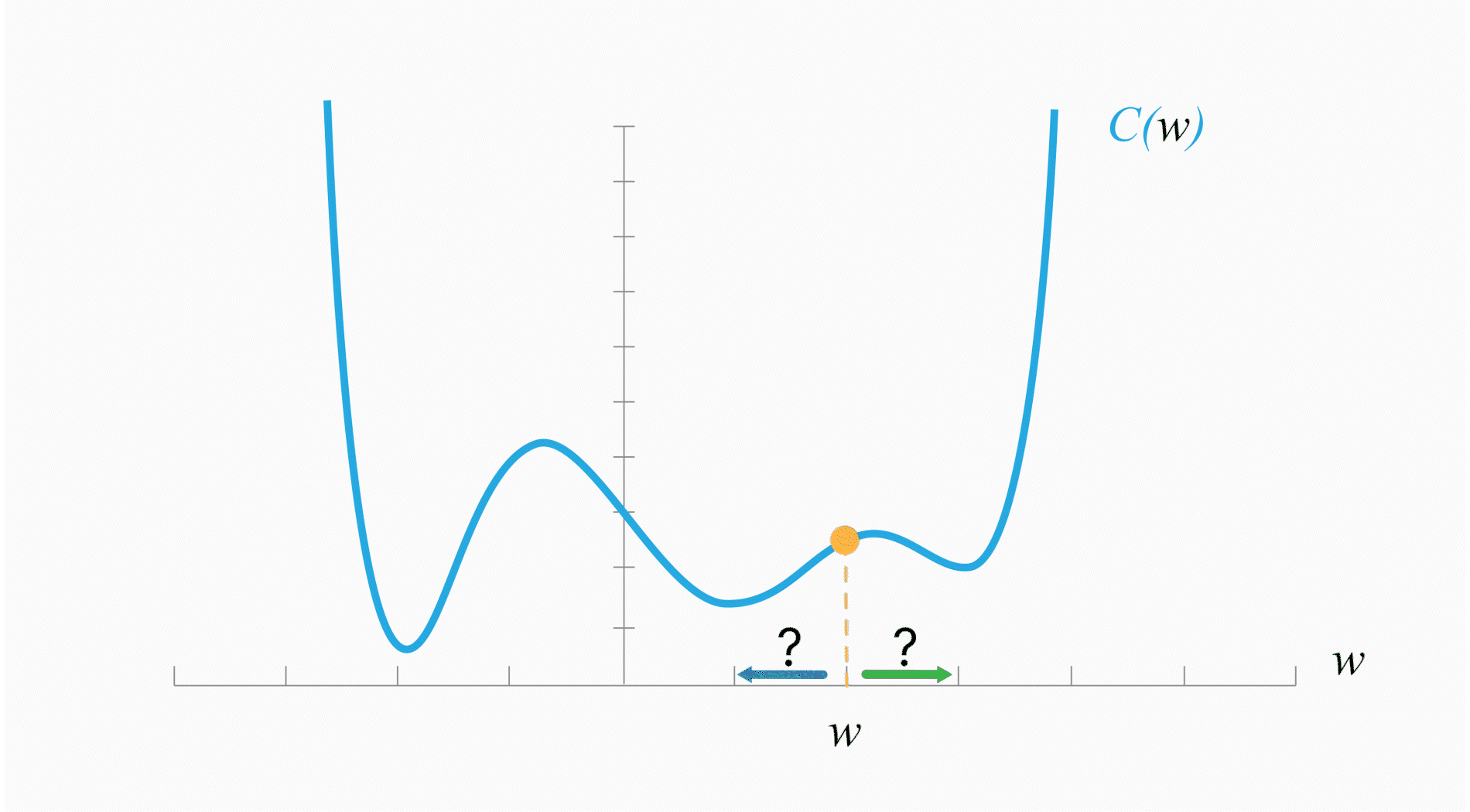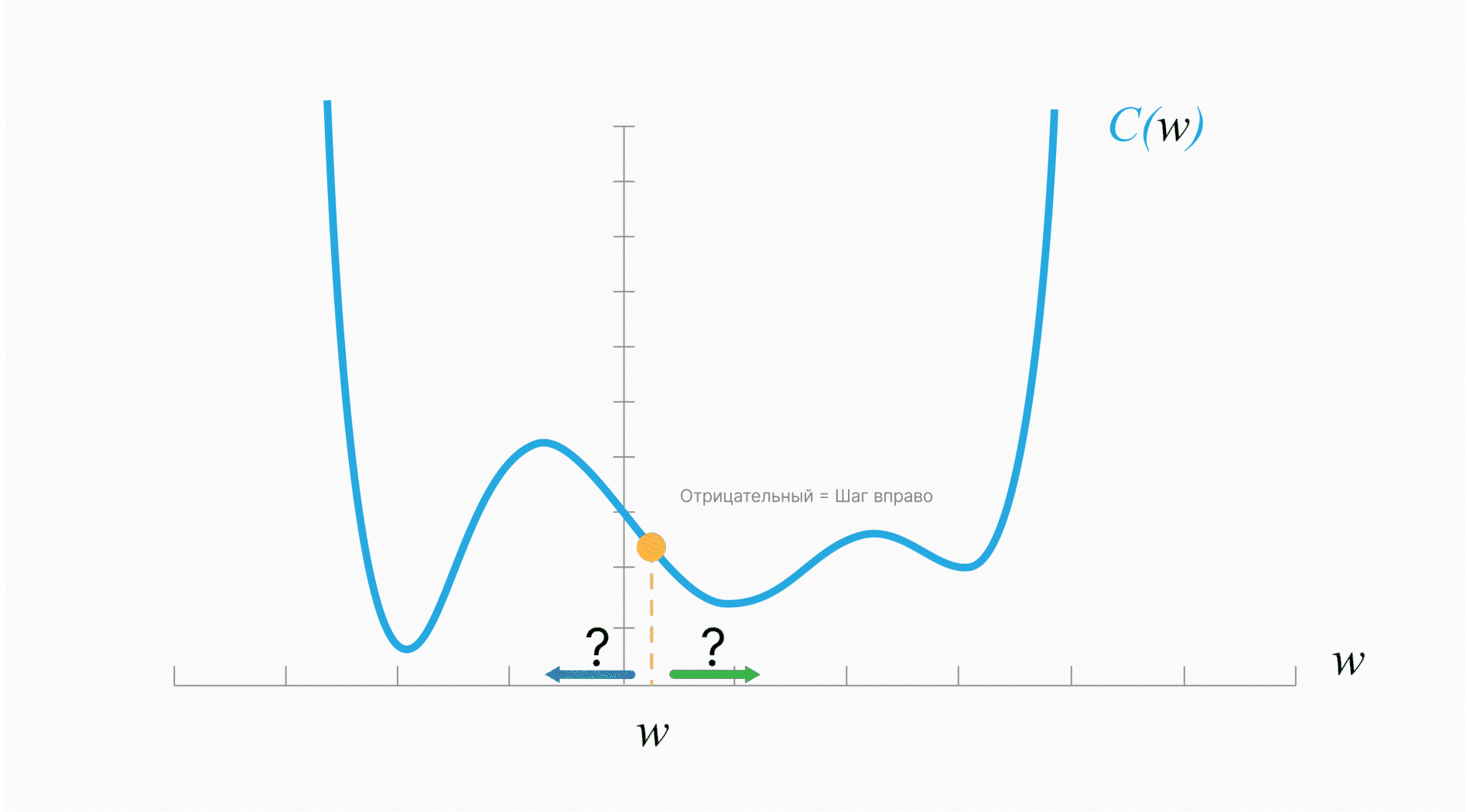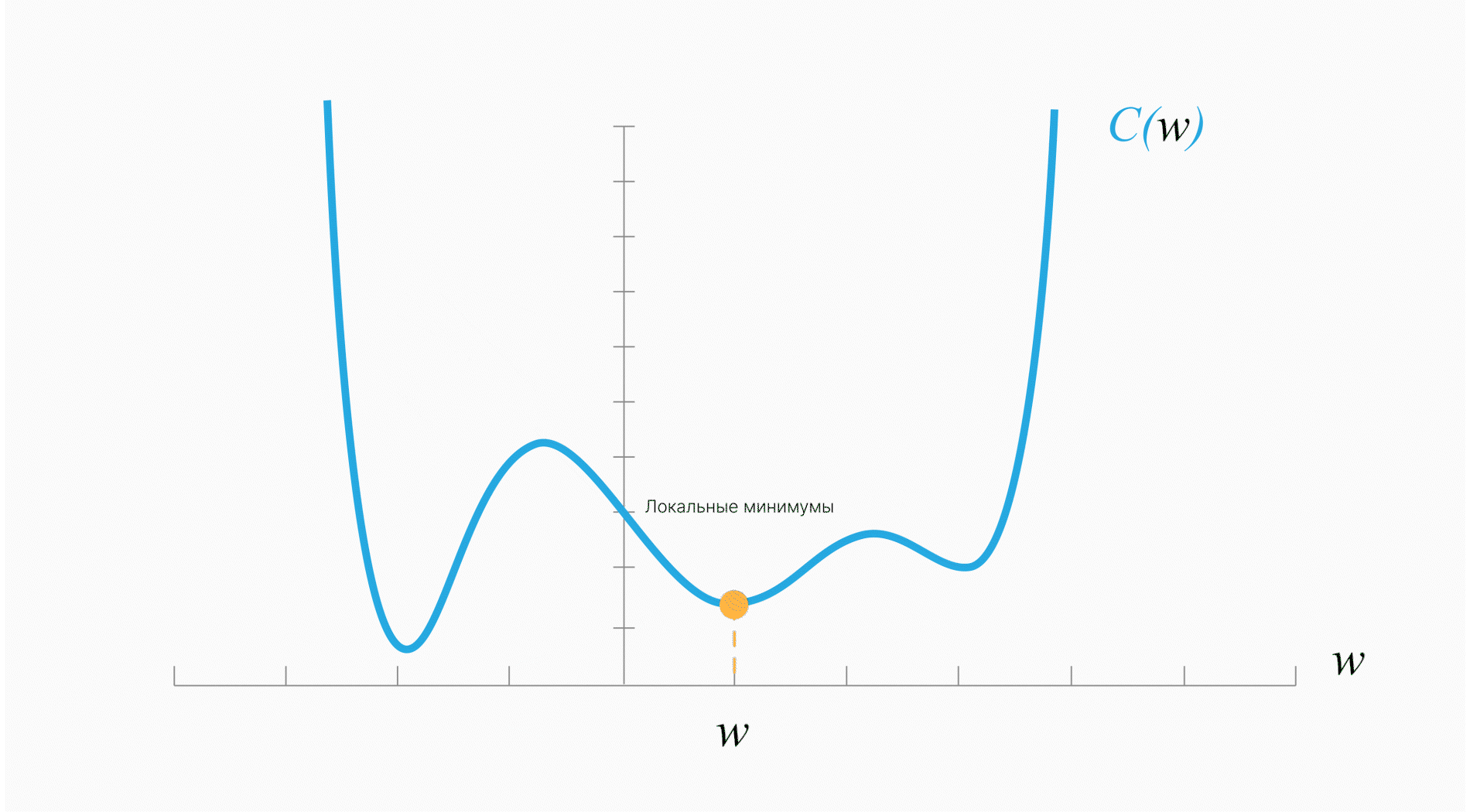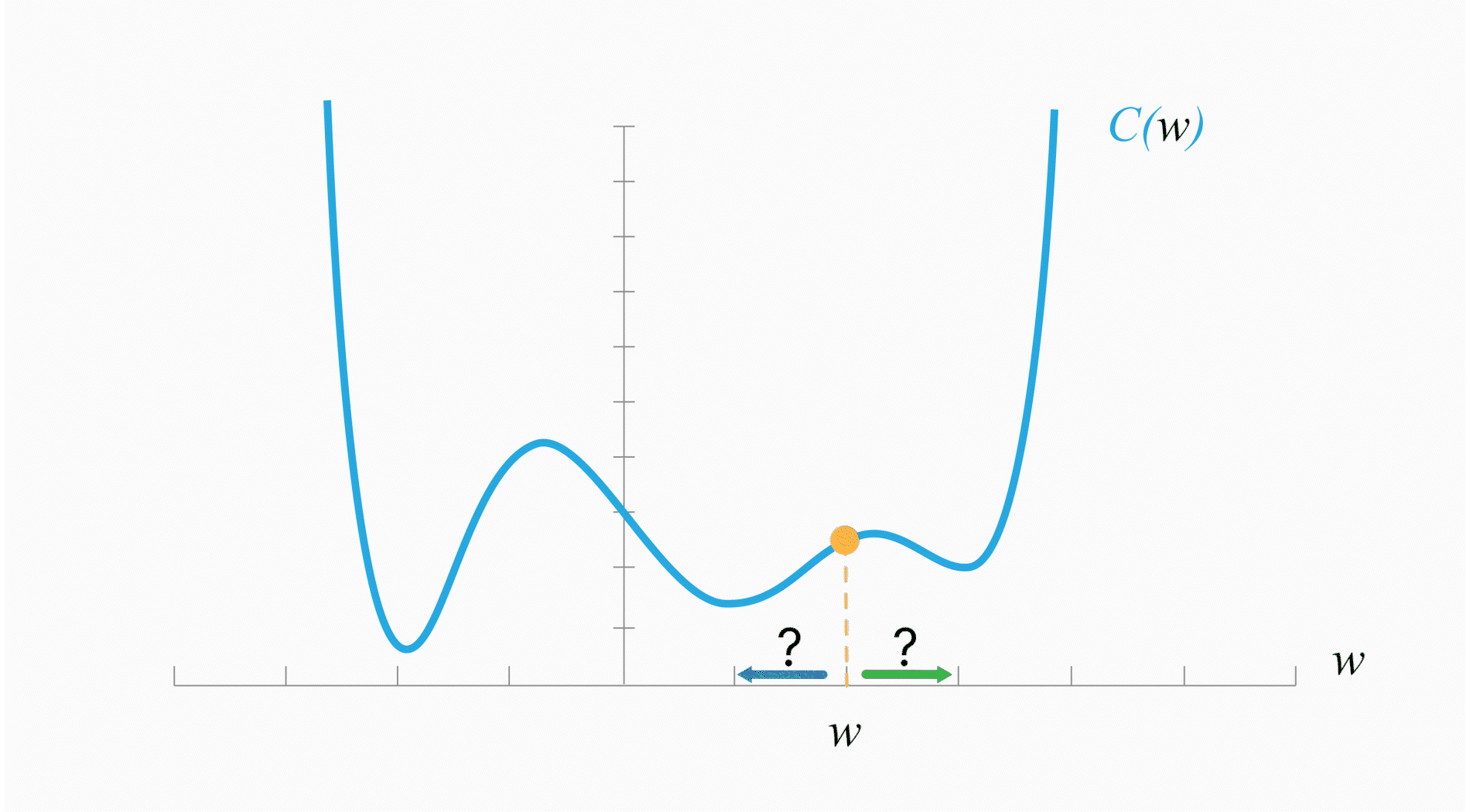
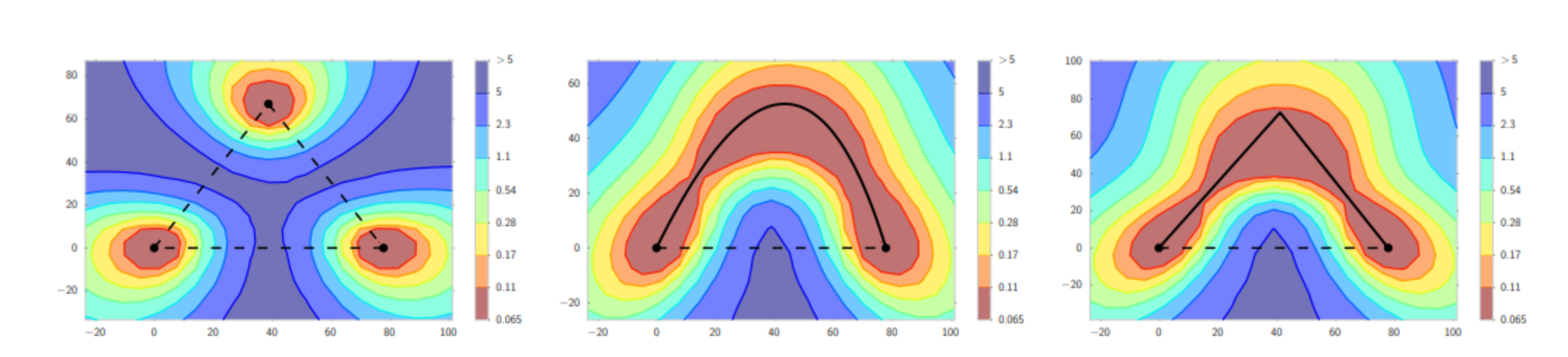
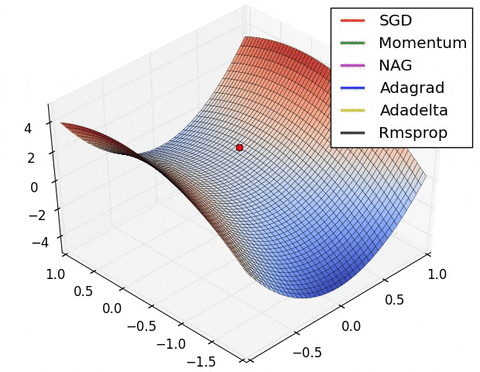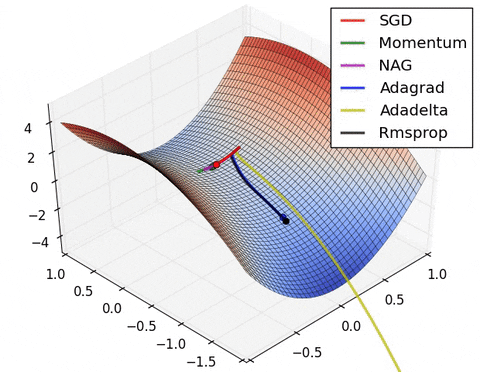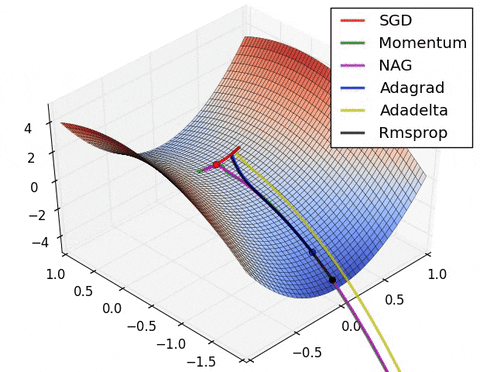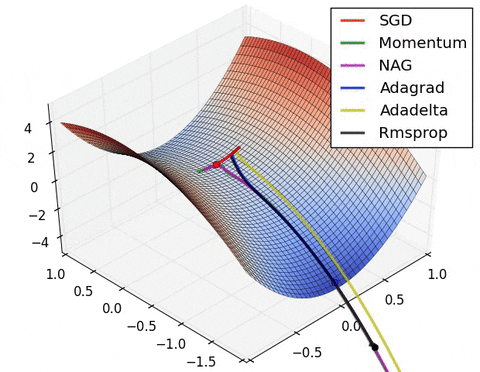
У данного алгоритма есть проблема: он может застревать в локальных минимумах или даже седловых точках.
Cедловые точки — точки, в которых все производные равны $0$, но они не являются экстремумами. В них градиент равен $0$, веса не обновляются — оптимизация останавливается.
Пример таких точек:
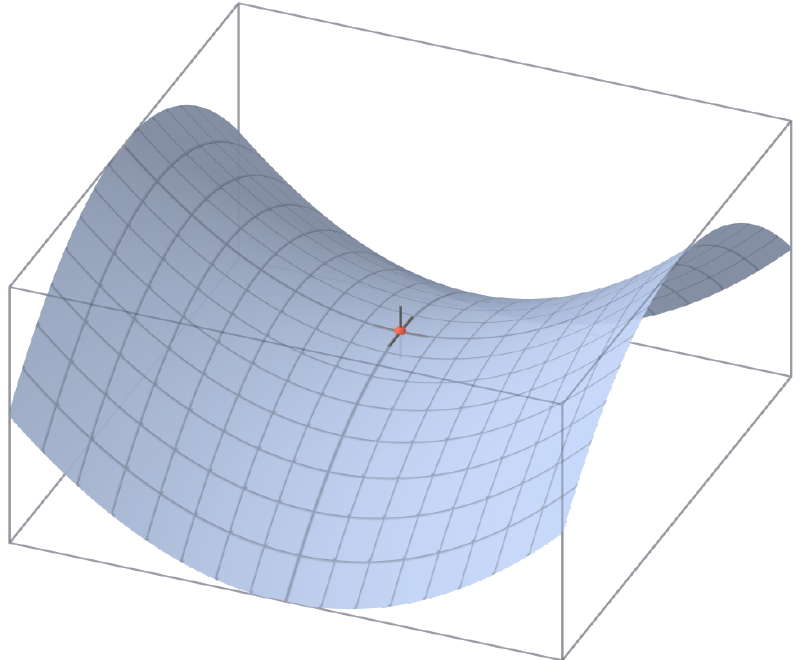
Частично эту проблему решает стохастический градиентный спуск (stochastic gradient descent, SGD). В нем для градиентного спуска используются не все данные, а некоторая подвыборка (mini-batch) или даже один элемент.
SGD обладает важной особенностью: на каждом объекте или подвыборке (mini-batch) ландшафт функции потерь выглядит по-разному. Некоторые минимумы функции потерь и седловые точки могут быть характерны лишь для части объектов.
Ниже упрощенно показаны ландшафты функции потерь на полном датасете и на отдельных батчах. При оптимизации на полном датасете модель могла бы остановиться в левом локальном минимуме, но стохастическая природа спуска позволяет избежать этого за счет того, что для некоторых батчей этот минимум отсутствует.
В результате модель сможет остановиться только в каком-то относительно широком и глубоком минимуме, характерном для большинства батчей обучающих данных. С большой вероятностью этот минимум будет присутствовать и на реальных данных, то есть модель сможет адекватно работать с ними.

SGD до сих пор является достаточно популярным методом обучения нейросетей, потому что он простой, не требует подбора дополнительных гиперпараметров, кроме скорости обучения lr, и сам по себе обычно дает неплохие результаты.
Если же модель учится слишком долго и/или важна каждая сотая в качестве, то нужно либо использовать его в совокупности с другими техниками (их рассмотрим далее), либо использовать другие способы.
Фрагмент кода для понимания работы SGD:
class SGD:
def __init__(self, parameters, lr):
self.parameters = parameters
self.lr = lr
def step(self):
d_parameters = self.parameters.grad
self.parameters -= self.lr*d_parametersАлгоритм SGD реализован в torch.optim.SGD 🛠️[doc]
import torch.optim as optim
parameters = torch.randn(10, requires_grad=True)
optimizer = optim.SGD(model.parameters(), lr=0.001)
Минусы SGD:
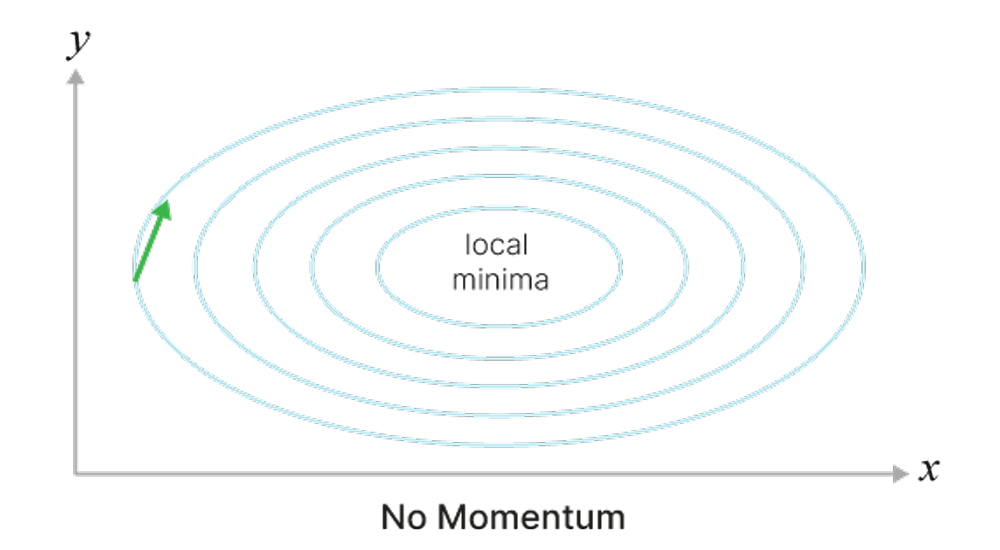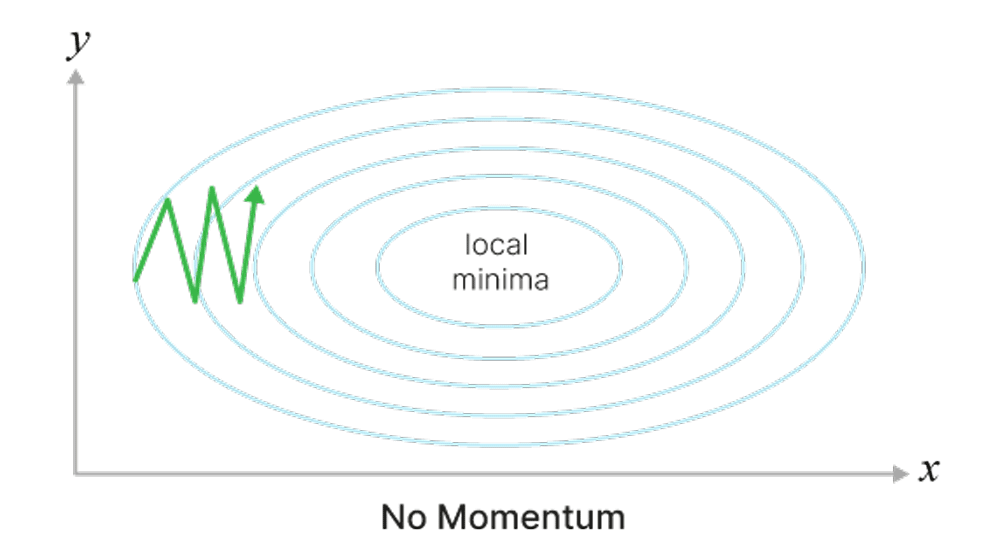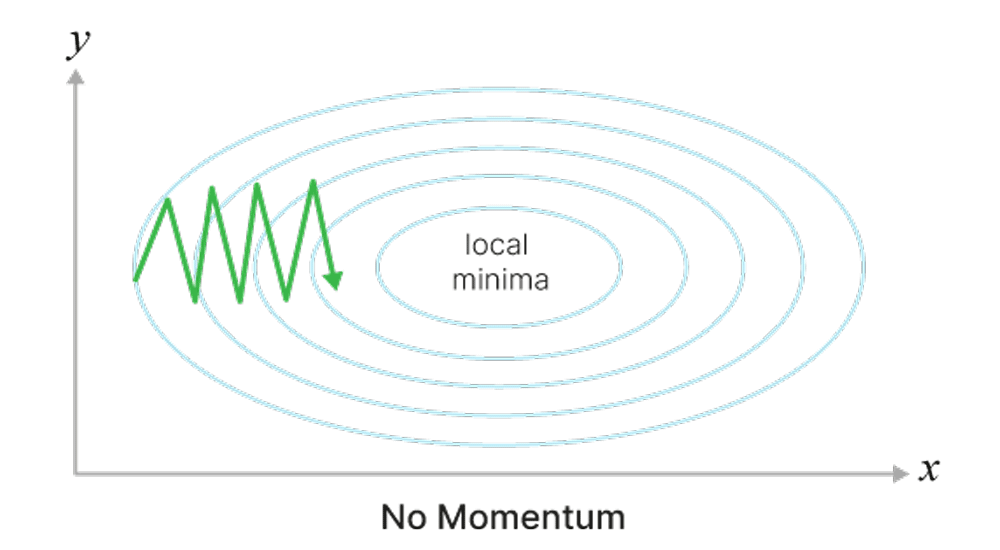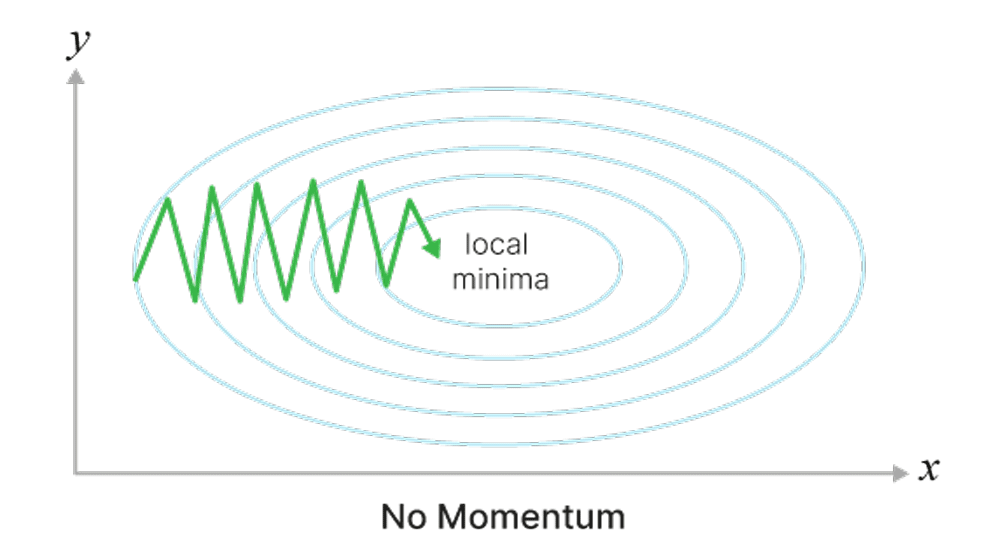
Может застревать в локальных минимумах или седловых точках.
Мы оцениваем градиент по малым частям выборки, которые могут плохо отображать градиент по всей выборке и являться шумными. В результате часть шагов градиентного спуска делается впустую или во вред.
Мы применяем один и тот же learning rate ко всем параметрам, что не всегда разумно. Параметр, отвечающий редкому классу, будет обучаться медленнее остальных.
Просто медленнее сходится.
SGD является основой всех описанных ниже алгоритмов.
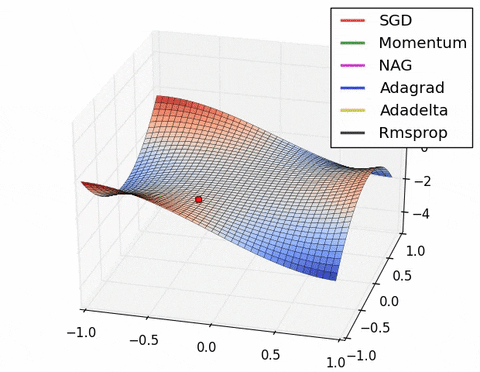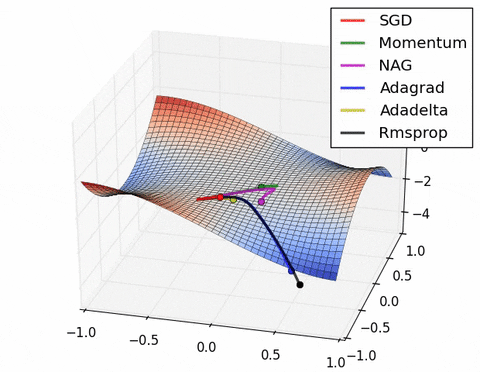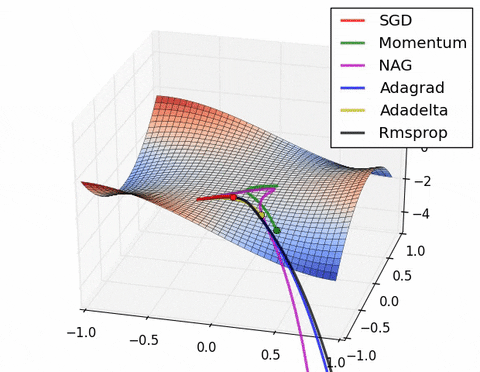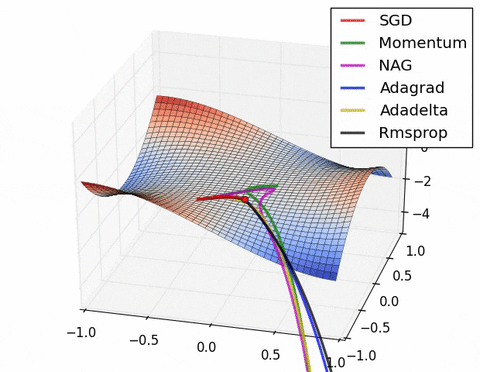
Чтобы избежать проблем 1–3, можно добавить движению по ландшафту функции ошибок инерцию (momentum). По аналогии с реальной жизнью: если мяч катится с горки, то он благодаря инерции может проскочить пологое место или даже небольшую яму.
Корректируем направление движения шарика с учетом текущего градиента:
$$v_{t} = m \cdot v_{t-1} + \nabla_wL(x, y, w_{t})$$где $m \in [0, 1)$ — momentum (гиперпараметр).
Вычисляем, куда он покатится:
$$w_{t+1} = w_t - \text{lr} \cdot v_{t}$$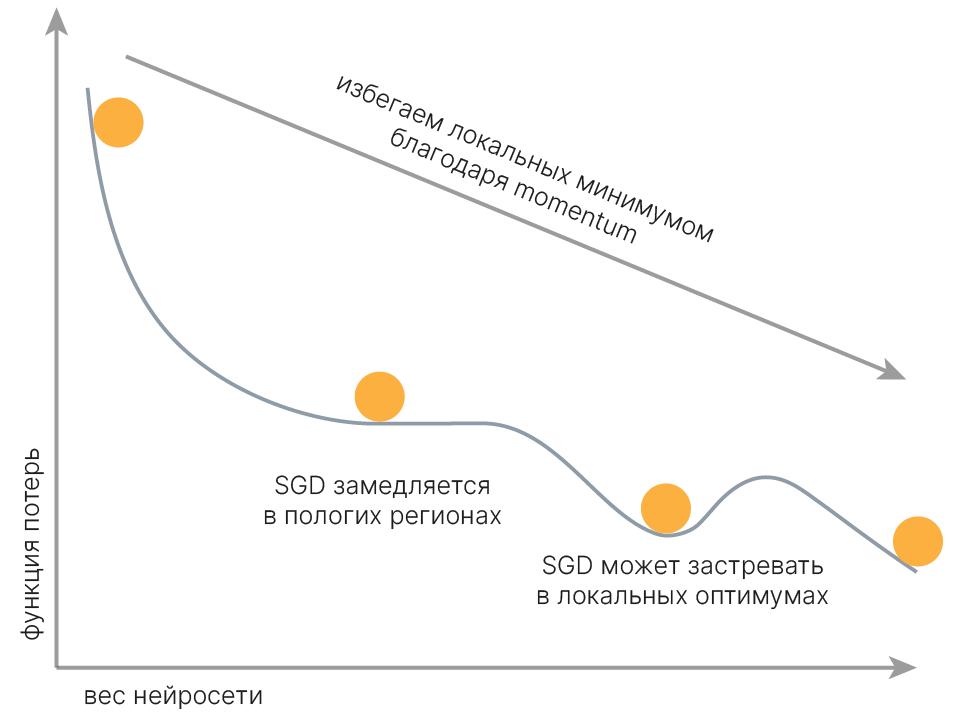
Теперь мы быстрее достигаем локального минимума и можем выкатываться из совсем неглубоких. Градиент стал менее подвержен шуму, меньше осциллирует
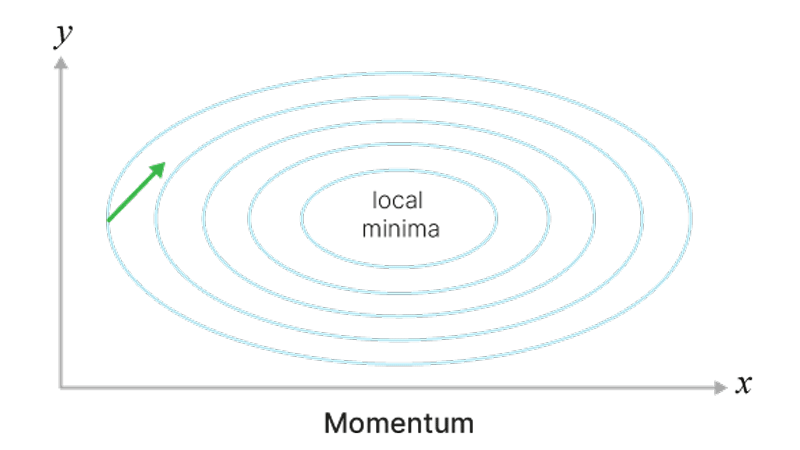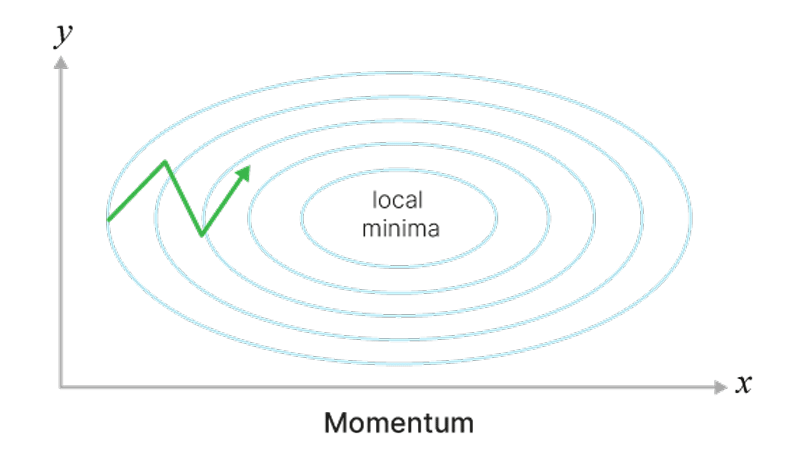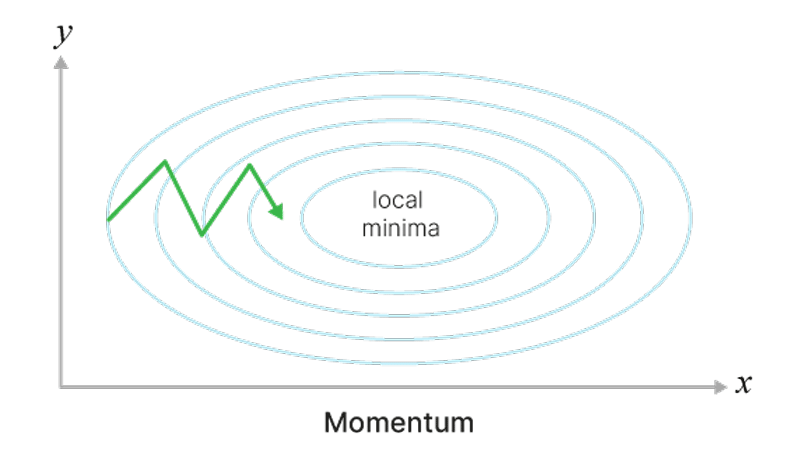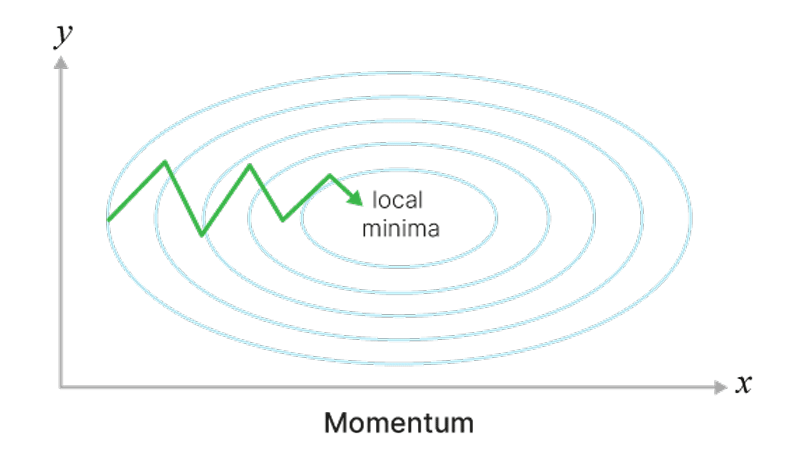
Фрагмент кода для понимания работы Momentum:
class SGD_with_momentum:
def __init__(self, parameters, momentum, lr):
self.parameters = parameters
self.momentum = momentum
self.lr = lr
self.velocity = torch.zeros_like(parameters)
def step(self):
d_parameters = self.parameters.grad
self.velocity = self.momentum*self.velocity + d_parameters
self.weights -= self.lr*self.velocityMomentum удваивает количество хранимых параметров.
Алгоритм Momentum реализован в torch.optim.SGD 🛠️[doc]:
parameters = torch.randn(10, requires_grad=True)
optimizer = optim.SGD(model.parameters(), momentum=0.9, lr=0.001)
У этого подхода есть одна опасность — мы можем выкатиться за пределы минимума, к которому стремимся, а потом какое-то время к нему возвращаться.

Source: Why Momentum Really Works
Чтобы с этим бороться, предложен другой способ подсчета инерции
Будем сначала смещаться в сторону, куда привел бы нас накопленный градиент, там считать новый градиент и смещаться по нему. В результате перескоки через минимум будут менее значительными, и алгоритм будет быстрее сходиться:
$$\large v_{t} = m \cdot v_{t-1} + \nabla_w L(w_t - \text{lr} \cdot m \cdot v_{t-1} )$$$$\large w_{t+1} = w_{t} - \text{lr} \cdot v_{t} $$
Кажется, что для реализации такого алгоритма необходимо пересчитывать прямой и обратный проход с новыми параметрами, для вычисления градиента. На практике эту формулу можно переписать 🎓[article] так, чтобы не пересчитывать градиент.
С псевдокодом, описывающим последовательность действий NAG, можно познакомиться в PyTorch 🛠️[doc].
Так же, как momentum, Nesterov momentum удваивает количество хранимых параметров.
Алгоритм Nesterov momentum реализован в torch.optim.SGD 🛠️[doc]:
parameters = torch.randn(10, requires_grad=True)
optimizer = optim.SGD(model.parameters(), momentum=0.9, nesterov=True, lr=0.001)
Описанные алгоритмы не борются с 4-ой проблемой SGD: "мы применяем один и тот же learning rate ко всем параметрам, что не всегда разумно. Параметр, отвечающий редкому классу, будет обучаться медленнее остальных".
Пример: мы решаем задачу классификации картинок из Интернета, и у нас есть параметры, ответственные за признаки, которые характеризуют кошек породы сфинкс. Кошки породы сфинкс встречаются в нашем датасете редко, и эти параметры реже получают информацию для обновления. Поэтому наша модель может хуже классифицировать кошек этой породы.
Для решения этой проблемы мы можем завести для каждого параметра индивидуальный learning rate, зависящий от того, как часто и как сильно изменяется этот параметр в процессе обучения.
Будем хранить для каждого параметра сумму квадратов его градиентов (запоминаем, как часто и как сильно он изменялся).
И будем вычитать из значений параметров градиент с коэффициентом, обратно пропорциональным корню из этой суммы $G_t$.
$e$ — малая константа, чтобы не допускать деления на ноль, $\odot$ — поэлементное умножение.
В результате, если градиент у нашего веса часто большой, коэффициент будет уменьшаться.
Проблема заключается в том, что при такой формуле learning rate неминуемо в конце концов затухает (так как сумма квадратов не убывает).
Фрагмент кода для понимания работы Adagrad:
class AdaGrad:
def __init__(self, parameters, lr=0.01):
self.parameters = parameters
self.lr = lr
self.grad_squared = torch.zeros_like(parameters)
def step(self):
d_parameters = self.parameters.grad
self.grad_squared += d_parameters*d_parameters
self.parameters -= self.lr*d_parameters / (torch.sqrt(self.grad_squared) + 1e-7)Adagrad удваивает количество хранимых параметров
Алгоритм Adagrad реализован в torch.optim.Adagrad 🛠️[doc]:
parameters = torch.randn(10, requires_grad=True)
optimizer = optim.Adagrad(model.parameters(), lr=0.01)
Добавим "забывание" предыдущих квадратов градиентов. Теперь мы считаем не сумму квадратов, а экспоненциальное скользящее среднее 📚[wiki] с коэффициентом $\alpha$.
$$G_t = \alpha \cdot G_{t-1} + (1-\alpha) \cdot \nabla_w L(x,y,w_t) \odot \nabla_w L(x,y,w_t)$$$$w_{t+1} = w_{t} - \frac{lr}{\sqrt{G_t }+ e} \odot \nabla_w L(x,y,w_t)$$Фрагмент кода для понимания работы RMSprop:
class RMSprop():
def __init__(self, parameters, lr=0.01, alpha=0.99):
self.parameters = parameters
self.lr = lr
self.alpha = alpha
self.grad_squared = torch.zeros_like(parameters)
def step(self):
d_parameters = self.parameters.grad
self.grad_squared = self.alpha*self.grad_squared + \
(1 - self.alpha)*d_parameters*d_parameters
self.parameters -= self.lr*d_parameters / (torch.sqrt(self.grad_squared) + 1e-7)Так же, как Adagrad, RMSprop удваивает количество хранимых параметров
Алгоритм RMSprop реализован в torch.optim.RMSprop 🛠️[doc]:
parameters = torch.randn(10, requires_grad=True)
optimizer = optim.RMSprop(model.parameters(), lr=0.01, alpha=0.99)
Одним из самых популярных адаптивных оптимизаторов является Adam, объединяющий идеи momentum и adaptive learning rate:
$$ v_t = \beta_1 \cdot v_{t-1} + (1-\beta_1) \cdot \nabla_w L(x,y,w_t) $$$$ G_t = \beta_2 \cdot G_{t-1} + (1-\beta_2) \cdot \nabla_w L(x,y,w_t) \odot \nabla_w L(x,y,w_t) $$$$ w_{t+1} = w_t - \frac{\text{lr}}{\sqrt{G_t} + e} \odot v_t$$где $\beta_1$ — аналог $m$ из Momentum, а $\beta_2$ — аналог $\alpha$ из RMSprop.
Фрагмент кода для понимания работы Adam:
class Adam:
def __init__(self, parameters, lr=0.01, betas=(0.9, 0.999)):
self.parameters = parameters
self.lr = lr
self.betas = betas
self.velocity = torch.zeros_like(parameters)
self.grad_squared = torch.zeros_like(parameters)
self.beta_1 = betas[0] # momentum
self.beta_2 = betas[1] # alpha
def step(self):
d_parameters = self.parameters.grad
# momentum
self.velocity = self.beta_1*self.velocity + (1 - self.beta_1)*d_parameters
# adaptive learning rate
self.grad_squared = self.beta_2*self.grad_squared + \
(1 - self.beta_2)*d_parameters*d_parameters
self.parameters -= self.lr*self.velocity / (torch.sqrt(self.grad_squared) + 1e-7)Adam утраивает количество хранимых параметров
Чтобы в начале у нас получались очень большие шаги, будем дополнительно модицифировать инерцию и сумму квадратов:
Алгоритм Adam реализован в torch.optim.Adam 🛠️[doc]:
parameters = torch.randn(10, requires_grad=True)
optimizer = optim.Adam([parameters], betas=(0.9, 0.999))
Пример применения:
model_name = "adam"
model = SimpleMNIST_NN_Init_Batchnorm(n_layers=3)
trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = Pipeline(
model=model,
exp_name=model_name,
optimizer_class=torch.optim.Adam,
optimizer_kwargs={"lr": 1e-2},
)
trainer.fit(model=pipeline, train_dataloaders=train_loader, val_dataloaders=test_loader)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/adam/lightning_logs INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ------------------------------------------------------------ 0 | model | SimpleMNIST_NN_Init_Batchnorm | 100 K 1 | criterion | CrossEntropyLoss | 0 ------------------------------------------------------------ 100 K Trainable params 0 Non-trainable params 100 K Total params 0.400 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.plot(["batchnorm2", "batchnorm_increased_lr", model_name])

Для использования L2 c оптимизатором необходимо указать значение weight_decay, где weight_decay — коэффициент перед L2.
parameters = torch.randn(10, requires_grad=True)
optimizer = optim.RMSprop([parameters], alpha=0.99, weight_decay=0.001)
Вообще говоря, Weight decay и L2 — это немного разные вещи.
L2 добавляет член регуляризации к Loss функции:
$$\text{Loss}_{L2} = \text{Loss} + \frac{λ}{2n}w^2$$Weight decay уменьшает веса:
$$w_{wd} = w - \frac{λ}{n}w$$где $λ$ — константа, а $n$ — количество элементов в батче.
Для SGD оптимизатора Weight decay и L2 эквивалентны, но не для всех оптимизаторов это так.
Например, это не так для Adam. L2 регуляризация прибавляется к Loss функции и изменяет значение градиента, квадраты которого будут храниться. Weight decay изменяет только веса. Подробно об этом можно почитать в:
[arxiv] 🎓 Decoupled Weight Decay Regularization (Loshchilov, Hutter, 2019)
Обратите внимание, что weight_decay в torch.optim.Adam — это коэффициент перед L2. Weight decay для Adam реализовано в
torch.optim.AdamW.
Не Adam-ом единым живут нейронные сети. Есть альтернативные методы оптимизации, например, проект Google Brain ✏️[blog] в 2023 году опубликовал статью 🎓[arxiv], в которой описывает найденный в процессе AutoML 🎓[arxiv] (автоматического подбора архитектур и алгоритмов) оптимизатор, названный Lion (EvoLved Sign Momentum) 🦁.
Интересно, что AutoML алгоритм пришел к интуитивно понятной эвристике: градиенты — вещь не очень надежная. Они могут взрываться и затухать. Может, тогда мы зафиксируем размер шага, а градиенты будем использовать только для определения направления?
Для определения направления используют функцию $\text{sign}$ (знак):
\begin{align} \text{sign}(x) = \left\{ \begin{array}{cl} 1 & x > 0 \\ 0 & x = 0\\ -1 & x < 0. \end{array} \right. \end{align}К этому добавляется уже изученный нами momentum, чтобы знак “прыгал” реже. Интересно, что AutoML подобрал алгоритм, в котором используются две константы для momentum. $\beta_1$ — для определения текущего знака градиента, $\beta_2$ — для хранения значения $v_t$. Значения по умолчанию $\beta_1 = 0.9$, $\beta_2 = 0.99$. Это значит, что текущее значение градиента сильнее влияет на значение для выбора направления текущего шага $c_{t}$, чем на хранимое значение момента $v_t$.
Значение для вычисления направления текущего шага:
$$c_{t} = \beta_1 \cdot v_{t-1} + (1-\beta_1) \nabla_wL(x, y, w_{t})$$Шаг оптимизатора. $λ$ — константа weight decay:
$$w_{t+1} = w_t - \text{lr} \cdot (\text{sign}(c_t) +λ w_t)$$Обновление хранимого значения момента:
$$v_t = \beta_2 \cdot v_{t-1} + (1-\beta_2) \nabla_wL(x, y, w_{t})$$Фрагмент кода для понимания работы Lion:
class Lion:
def __init__(self, parameters, lr=0.0001, betas=(0.9, 0.99), weight_decay=0.01):
self.parameters = parameters
self.lr = lr
self.betas = betas
self.velocity = torch.zeros_like(parameters)
self.beta_1 = betas[0] # momentum 1
self.beta_2 = betas[1] # momentum 2
self.weight_decay = weight_decay
def step(self):
d_parameters = self.parameters.grad
# current momentum
current = self.beta_1*self.velocity + (1 - self.beta_1)*d_parameters
# step
self.parameters -= self.lr*(torch.sign(carent)+self.weight_decay*self.parameters)
# history momentum
self.velocity = self.beta_2*self.velocity + (1 - self.beta_2)*d_parametersLion удваивает количество хранимых параметров
Обратите внимание, что значение lr по умолчанию у Lion выбрано меньше, чем у Adam. Это связано с тем, что только lr и регуляризация определяют размер шага. Авторы статьи советуют брать для Lion в 10 раз меньший lr, чем для Adam.
У Lion есть преимущества по сравнению с Adam и AdamW: в нем нет необходимости хранить квадраты градиентов. Он позволяет снизить количество хранимых параметров в 1.5–2 раза по сравнению с AdamW, а также сокращает количество операций, что позволяет ускорить расчеты на 2–15% 🎓[arxiv] (в Colab это не заметно из-за специфики, связанной с виртуальными машинами).
Кроме того, Lion позволяет добиться лучших результатов 🐾[git], чем AdamW, при обучении больших сложных моделей, таких как Visual Transformer-ы и диффузионные модели.
Но до сложных моделей мы пока не добрались, попробуем простую. Воспользуемся реализацией Lion-Pytorch 🐾[git]:
!pip install -q lion-pytorch
from lion_pytorch import Lion
model_name = "lion"
model = SimpleMNIST_NN_Init_Batchnorm(n_layers=3)
trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = Pipeline(
model=model,
exp_name=model_name,
optimizer_class=Lion,
optimizer_kwargs={"lr": 1e-4, "weight_decay": 1e-3},
)
trainer.fit(model=pipeline, train_dataloaders=train_loader, val_dataloaders=test_loader)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/lion/lightning_logs INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] INFO:pytorch_lightning.callbacks.model_summary: | Name | Type | Params ------------------------------------------------------------ 0 | model | SimpleMNIST_NN_Init_Batchnorm | 100 K 1 | criterion | CrossEntropyLoss | 0 ------------------------------------------------------------ 100 K Trainable params 0 Non-trainable params 100 K Total params 0.400 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.plot(["adam", model_name])

Результат получился почти как у Adam, число хранимых параметров меньше.
Существует исследование 🎓[article], которое показывает, что ландшафт функции потерь представляет собой не изолированные локальные минимумы (рисунок слева), а связанные области с почти постоянным значением (рисунок справа). Поэтому умение “выбираться” из седловых точек важно.
У каждого из предложенных оптимизаторов есть минусы и плюсы
Нам не обязательно поддерживать один и тот же learning rate в течение всего обучения. Более того, для того же SGD есть гарантии, что если правильно подобрать схему уменьшения learning rate, он сойдется к глобальному оптимуму.
Мы можем менять learning rate по некоторым правилам.
Можем использовать критерий ранней остановки: когда значение функции потерь на валидационной выборке не улучшается какое-то количество эпох(patience), умножаем learning rate на некое значение factor).
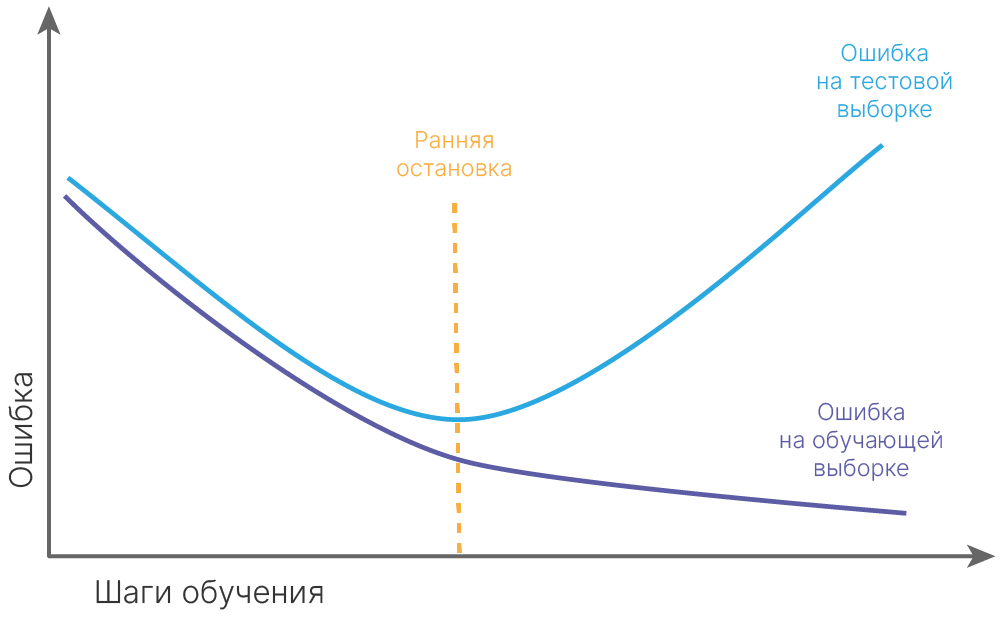
optimizer = optim.SGD(model.parameters(), lr=0.1)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, "min", factor=0.1, patience=5
)
Применим к нашей модели
(выполнение занимает ~ 5 минут)
Реализуем ниже код для обучения модели на чистом PyTorch, чтобы разобраться с тем, как именно планировщик обучения встроен в алгоритм обучения.
Отказавшись временно от Lightning, мы должны будем явно перемещать объекты между CPU и GPU, а также следить за тем, что мы верно выбрали режим работы model.train() или model.eval().
# compute on cpu or gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def validate(model, criterion, val_loader):
cumloss = 0
loss_history = []
with torch.no_grad():
for batch in val_loader:
x_train, y_train = batch # parse data
x_train, y_train = x_train.to(device), y_train.to(device) # compute on gpu
y_pred = model(x_train) # get predictions
loss = criterion(y_pred, y_train) # compute loss
loss_history.append(loss.cpu().detach().item()) # write loss to log
cumloss += loss
return cumloss / len(val_loader), loss_history # mean loss and history
def train_epoch(model, optimizer, criterion, train_loader):
loss_history = []
for batch in train_loader:
optimizer.zero_grad()
x_train, y_train = batch # parse data
x_train, y_train = x_train.to(device), y_train.to(device) # compute on gpu
y_pred = model(x_train) # get predictions
loss = criterion(y_pred, y_train) # compute loss
loss_history.append(loss.cpu().detach().item()) # write loss to log
loss.backward()
optimizer.step()
return loss_history
from tqdm.notebook import tqdm
def train_model_sep_scheduler(
model, optimizer, scheduler, model_name=None, num_epochs=5
):
criterion = nn.CrossEntropyLoss().to(device)
train_history = {}
train_history["model_name"] = model_name
train_history["epoсhs"] = num_epochs
train_history["loss_on_train"] = []
train_history["loss_on_test"] = []
for epoch in tqdm(range(num_epochs)):
model.train()
loss_on_train = train_epoch(model, optimizer, criterion, train_loader)
model.eval()
val_loss, loss_on_test = validate(model, criterion, test_loader)
train_history["loss_on_train"].extend(loss_on_train)
train_history["loss_on_test"].extend(loss_on_test)
scheduler.step(val_loss)
return train_history
model = SimpleMNIST_NN_Init_Batchnorm(n_layers=3).to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-2)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, "min", factor=0.1, patience=1
)
model_name = "reduce_lr_on_plateu"
history = train_model_sep_scheduler(
model, optimizer, scheduler, model_name=model_name, num_epochs=5
)
0%| | 0/5 [00:00<?, ?it/s]
history_plotter.add(history)
history_plotter.plot([model_name])

Для реализации работы планировщика обучения ReduceLROnPlateau в рамках PyTorch Lightning нам достаточно переопределить метод configure_optimizers и указать, за значением какой логируемой переменной необходимо "следить" во время обучения. Вся остальная логика будет выполнена Lightning автоматически.
class PipelineWithScheduler(Pipeline):
def configure_optimizers(self):
optimizer = self.optimizer_class(
self.model.parameters(), **self.optimizer_kwargs
)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer=optimizer,
min_lr=1e-9,
factor=0.1,
mode="min",
verbose=True,
)
lr_scheduler = {
"scheduler": scheduler,
"interval": "epoch",
"monitor": "loss_on_test",
}
return [optimizer], [lr_scheduler]
def validation_step(self, batch, batch_idx):
x, y = batch
out = self.model(x)
loss = self.criterion(out, y)
self.log("loss_on_test", loss, prog_bar=True)
# aux logging for lecture visualization
self.history["loss_on_test"].append(loss.cpu().detach().item())
return {"loss_on_test", loss}
model_name = "reduce_lr_on_plateu_lightning"
model = SimpleMNIST_NN_Init_Batchnorm(n_layers=3)
trainer = pl.Trainer(
max_epochs=5,
logger=TensorBoardLogger(save_dir=f"logs/{model_name}"),
num_sanity_val_steps=0,
)
pipeline = PipelineWithScheduler(
model=model,
exp_name=model_name,
optimizer_class=torch.optim.Adam,
optimizer_kwargs={
"lr": 1e-2,
},
)
trainer.fit(model=pipeline, train_dataloaders=train_loader, val_dataloaders=test_loader)
history = pipeline.history
history["epoсhs"] = trainer.max_epochs
history_plotter.add(history)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: logs/reduce_lr_on_plateu_lightning/lightning_logs
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/usr/local/lib/python3.10/dist-packages/torch/optim/lr_scheduler.py:28: UserWarning: The verbose parameter is deprecated. Please use get_last_lr() to access the learning rate.
warnings.warn("The verbose parameter is deprecated. Please use get_last_lr() "
INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params
------------------------------------------------------------
0 | model | SimpleMNIST_NN_Init_Batchnorm | 100 K
1 | criterion | CrossEntropyLoss | 0
------------------------------------------------------------
100 K Trainable params
0 Non-trainable params
100 K Total params
0.400 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
history_plotter.plot([model_name])

Домножать learning rate на gamma каждую эпоху
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.1)
Для достаточно больших нейронных сетей практикуют следующую схему (gradual warmup 🎓[arxiv]):
learning rate значительно ниже того, с которого мы обычно начинаем обучение.learning rate от этого значения до требуемого. Так мы не совершаем больших шагов, когда сеть еще ничего не знает о данных. За счет этого нейросеть лучше "адаптируется" к нашим данным.Также такой learning schedule позволяет адаптивным оптимизаторам лучше оценить значения learning rate для разных параметров
$kn$ на картинке — это размер одного батча.
[arxiv] 🎓 Cyclical Learning Rates for Training Neural Networks (Smith, 2017)
Идея: Функция потерь может иметь сложный ландшафт. Нам бы хотелось:
Для этого мы можем не все время понижать learning rate, а делать это циклически: то понижать, то повышать.
При увеличении learning rate модель может выбраться из одного локального минимума. При уменьшении — сойтись к следующему.
Есть две основные мотивации использования циклического learning rate:
Ускорение сходимости: мы уже посмотрели на адаптивные оптимизаторы. Их недостатком является необходимость хранения в памяти квадратов градиентов. Для циклического learning rate это необязательно, его можно использовать с SGD, изменяя скорости в 3–4 раза. Аналогично с Adam — это позволит редким признакам быстрее обучаться (частые признаки будут немного “ломаться”, а затем восстанавливаться). Для таких целей важно подбирать learning rate вблизи оптимального. Идея этого представлена в статье 🎓[arxiv].
Создание ансамблей моделей: разные локальные минимумы будут давать ошибки на разных объектах. Можно сохранять модели в локальных минимумах и не только искать лучшую, но и устраивать между моделями голосования. Для этого learning rate изменяют в сотни раз. Идея этого представлена в статье 🎓[article]. Обычно для создания ансамблей используют циклический отжиг 🎓[arxiv].
Добавление “дрожания” в learning rate придумано 🎓[arxiv] как альтернатива Adam, позволяющая не хранить значения Momentum и сумм квадратов градиентов при дефиците вычислительных мощностей. По сходимости этот метод почти всегда уступает Adam и AdamW, поэтому редко используется.
Реализация данной идеи:
[colab] 🥨 Циклическое изменение learning rate для ускорения сходимости
Для создания ансамблей моделей learning rate циклически изменяют в сотни раз (а можно и до 0, как ниже), поэтому подбор оптимального значения learning rate не критичен. В качестве правила изменения используют циклический отжиг (cosine annealing cycles):
$$\text{lr}(t) = \frac {\text{lr}_0}{2}(\cos(\frac{\pi\cdot \mod(t-1, [T/M])}{[T/M]})+1),$$где $\text{lr}_0$ — начальная скорость обучения, $T$ — общее количество итераций, $M$ — общее количество моделей, $t$ — текущая итерация.
В формулу можно добавить минимальное значение, но мы это делать не будем, т.к. это не обязательный параметр.
import numpy as np
import matplotlib.pyplot as plt
# number of models (M in formula)
num_models = 6
# epoch per model
num_epochs = 50
# number of bats in dataset
len_dataset = 8
# total iteration number (T in formula)
total_iter = num_models * num_epochs * len_dataset
learning_rate_0 = 0.1
t = np.array(range(total_iter))
lr_t = (learning_rate_0 / 2) * (
np.cos(np.pi * np.mod(t, total_iter / num_models) / (total_iter / num_models)) + 1
)
fig, ax = plt.subplots(figsize=(12, 4))
fig.suptitle("Cosine annealing cycles", size=15)
ax.plot(t / len_dataset, lr_t)
ax.set(xlabel="Epoch", ylabel="Learning rate")
plt.show()

В PyTorch циклический отжиг реализован в модуле torch.optim.lr_scheduler.CosineAnnealingWarmRestarts.
Общее правило подбора скорости обучения $\text{lr}_0$: она должна быть достаточно большой, чтобы “ломать” обученную модель, при этом количество эпох для обучения каждой модели должно быть достаточным для получения приличного качества. В статье 🎓[article], например, используют 50 эпох, но это значение зависит от модели.
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer, T_0=total_iter // num_models
)
Loss при обучении будет выглядеть примерно так (красная линия):
Модели в конце цикла отжига сохраняются. Можно выбрать лучшую или построить ансамбль.
В статье была предложена идея “супа моделей”, которая очень проста: обучить несколько моделей (для этого мы будем использовать циклический отжиг) и агрегировать веса моделей в одну модель.
Для “приготовления супа” возьмем датасет немного сложнее, чем рассматриваемый в лекции MNIST, а именно CIFAR-10.
import torch
import random
import numpy as np
def set_random_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
from torchvision import transforms, datasets
from torch.utils.data import DataLoader, random_split
set_random_seed(42)
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261)),
]
)
cifar = datasets.CIFAR10("CIFAR10", train=True, download=True, transform=transform)
cifar_test = datasets.CIFAR10(
"CIFAR10", train=False, download=True, transform=transform
)
train_set, val_set = random_split(cifar, [40_000, 10_000])
train_loader = DataLoader(train_set, batch_size=128, shuffle=True, num_workers=2)
val_loader = DataLoader(val_set, batch_size=256, shuffle=False, num_workers=2)
test_loader = DataLoader(cifar_test, batch_size=256, shuffle=False, num_workers=2)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to CIFAR10/cifar-10-python.tar.gz
100%|██████████| 170498071/170498071 [00:03<00:00, 46796703.84it/s]
Extracting CIFAR10/cifar-10-python.tar.gz to CIFAR10 Files already downloaded and verified
Соберем простую модель:
import torch.nn as nn
class SimpleNet_CIFAR(nn.Module):
def __init__(self):
super().__init__()
self.activation = nn.ReLU()
self.conv1 = nn.Conv2d(3, 6, 3)
self.pool = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(6, 16, 3)
self.conv3 = nn.Conv2d(16, 32, 3)
self.fc1 = nn.Linear(32 * 2 * 2, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x): # input [batch, 3, 32, 32]
x = self.activation(self.pool(self.conv1(x)))
x = self.activation(self.pool(self.conv2(x)))
x = self.activation(self.pool(self.conv3(x)))
x = self.activation(self.fc1(x.flatten(start_dim=1)))
x = self.activation(self.fc2(x))
x = self.fc3(x)
return x
Для обучения будем использовать Lightning, для расчета метрик — TorchMetrics. Это сделает код более универсальным (его можно использовать для ваших моделей с минимумом модификаций).
Для чтения логов будем использовать tbparse:
import matplotlib.pyplot as plt
from tbparse import SummaryReader
from IPython.display import clear_output
def visualization(log_dir):
# visualization without TensorBoard for TensorBoard logs
clear_output()
reader = SummaryReader(log_dir)
df = reader.scalars.drop_duplicates()
uniq = set(df.tag.unique())
uniq.remove("epoch")
uniq = list(uniq)
uniq.sort()
i = 0
ax_dict = {}
for item in uniq:
metric = item.split("_")[0]
if metric not in ax_dict:
ax_dict[metric] = i
i += 1
fig, axs = plt.subplots(len(ax_dict), 1, figsize=(12, 3.5 * len(ax_dict)))
for item in uniq:
metric = item.split("_")[0]
ax = axs[ax_dict[metric]]
sub_df = df[df["tag"] == item]
ax.plot(sub_df.step, sub_df.value, label=item)
ax.set_ylabel(metric)
ax.legend()
ax.set_xlabel("iter")
axs[-1].grid()
plt.grid()
plt.show()
Есть несколько подходов 🎓[arxiv] к “приготовлению супа”. Мы рассмотрим два:
Uniform soup (равномерный суп) — веса всех моделей суммируются с одинаковым весом: $$\text{Model} = f(x, \frac{1}{k}\sum_{i=1}^{k}ϴ_i)$$
Greedy soup (жадный суп):
Качество “супа” определяется по тестовой выборке.
Код для методов реализован ниже. Для обучения отдельных моделей используется циклический отжиг.
from torchmetrics.aggregation import MeanMetric
from torchmetrics.classification import Accuracy
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class MakeSoup(pl.LightningModule):
def __init__(
self,
model,
num_class,
n_cycle_iter,
cycle_epochs,
show=True,
path="/content/log/model_weight/",
):
super().__init__()
self.cycle_epochs = cycle_epochs
self.num_class = num_class
self.n_cycle_iter = n_cycle_iter
self.model = model
self.show = show
self.path = path
self.criterion = torch.nn.CrossEntropyLoss()
self.loss_train = MeanMetric()
self.loss = MeanMetric()
# set metrics
self.metric_train = Accuracy(num_classes=num_class, task="multiclass")
self.metric = Accuracy(num_classes=num_class, task="multiclass")
self.models_dir = []
def configure_optimizers(self):
# set optimizer
optimizer = torch.optim.AdamW(
self.model.parameters(),
lr=0.01,
)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer,
T_0=self.n_cycle_iter,
eta_min=0,
)
return {
"optimizer": optimizer,
"lr_scheduler": {
"scheduler": scheduler,
"interval": "step", # or 'epoch'
"frequency": 1,
},
}
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = self.criterion(y_hat, y)
self.loss_train.update(loss)
self.metric_train.update(y_hat, y)
# log lr
opt = self.optimizers()
lr = opt.param_groups[0]["lr"]
self.log(
"lr_train",
lr,
sync_dist=False,
rank_zero_only=True,
on_step=True,
on_epoch=False,
)
return loss
def on_train_epoch_end(self):
loss = self.loss_train.compute().item()
self.log("loss_train", loss, sync_dist=False, rank_zero_only=True)
self.loss_train.reset()
metric = self.metric_train.compute().item()
self.log("metric_train", metric, sync_dist=False, rank_zero_only=True)
self.metric_train.reset()
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = self.criterion(y_hat, y)
self.loss.update(loss)
self.metric.update(y_hat, y)
def on_validation_epoch_end(self):
loss = self.loss.compute().item()
self.log("loss_val", loss, sync_dist=False, rank_zero_only=True)
self.loss.reset()
metric = self.metric.compute().item()
self.log("metric_val", metric, sync_dist=False, rank_zero_only=True)
self.metric.reset()
if (self.current_epoch + 1) % self.cycle_epochs == 0:
current_model = (self.current_epoch + 1) // self.cycle_epochs
path = self.path + f"model_{current_model}.pt"
print(f"Epoch: {self.current_epoch} Validation metric: {metric}")
print(f"Save {path}")
torch.save(
self.model.state_dict(),
path,
)
self.models_dir.append(
{
"path": path,
"metric": metric,
}
)
if self.show and self.current_epoch != 0:
visualization(self.logger.log_dir)
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = self.criterion(y_hat, y)
self.loss.update(loss)
self.metric.update(y_hat, y)
def on_test_epoch_end(self):
loss = self.loss.compute().item()
self.log("loss_test", loss, sync_dist=False, rank_zero_only=True)
self.loss.reset()
metric = self.metric.compute().item()
self.log("metric_test", metric, sync_dist=False, rank_zero_only=True)
self.metric.reset()
def load_model_weight(self, path, return_state=False):
state_dict = torch.load(path, map_location=device)
self.model.load_state_dict(state_dict)
if return_state:
return state_dict
def uniform_soup(self, skip_first=False):
self.models_dir.sort(key=lambda x: x["path"])
if skip_first:
models_dir = self.models_dir[1:].copy()
else:
models_dir = self.models_dir.copy()
num_models = len(models_dir)
for i, item in enumerate(models_dir):
state_dict = self.load_model_weight(item["path"], return_state=True)
if i == 0:
uniform_soup_params = {
key: val * (1.0 / num_models) for key, val in state_dict.items()
}
else:
uniform_soup_params = {
key: val * (1.0 / num_models) + uniform_soup_params[key]
for key, val in state_dict.items()
}
print(f'Adding {item["path"]} to soup.')
self.model.load_state_dict(uniform_soup_params)
path = self.path + "model_uniform_soup.pt"
torch.save(
self.model.state_dict(),
path,
)
return self.model
def greedy_soup(self, val_loader):
# sort
self.models_dir.sort(key=lambda x: x["metric"], reverse=True)
best_model_path = self.models_dir[0]["path"]
best_score = self.models_dir[0]["metric"]
greedy_soup_ingredients = [best_model_path]
greedy_soup_params = self.load_model_weight(best_model_path, return_state=True)
for i in range(1, len(self.models_dir)):
n = len(greedy_soup_ingredients)
path = self.models_dir[i]["path"]
ingredient_params = self.load_model_weight(path, return_state=True)
# mix ingredient
potential_greedy_soup_params = {
k: greedy_soup_params[k].clone() * (n / (n + 1.0))
+ ingredient_params[k].clone() * (1.0 / (n + 1.0))
for k in ingredient_params
}
self.loss.reset()
self.metric.reset()
self.model.load_state_dict(potential_greedy_soup_params)
# validate
for batch_idx, batch in enumerate(val_loader):
self.test_step(batch, batch_idx)
score = self.metric.compute().item()
self.metric.reset()
if score > best_score:
greedy_soup_ingredients.append(path)
best_score = score
greedy_soup_params = potential_greedy_soup_params
print(
f"Adding to soup. New soup is {greedy_soup_ingredients}. ",
f"With score = {best_score}",
)
self.model.load_state_dict(greedy_soup_params)
path = self.path + "model_greedy_soup.pt"
torch.save(
self.model.state_dict(),
path,
)
return self.model
Параметры обучения представлены ниже. Запуск обучения закомментирован. Обучение модели занимает примерно 30 минут на GPU.
!mkdir -p /content/log/model_weight/
num_models = 5
cycle_epochs = 20
num_class = 10
set_random_seed(42)
model = SimpleNet_CIFAR()
n_cycle_iter = cycle_epochs * len(train_loader)
pl_model = MakeSoup(model, num_class, n_cycle_iter, cycle_epochs)
trainer = pl.Trainer(
max_epochs=cycle_epochs * num_models,
logger=pl.loggers.TensorBoardLogger(save_dir="./log/"),
)
# trainer.fit(pl_model, train_loader, val_loader)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
Для ускорения работы мы загрузим заранее обученные модели и логи обучения:
!rm -r /content/log/
!wget -q https://edunet.kea.su/repo/EduNet-content/dev-2.0/L07/weights/model_soup_log.zip
!unzip -qq model_soup_log.zip
Загрузим модели, посчитаем статистику по предсказаниям и точность на выборке для валидации и загрузим последнее в нужное поле модели. Посмотрим на логи обучения.
import os
visualization("/content/log/lightning_logs/version_0")
weight_path = "/content/log/model_weight/"
file_list = os.listdir(weight_path)
file_list.sort()
file_list = file_list[:num_models] # only number model
models_dir = []
metric = Accuracy(num_classes=num_class, task="multiclass")
for i, f in enumerate(file_list):
path = weight_path + f
pl_model.load_model_weight(path)
# validate
for batch_idx, batch in enumerate(val_loader):
x, y = batch
y_hat = pl_model.model(x)
metric(y_hat, y)
score = metric.compute().item()
metric.reset()
models_dir.append(
{
"path": path,
"metric": score,
}
)
pl_model.models_dir = models_dir

Посчитаем точность моделей на тестовой выборке:
for item in pl_model.models_dir:
print(f"{item['path']}, val_acc {item['metric']}")
pl_model.load_model_weight(item["path"])
trainer.test(pl_model, test_loader)
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/content/log/model_weight/model_1.pt, val_acc 0.6248000264167786
Testing: | | 0/? [00:00<?, ?it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ loss_test │ 1.1079516410827637 │ │ metric_test │ 0.6262999773025513 │ └───────────────────────────┴───────────────────────────┘
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/content/log/model_weight/model_2.pt, val_acc 0.6309000253677368
Testing: | | 0/? [00:00<?, ?it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ loss_test │ 1.1279696226119995 │ │ metric_test │ 0.6402999758720398 │ └───────────────────────────┴───────────────────────────┘
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/content/log/model_weight/model_3.pt, val_acc 0.6401000022888184
Testing: | | 0/? [00:00<?, ?it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ loss_test │ 1.1524646282196045 │ │ metric_test │ 0.6425999999046326 │ └───────────────────────────┴───────────────────────────┘
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/content/log/model_weight/model_4.pt, val_acc 0.6399999856948853
Testing: | | 0/? [00:00<?, ?it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ loss_test │ 1.1481449604034424 │ │ metric_test │ 0.6445000171661377 │ └───────────────────────────┴───────────────────────────┘
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/content/log/model_weight/model_5.pt, val_acc 0.6456999778747559
Testing: | | 0/? [00:00<?, ?it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ loss_test │ 1.1401002407073975 │ │ metric_test │ 0.6460000276565552 │ └───────────────────────────┴───────────────────────────┘
Лучшая модель имеет точность $64.6\%$.
Посчитаем точность на тестовой выборке в случае голосования моделей (выбирается класс, за который проголосовало большинство).
ans_statistic = np.zeros((num_models, len(test_set)))
true_label = np.zeros((len(test_set)))
for i, f in enumerate(file_list):
path = weight_path + f
pl_model.load_model_weight(path)
# validate
for batch_idx, batch in enumerate(test_loader):
x, y = batch
y_hat = pl_model.model(x)
pred = y_hat.argmax(dim=1).detach().numpy()
ans_statistic[i, len(pred) * batch_idx : len(pred) * (batch_idx + 1)] = pred
true_label[len(pred) * batch_idx : len(pred) * (batch_idx + 1)] = y.numpy()
Визуализируем предсказания наших $5$ моделей для первых $100$ объектов выборки для тестирования. Убедимся, что модели дают разные ответы, а значит их можно использовать для ансамбля.
plt.figure(figsize=(15, 4))
plt.imshow(ans_statistic[:, :100], cmap="Paired")
plt.colorbar(orientation="horizontal")
plt.title("Models predict")
plt.ylabel("Models")
plt.yticks(range(5))
plt.grid()
plt.show()

predict_label = np.zeros((len(test_set)))
for i in range(len(test_set)):
values, counts = np.unique(ans_statistic[:, i], return_counts=True)
predict_label[i] = values[counts.argmax()]
predict_label
array([3., 1., 8., ..., 0., 0., 0.])
from sklearn.metrics import accuracy_score
print(f"Ensemble accuracy {accuracy_score(true_label, predict_label)}")
Ensemble accuracy 0.6606
Голосование моделей дает точность $66.06\%$, на $1.46\%$ лучше лучшей модели, но при этом на $1$ предсказание уходит в $5$ раз больше вычислительных ресурсов.
Попробуем применить uniform_soup:
model = pl_model.uniform_soup()
trainer.test(pl_model, test_loader)
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Adding /content/log/model_weight/model_1.pt to soup. Adding /content/log/model_weight/model_2.pt to soup. Adding /content/log/model_weight/model_3.pt to soup. Adding /content/log/model_weight/model_4.pt to soup. Adding /content/log/model_weight/model_5.pt to soup.
Testing: | | 0/? [00:00<?, ?it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ loss_test │ 1.0710166692733765 │ │ metric_test │ 0.6437000036239624 │ └───────────────────────────┴───────────────────────────┘
[{'loss_test': 1.0710166692733765, 'metric_test': 0.6437000036239624}]
Точность хуже. Посмотрим на наши модели: первая модель имеет точность ниже, чем остальные. Это связано с тем, что она стартовала с худшей позиции.
Уберем эту модель из супа:
model = pl_model.uniform_soup(skip_first=True)
trainer.test(pl_model, test_loader)
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Adding /content/log/model_weight/model_2.pt to soup. Adding /content/log/model_weight/model_3.pt to soup. Adding /content/log/model_weight/model_4.pt to soup. Adding /content/log/model_weight/model_5.pt to soup.
Testing: | | 0/? [00:00<?, ?it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ loss_test │ 1.0891315937042236 │ │ metric_test │ 0.6485999822616577 │ └───────────────────────────┴───────────────────────────┘
[{'loss_test': 1.0891315937042236, 'metric_test': 0.6485999822616577}]
Получили точность $64.86\%$. На $0.26\%$ лучше, чем у лучшей модели и на $1.2\%$ меньше, чем у голосования. При этом модель прогоняется только $1$ раз.
Попробуем greedy_soup:
model = pl_model.greedy_soup(val_loader)
trainer.test(pl_model, test_loader)
Adding to soup. New soup is ['/content/log/model_weight/model_5.pt', '/content/log/model_weight/model_3.pt']. With score = 0.6499999761581421
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Testing: | | 0/? [00:00<?, ?it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ loss_test │ 1.0763661861419678 │ │ metric_test │ 0.6518999934196472 │ └───────────────────────────┴───────────────────────────┘
[{'loss_test': 1.0763661861419678, 'metric_test': 0.6518999934196472}]
Получили точность $65.19\%$ это на $0.59\%$ лучше лучшей модели, на $0.33\%$ лучше равномерного супа, на $0.87\%$ хуже голосования. При этом модель прогоняется только $1$ раз.
И то, и другое меняет learning rate:
learning scheduler — глобально,
адаптивные оптимизаторы — для каждого веса отдельно.
Часто их применяют вместе, особенно в случае критерия ранней остановки и WarmUp.
Однако в случае циклического режима обучения так делают не всегда. Дело в том, что одна из его задач — как раз избежать использования адаптивных оптимизаторов, требующих больше памяти и дополнительных вычислений.
При этом никаких препятствий к использованию того же Adam в компании вместе с циклическим режимом обучения нет. Так делают, например, в статье 🎓[arxiv].
Кроме того, есть сложные оптимизаторы, составленные из нескольких простых оптимизаторов и шедулеров. Например, есть проект Ranger21 🐾[git], не получивший оформления в виде библиотеки на PyPi 🛠️[doc], авторы которого пытаются “померить” разные идеи из статей.
[arxiv] 🎓 Ranger21: A Synergistic Deep Learning Optimizer (Wright, Demeure, 2021)
Результаты выглядят неплохо. Недостатком этого оптимизатора является большое количество хранимых параметров и гиперпараметров, а также тестирование на ограниченном числе моделей.
Литература
Нормализация входов и выходов:
Инициализация весов:
Слои нормализации:
Оптимизация параметров нейросетей:
Режимы обучения:
Дополнительно: