
Сегментация и детектирование
В ходе предыдущих занятий мы подробно рассмотрели задачу классификации изображений.
Но порой недостаточно знать, что на изображении есть объект определенного класса. Важно, где именно расположен объект. В ряде случаев нужно знать еще и точные границы объекта. Например, если речь идет о рентгеновском снимке или изображении клеток ткани, полученном с микроскопа.
Определение того, какие фрагменты изображения принадлежат объектам определенных классов — это задача сегментации (segmentation).
Если нас интересуют не индивидуальные объекты, а только тип (класс) объекта, которым занят конкретный пиксель (как в случае с клетками под микроскопом), то говорят о семантической сегментации (semantic segmentation).
Если нас интересуют конкретные объекты, и при этом достаточно знать только область, в которой объект локализован, то это задача детектирования (Detection)
В качестве примера такой задачи можно рассмотреть подсчет количество китов на спутниковом снимке.
Если же важны и индивидуальные объекты, и их точные границы, то это уже задача Instance segmentation. Например, для автопилота важно не только знать, что перед ним несколько автомобилей, но и отличить, где именно находится ближний, а где — дальний.
Прежде чем говорить о способах решения этих задач, надо разобраться с форматами входных данных. Сделаем это на примере датасета COCO.
COCO — один из наиболее популярных датасатов, содержащий данные для сегментации и детектирования. Он содержит более трёхсот тысяч изображений, большая часть из которых размечена и содержит следующую информацию:
Формат разметки изображений, использованный в этом датасете, нередко используется и в других наборах данных. Как правило, он упоминается просто как "COCO format".
Загрузим датасет.
!wget -qN "http://images.cocodataset.org/annotations/annotations_trainval2017.zip"
# !wget -qN "https://edunet.kea.su/repo/EduNet-web_dependencies/datasets/annotations_trainval2017.zip"
!unzip -qn annotations_trainval2017.zip
Для работы с датасетом используется пакет pycocotools.
from pycocotools.coco import COCO
coco = COCO("annotations/instances_val2017.json")
loading annotations into memory... Done (t=0.56s) creating index... index created!
Рассмотрим формат аннотаций на примере одной записи.
catIds = coco.getCatIds(catNms=["cat"]) # cat's IDs
print("class ID(cat) =", catIds)
imgIds = coco.getImgIds(catIds=catIds) # Filtering dataset by tag
print("All images: %i" % len(imgIds))
class ID(cat) = [17] All images: 184
Рассмотрим метаданные.
img_list = coco.loadImgs(imgIds[0]) # 1 example
img_metadata = img_list[0]
img_metadata
{'license': 5,
'file_name': '000000416256.jpg',
'coco_url': 'http://images.cocodataset.org/val2017/000000416256.jpg',
'height': 375,
'width': 500,
'date_captured': '2013-11-18 04:05:18',
'flickr_url': 'http://farm1.staticflickr.com/34/64280333_7acf38cfb3_z.jpg',
'id': 416256}
Посмотрим на изображение.
import matplotlib.pyplot as plt
import requests
from PIL import Image
from io import BytesIO
def coco2pil(url):
response = requests.get(url)
return Image.open(BytesIO(response.content))
I = coco2pil(img_metadata["coco_url"])
plt.axis("off")
plt.imshow(I)
plt.show()

Давайте посмотрим на категории в датасете.
cats = coco.loadCats(coco.getCatIds()) # loading categories
num2cat = {}
print("COCO categories: ")
iterator = iter(cats)
cat = next(iterator)
for i in range(0, 91):
if i == cat["id"]:
num2cat[cat["id"]] = cat["name"]
name = cat["name"]
if i < 90:
cat = next(iterator)
else:
name = "---"
print(f"{i:2}. {name:20}", end="")
if not i % 6:
print("\n")
COCO categories: 0. --- 1. person 2. bicycle 3. car 4. motorcycle 5. airplane 6. bus 7. train 8. truck 9. boat 10. traffic light 11. fire hydrant 12. --- 13. stop sign 14. parking meter 15. bench 16. bird 17. cat 18. dog 19. horse 20. sheep 21. cow 22. elephant 23. bear 24. zebra 25. giraffe 26. --- 27. backpack 28. umbrella 29. --- 30. --- 31. handbag 32. tie 33. suitcase 34. frisbee 35. skis 36. snowboard 37. sports ball 38. kite 39. baseball bat 40. baseball glove 41. skateboard 42. surfboard 43. tennis racket 44. bottle 45. --- 46. wine glass 47. cup 48. fork 49. knife 50. spoon 51. bowl 52. banana 53. apple 54. sandwich 55. orange 56. broccoli 57. carrot 58. hot dog 59. pizza 60. donut 61. cake 62. chair 63. couch 64. potted plant 65. bed 66. --- 67. dining table 68. --- 69. --- 70. toilet 71. --- 72. tv 73. laptop 74. mouse 75. remote 76. keyboard 77. cell phone 78. microwave 79. oven 80. toaster 81. sink 82. refrigerator 83. --- 84. book 85. clock 86. vase 87. scissors 88. teddy bear 89. hair drier 90. toothbrush
Категория 0 используется для обозначения класса фона. Некоторые номера категорий не заняты.
Также существуют надкатегории.
print(f"cats[2]: {cats[2]}")
print(f"cats[3]: {cats[3]}")
nms = set([cat["supercategory"] for cat in cats])
print("COCO supercategories: \n{}".format("\t".join(nms)))
cats[2]: {'supercategory': 'vehicle', 'id': 3, 'name': 'car'}
cats[3]: {'supercategory': 'vehicle', 'id': 4, 'name': 'motorcycle'}
COCO supercategories:
indoor appliance outdoor animal sports vehicle furniture person electronic accessory food kitchen
Помимо метаданных нам доступна разметка (подробнее о разметке). Давайте её загрузим и отобразим.
annIds = coco.getAnnIds(imgIds=img_metadata["id"])
anns = coco.loadAnns(annIds)
plt.imshow(I)
plt.axis("off")
coco.showAnns(anns)
plt.show()

На изображении можно увидеть разметку пикселей изображения по классам. То есть, пиксели из объектов, относящихся к интересующим классам, приписываются к классу этого объекта. К примеру, можно увидеть объекты двух классов: "cat" и "keyboard".
Давайте теперь посмотрим, из чего состоит разметка.
def dump_anns(anns):
for i, a in enumerate(anns):
print(f"\n#{i}")
for k in a.keys():
if k == "category_id" and num2cat.get(a[k], None):
print(k, ": ", a[k], num2cat[a[k]]) # Show cat. name
else:
print(k, ": ", a[k])
dump_anns(anns)
#0 segmentation : [[157.26, 120.16, 165.32, 104.84, 191.94, 86.29, 198.39, 95.97, 193.55, 103.23, 188.71, 118.55, 188.71, 130.65, 191.13, 140.32, 204.03, 145.16, 211.29, 145.16, 262.1, 150.81, 280.65, 150.81, 290.32, 146.77, 300.0, 138.71, 304.03, 136.29, 322.58, 131.45, 324.19, 131.45, 327.42, 143.55, 341.94, 139.52, 367.74, 144.35, 368.55, 146.77, 337.1, 157.26, 312.9, 163.71, 295.16, 168.55, 299.19, 181.45, 305.65, 201.61, 293.55, 239.52, 288.71, 233.87, 265.32, 227.42, 225.0, 221.77, 199.19, 217.74, 170.97, 211.29, 159.68, 207.26, 149.19, 204.03, 137.1, 195.97, 130.65, 191.13, 117.74, 175.81, 134.68, 150.81, 147.58, 134.68]] area : 15465.184599999999 iscrowd : 0 image_id : 416256 bbox : [117.74, 86.29, 250.81, 153.23] category_id : 17 cat id : 51846 #1 segmentation : [[122.48, 272.75, 284.67, 309.77, 293.93, 313.33, 313.86, 252.82, 315.29, 238.58, 153.67, 210.81, 123.06, 259.93, 121.64, 267.77]] area : 12449.917949999995 iscrowd : 0 image_id : 416256 bbox : [121.64, 210.81, 193.65, 102.52] category_id : 76 keyboard id : 1115755 #2 segmentation : [[28.95, 191.52, 88.37, 123.57, 138.31, 142.22, 125.98, 155.17, 122.5, 166.87, 122.5, 177.93, 122.82, 182.04, 86.79, 227.87]] area : 5851.351 iscrowd : 0 image_id : 416256 bbox : [28.95, 123.57, 109.36, 104.3] category_id : 76 keyboard id : 1975408
Заметим, что аннотация изображения может состоять из описаний нескольких объектов, каждое из которых содержит следующую информацию:
segmentation — последовательность пар чисел ($x$, $y$), координат каждой из вершин "оболочки" объекта;area — площадь объекта;iscrowd — несколько объектов (например, толпа людей), в этом случае информация о границах объекта (маска) хранится в RLE формате;image_id — идентификатор изображения, к которому принадлежит описываемый объект;bbox — будет рассмотрен далее в ходе лекции;category_id — идентификатор категории, к которой относится данный объект;id — идентификатор самого объекта.Попробуем посмотреть на пример, в котором iscrowd = True .
catIds = coco.getCatIds(catNms=["people"])
annIds = coco.getAnnIds(catIds=catIds, iscrowd=True)
anns = coco.loadAnns(annIds[0:1])
dump_anns(anns)
img = coco.loadImgs(anns[0]["image_id"])[0]
I = coco2pil(img["coco_url"])
plt.imshow(I)
coco.showAnns(anns) # People in the stands
seg = anns[0]["segmentation"]
print("Counts", len(seg["counts"]))
print("Size", seg["size"])
plt.axis("off")
plt.show()
#0
segmentation : {'counts': [272, 2, 4, 4, 4, 4, 2, 9, 1, 2, 16, 43, 143, 24, 5, 8, 16, 44, 141, 25, 8, 5, 17, 44, 140, 26, 10, 2, 17, 45, 129, 4, 5, 27, 24, 5, 1, 45, 127, 38, 23, 52, 125, 40, 22, 53, 123, 43, 20, 54, 122, 46, 18, 54, 121, 54, 12, 53, 119, 57, 11, 53, 117, 59, 13, 51, 117, 59, 13, 51, 117, 60, 11, 52, 117, 60, 10, 52, 118, 60, 9, 53, 118, 61, 8, 52, 119, 62, 7, 52, 119, 64, 1, 2, 2, 51, 120, 120, 120, 101, 139, 98, 142, 96, 144, 93, 147, 90, 150, 87, 153, 85, 155, 82, 158, 76, 164, 66, 174, 61, 179, 57, 183, 54, 186, 52, 188, 49, 191, 47, 193, 21, 8, 16, 195, 20, 13, 8, 199, 18, 222, 17, 223, 16, 224, 16, 224, 15, 225, 15, 225, 15, 225, 15, 225, 15, 225, 15, 225, 15, 225, 15, 225, 15, 225, 14, 226, 14, 226, 14, 39, 1, 186, 14, 39, 3, 184, 14, 39, 4, 183, 13, 40, 6, 181, 14, 39, 7, 180, 14, 39, 9, 178, 14, 39, 10, 177, 14, 39, 11, 176, 14, 38, 14, 174, 14, 36, 19, 171, 15, 33, 32, 160, 16, 30, 35, 159, 18, 26, 38, 158, 19, 23, 41, 157, 20, 19, 45, 156, 21, 15, 48, 156, 22, 10, 53, 155, 23, 9, 54, 154, 23, 8, 55, 154, 24, 7, 56, 153, 24, 6, 57, 153, 25, 5, 57, 153, 25, 5, 58, 152, 25, 4, 59, 152, 26, 3, 59, 152, 26, 3, 59, 152, 27, 1, 60, 152, 27, 1, 60, 152, 86, 154, 80, 160, 79, 161, 42, 8, 29, 161, 41, 11, 22, 2, 3, 161, 40, 13, 18, 5, 3, 161, 40, 15, 2, 5, 8, 7, 2, 161, 40, 24, 6, 170, 35, 30, 4, 171, 34, 206, 34, 41, 1, 164, 34, 39, 3, 164, 34, 37, 5, 164, 34, 35, 10, 161, 36, 1, 3, 28, 17, 155, 41, 27, 16, 156, 41, 26, 17, 156, 41, 26, 16, 157, 27, 4, 10, 25, 16, 158, 27, 6, 8, 11, 2, 12, 6, 2, 7, 159, 27, 7, 14, 3, 4, 19, 6, 160, 26, 8, 22, 18, 5, 161, 26, 8, 22, 18, 4, 162, 26, 8, 23, 15, 4, 164, 23, 11, 23, 11, 7, 165, 19, 17, 22, 9, 6, 167, 19, 22, 18, 8, 3, 170, 18, 25, 16, 7, 1, 173, 17, 28, 15, 180, 17, 30, 12, 181, 16, 34, 6, 184, 15, 225, 14, 226, 13, 227, 12, 228, 11, 229, 10, 230, 9, 231, 9, 231, 9, 231, 9, 231, 8, 232, 8, 232, 8, 232, 8, 232, 8, 232, 8, 232, 7, 233, 7, 233, 7, 233, 7, 233, 8, 232, 8, 232, 8, 232, 9, 231, 9, 231, 9, 231, 10, 230, 10, 230, 11, 229, 13, 227, 14, 226, 16, 224, 17, 223, 19, 221, 23, 217, 31, 3, 5, 201, 39, 201, 39, 201, 39, 201, 39, 201, 39, 201, 40, 200, 40, 200, 41, 199, 41, 199, 41, 199, 22, 8, 12, 198, 22, 12, 8, 198, 22, 14, 6, 198, 22, 15, 6, 197, 22, 16, 5, 197, 22, 17, 5, 196, 22, 18, 4, 196, 22, 19, 4, 195, 22, 19, 5, 194, 22, 20, 4, 194, 25, 21, 1, 193, 27, 213, 29, 211, 30, 210, 35, 6, 6, 193, 49, 191, 50, 190, 50, 190, 51, 189, 51, 189, 52, 188, 53, 187, 53, 187, 54, 186, 54, 186, 54, 186, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 55, 185, 28, 1, 26, 185, 23, 11, 21, 185, 20, 17, 17, 186, 18, 21, 15, 186, 16, 23, 14, 187, 14, 25, 14, 187, 14, 26, 12, 188, 14, 28, 10, 188, 14, 226, 14, 226, 16, 224, 17, 223, 19, 221, 20, 220, 22, 218, 24, 18, 3, 12, 3, 180, 25, 10, 1, 4, 6, 10, 6, 178, 28, 7, 12, 8, 8, 177, 49, 3, 12, 176, 65, 175, 67, 173, 69, 171, 53, 3, 14, 170, 37, 20, 9, 4, 1, 169, 36, 21, 8, 175, 35, 22, 7, 176, 34, 23, 7, 176, 34, 23, 6, 177, 35, 22, 6, 177, 35, 22, 8, 175, 35, 23, 9, 173, 35, 205, 36, 204, 39, 201, 43, 197, 48, 36, 1, 155, 48, 35, 3, 154, 49, 33, 5, 154, 48, 32, 6, 155, 49, 27, 10, 155, 51, 24, 11, 154, 54, 21, 11, 155, 56, 19, 11, 155, 56, 18, 11, 156, 56, 17, 11, 157, 56, 16, 12, 157, 56, 14, 13, 159, 56, 12, 13, 160, 61, 5, 14, 162, 78, 165, 75, 167, 73, 168, 72, 170, 70, 171, 69, 173, 67, 176, 64, 179, 61, 182, 58, 183, 57, 185, 54, 187, 53, 188, 51, 191, 49, 192, 47, 195, 45, 196, 43, 198, 42, 199, 40, 201, 38, 203, 36, 205, 34, 207, 32, 210, 28, 213, 26, 216, 22, 221, 16, 228, 8, 10250], 'size': [240, 320]}
area : 18419
iscrowd : 1
image_id : 448263
bbox : [1, 0, 276, 122]
category_id : 1 person
id : 900100448263
Counts 869
Size [240, 320]

Что такое run-length encoding (RLE)
Используя методы из pycocotools, можно преобразовать набор вершин "оболочки" сегментируемого объекта в более удобный, но менее компактный вид — маску объекта.
import numpy as np
annIds = coco.getAnnIds(imgIds=[448263])
anns = coco.loadAnns(annIds)
msk = np.zeros(seg["size"])
fig, ax = plt.subplots(nrows=4, ncols=4, figsize=(10, 10))
i = 0
for row in range(4):
for col in range(4):
ann = anns[i]
msk = coco.annToMask(ann)
ax[row, col].imshow(msk, cmap="gray")
ax[row, col].set_title(num2cat[anns[i]["category_id"]])
ax[row, col].axis("off")
i += 1
plt.show()

В некоторых случаях попиксельная разметка изображения может быть избыточной. К примеру, если необходимо посчитать количество человек на изображении, то достаточно просто каким-то образом промаркировать каждого из них, после чего посчитать количество наших "отметок". Одним из вариантов маркировки является "обведение" объекта рамкой (bounding box), внутри которой он находится. Такая информация об объектах также сохранена в аннотациях формата COCO.
from PIL import Image, ImageDraw
annIds = coco.getAnnIds(imgIds=[448263])
anns = coco.loadAnns(annIds)
draw = ImageDraw.Draw(I)
colors = {1: "white", 40: "lime"} # person - white, glove - lime
for ann in anns:
x, y, width, heigth = ann["bbox"] # bounding box here
color = colors.get(ann["category_id"], None)
if color:
draw.rectangle((x, y, x + width, y + heigth), outline=color, width=2)
plt.imshow(I)
plt.show()

Сегментация изображения — задача поиска групп пикселей, каждая из которых характеризует один смысловой объект.
Технически это выглядит так. Есть набор изображений:

Для каждого изображения есть маска W x H:

Маска задает класс объекта для каждого пикселя: [ x, y $\to$ class_num ]
Набор таких изображений с масками — это и есть наш датасет, на нем мы учимся.
На вход модель получает новое изображение:

и должна предсказать метку класса для каждого пикселя (маску).
Получим такую маску из COCO:
!wget -qN "http://images.cocodataset.org/annotations/annotations_trainval2017.zip"
# !wget -qN "https://edunet.kea.su/repo/EduNet-web_dependencies/datasets/annotations_trainval2017.zip"
!unzip -qn annotations_trainval2017.zip
import numpy as np
import matplotlib.pyplot as plt
import requests
from io import BytesIO
from PIL import Image, ImageDraw
from pycocotools.coco import COCO
from IPython.display import clear_output
def coco2pil(url):
response = requests.get(url)
return Image.open(BytesIO(response.content))
coco = COCO("annotations/instances_val2017.json")
clear_output()
annIds = coco.getAnnIds(imgIds=[448263])
anns = coco.loadAnns(annIds)
img = coco.loadImgs(anns[0]["image_id"])[0]
I = coco2pil(img["coco_url"])
semantic_seg_person_mask = np.zeros(I.size[::-1], dtype=bool) # WxH -> HxW
for ann in anns:
msk = coco.annToMask(ann) # HxW
if ann["category_id"] == 1 and not ann["iscrowd"]: # single person:
# semantic_seg_person_mask = msk | semantic_seg_person_mask # union
semantic_seg_person_mask += msk.astype(bool)
semantic_seg_person_mask = semantic_seg_person_mask > 0 # binarize
plt.imshow(semantic_seg_person_mask, cmap="gray")
plt.show()

Давайте подумаем о том, как такую задачу можно решить.
Из самой постановки задачи видно, что это задача классификации. Только не всего изображения, а каждого пикселя.
a) Наивный
Простейшим вариантом решения является использование так называемого "скользящего окна" — последовательное рассмотрение фрагментов изображения. В данном случае интересующими фрагментами будут небольшие зоны, окружающие каждый из пикселей изображения. К каждому из таких фрагментов применяется свёрточная нейронная сеть, предсказывающая, к какому классу относится центральный пиксель.
![]()
б) Разумный
Понятно, что запускать классификатор для каждого пикселя абсолютно неэффективно, так как для одного изображения потребуется $H*W$ запусков.
Можно пойти другим путем: получить карту признаков и по ней делать предсказание для всех пикселей разом.
Для этого потребуется поменять привычную нам архитектуру сверточной сети следующим образом:
убрать слои, уменьшающие пространственные размеры;
убрать линейный слой в конце, заменив его сверточным.
![]()
Теперь пространственные размеры выхода (W,H) будут равны ширине и высоте исходного изображения.
Количество выходных каналов будет равно количеству классов, которые мы учимся предсказывать.
Тогда можно использовать значения каждой из карт активаций на выходе последнего слоя сети как ненормированное значение вероятности принадлежности (core) каждого из пикселей к тому или иному классу.
То есть номер канала с наибольшим значением будет соответствовать классу объекта, который изображает данный пиксель.
import torch
last_layer_output = torch.randn((3, 32, 32)) # class_num, W,H
print("Output of last layer shape", last_layer_output.shape) # activation slice
mask = torch.argmax(last_layer_output, dim=0) # class_nums prediction
print("One class mask shape", mask.shape)
print("Predictions for all classes \n", mask[:5, :5])
Output of last layer shape torch.Size([3, 32, 32])
One class mask shape torch.Size([32, 32])
Predictions for all classes
tensor([[0, 0, 2, 0, 1],
[2, 2, 0, 1, 2],
[1, 1, 2, 1, 1],
[0, 2, 2, 2, 2],
[1, 0, 1, 0, 1]])
Чтобы на выходе сети получить количество каналов, равное количеству классов, используется свертка 1x1.
![]()
В лекции про сверточные сети мы говорили о том, что свертку 1x1 можно рассматривать как аналог полносвязного слоя. Именно так она тут и работает.
Проблемы:
в) Эффективный
Используем стандартную сверточную сеть, но полносвязные слои заменим на сверточные.
Fully Convolutional Networks for Semantic Segmentation
Сокращенно FCN. Для того, чтобы не было путаницы с Fully Connected Network, последние именуют MLP (Multi Layer Perceptron).
За основу берется обычная сверточная сеть для классификации:
Такую сеть можно построить, взяв за основу другую сверточную архитектуру (backbone), например, ResNet50 или VGG16.
И затем заменить полносвязные слои на свертки.
В конце добавить upsample слой до нужных нам размеров.
На вход такая модель может получать изображение произвольного размера. Для задач сегментации изменение размеров входного изображения приводит к потере важной информации о границах.
Как реализовать декодировщик?
Вспомним, как повышают разрешение для обычных изображений, а уже затем перейдем к картам признаков.
Допустим, требуется увеличить изображение размером 2x2 до размера 4x4.

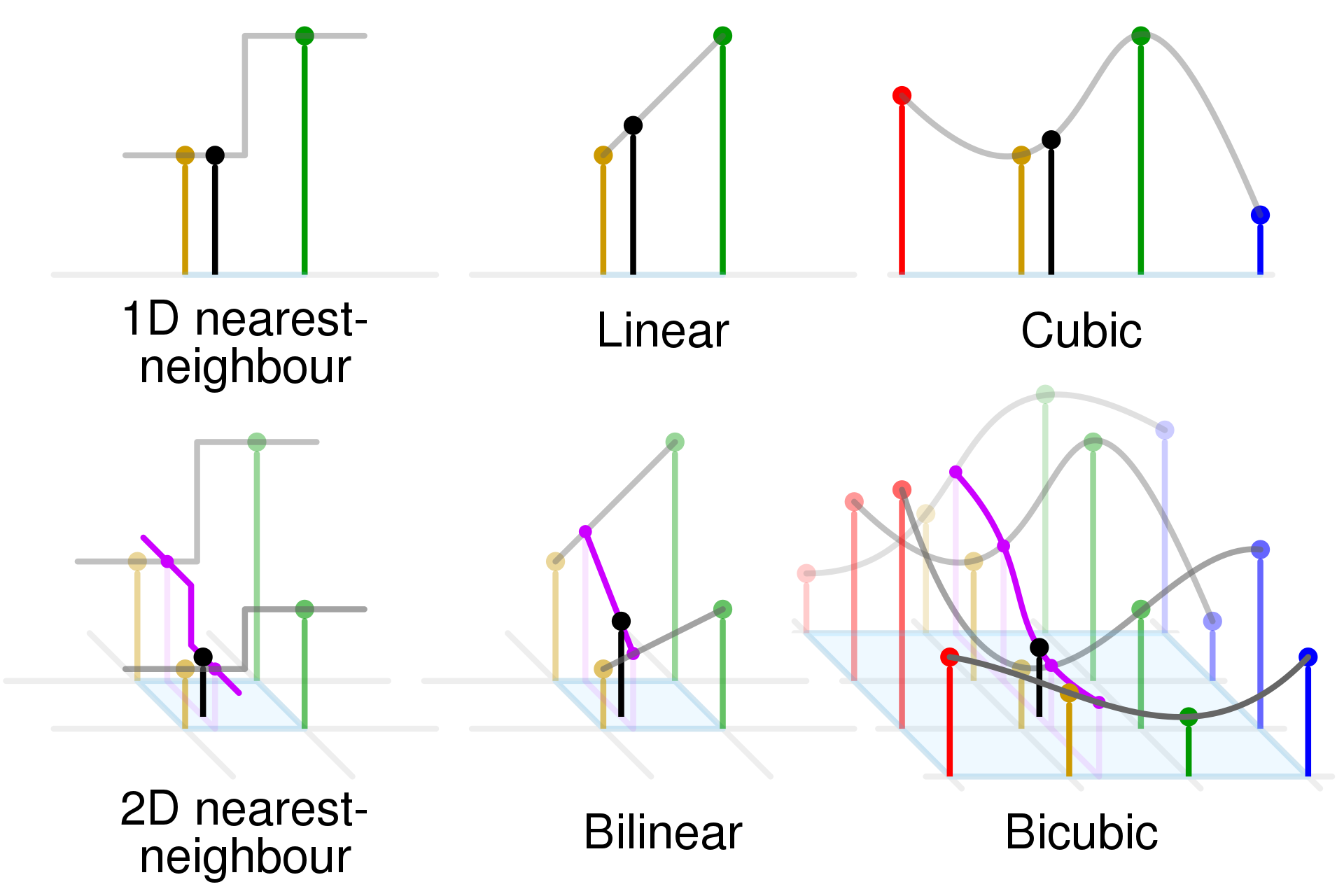
Если для интерполяции используются значения четырех соседних пикселей, то такая интерполяция называется билинейной. В качестве интерполированного значения используется взвешенное среднее этих четырёх пикселей.
import seaborn as sns
def img_to_heatmap(img, ax, title): # Magik method to show img as heatmap
ax.axis("off")
ax.set_title(title)
array = np.array(img)
array = array[None, None, :]
sns.heatmap(array[0][0], annot=True, ax=ax, lw=1, cbar=False)
# Fake image
raw = np.array([[1, 3, 0, 1], [3, 3, 3, 7], [8, 1, 8, 7], [6, 1, 1, 1]], dtype=np.uint8)
pil = Image.fromarray(raw)
interp_nn = pil.resize((8, 8), resample=Image.NEAREST)
interp_bl = pil.resize((8, 8), resample=Image.BILINEAR)
# plot result
fig, ax = plt.subplots(ncols=3, figsize=(15, 5), sharex=True, sharey=True)
img_to_heatmap(raw, ax[0], "Raster dataset")
img_to_heatmap(interp_nn, ax[1], "Nearest neighbor interpolation")
img_to_heatmap(interp_bl, ax[2], "Bilinear interpolation")
plt.show()

Билинейная интерполяция позволяет избавиться от резких границ, которые возникают при увеличении методом ближайшего соседа. Существуют и другие виды интерполяции, использующие большее количество соседних пикселей.
К чему был этот разговор об увеличении картинок?
Оказывается, для увеличения пространственного разрешения карт признаков (feature maps) можно применять те же методы, что и для изображений.
Для увеличения пространственного разрешения карт признаков (карт активаций), в PyTorch используется класс nn.Upsample. В нём доступны все упомянутые методы интерполяции, а также трилинейная интерполяция — аналог билинейной интерполяции, используемый для работы с трёхмерными пространственными данными (к примеру, видео).
[doc] nn.functional.interpolate
Таким образом, мы можем использовать Upsample внутри нашего разжимающего блока.
Загрузим изображение:
!wget -q https://edunet.kea.su/repo/EduNet-content/L12/out/semantic_segmentation_1.png -O cat.png
from torch import nn
import torchvision.transforms.functional as TF
def upsample(pil, ax, mode="nearest"):
tensor = TF.to_tensor(pil)
# Create upsample instance
if mode == "nearest":
upsampler = nn.Upsample(scale_factor=2, mode=mode)
else:
upsampler = nn.Upsample(scale_factor=2, mode=mode, align_corners=True)
tensor_128 = upsampler(tensor.unsqueeze(0)) # add batch dimension
# Convert tensor to pillow
img_128 = tensor_128.squeeze()
img_128_pil = TF.to_pil_image(img_128.clamp(min=0, max=1))
ax.imshow(img_128_pil)
ax.set_title(mode)
# Load and show image in Pillow format
pic = Image.open("cat.png")
pil_64 = pic.resize((64, 64))
fig, ax = plt.subplots(ncols=4, figsize=(15, 5))
ax[0].imshow(pil_64)
ax[0].set_title("Raw")
# Upsample with Pytorch
upsample(pil_64, mode="nearest", ax=ax[1])
upsample(pil_64, mode="bilinear", ax=ax[2])
upsample(pil_64, mode="bicubic", ax=ax[3])
plt.show()

Обратите внимание на то, что в данном случае каждое из пространственных измерений изображения увеличилось в 2 раза, но при необходимости возможно использовать увеличение в иное, в том числе не целое, количество раз, используя параметр scale_factor
Слои Upsample обычно комбинируют вместе со сверточными, это рекомендованный способ увеличения пространственных размеров карт признаков.
model = nn.Sequential(
nn.Upsample(scale_factor=2), nn.Conv2d(3, 16, kernel_size=3, padding=1), nn.ReLU()
)
dummy_input = torch.randn((0, 3, 32, 32))
out = model(dummy_input)
print(out.shape)
torch.Size([0, 16, 64, 64])
Помимо свёртки, на этапе снижения размерности также используются слои pooling'а. Наиболее популярным вариантом является MaxPooling, сохраняющий значение только наибольшего элемента внутри сегмента. Для того, чтобы обратить данную операцию субдискретизации, был предложен MaxUnpooling слой.

Данный слой требует сохранения индексов максимальных элементов внутри сегментов — при обратной операции максимальное значение помещается на место, в котором был максимальный элемент сегмента до соответствующей субдискретизации. Соответственно, каждому слою MaxUnpooling должен соответствовать слой MaxPooling, что визуально можно представить следующим образом:

import requests
from io import BytesIO
torch.use_deterministic_algorithms(False, warn_only=False)
def coco2pil(url):
print(url)
response = requests.get(url)
return Image.open(BytesIO(response.content))
def tensor_show(tensor, title="", ax=ax):
img = TF.to_pil_image(tensor.squeeze()).convert("RGB")
ax.set_title(title + str(img.size))
ax.imshow(img)
pool = nn.MaxPool2d(
kernel_size=2, return_indices=True
) # False by default(get indexes to upsample)
unpool = nn.MaxUnpool2d(kernel_size=2)
pil = coco2pil("http://images.cocodataset.org/val2017/000000448263.jpg")
fig, ax = plt.subplots(ncols=5, figsize=(20, 5), sharex=True, sharey=True)
ax[0].set_title("original " + str(pil.size))
ax[0].imshow(pil)
tensor = TF.to_tensor(pil).unsqueeze(0)
print("Orginal shape", tensor.shape)
# Downsample
tensor_half_res, indexes1 = pool(tensor)
tensor_show(tensor_half_res, "1/2 down ", ax=ax[1])
tensor_q_res, indexes2 = pool(tensor_half_res)
tensor_show(tensor_q_res, "1/4 down ", ax=ax[2])
print("Downsample shape", indexes2.shape)
# Upsample
tensor_half_res1 = unpool(tensor_q_res, indexes2)
tensor_show(tensor_half_res1, "1/2 up ", ax=ax[3])
tensor_recovered = unpool(tensor_half_res1, indexes1)
tensor_show(tensor_recovered, "full size up ", ax=ax[4])
print("Upsample shape", tensor_recovered.shape)
plt.show()
http://images.cocodataset.org/val2017/000000448263.jpg Orginal shape torch.Size([1, 3, 240, 320]) Downsample shape torch.Size([1, 3, 60, 80]) Upsample shape torch.Size([1, 3, 240, 320])

Способы восстановления пространственных размерностей, которые мы рассмотрели, не содержали обучаемых параметров.
Для повышения пространственного разрешения карты признаков можно использовать операцию Transposed convolution, в которой, как в обычной свертке, есть обучаемые параметры. Альтернативное название: Fractionally strided convolution.
Иногда некорректно называется обратной сверткой или Deconvolution.

Операция обычной свертки накладывает фильтр-ядро на фрагмент карты, выполняет поэлементное умножение, а затем сложение, превращая один фрагмент входа в один пиксель выхода.
Transposed convolution, наоборот, проходит по всем пикселям входа и умножает их на обучаемое ядро свертки. При этом каждый одиночный пиксель превращается в фрагмент. Там, где фрагменты накладываются друг на друга, значения попиксельно суммируются.
Если вход имеет несколько каналов, то Transposed convolution применяет отдельный обучаемый фильтр к каждому каналу, а результат суммирует.
Параметр stride отвечает за дополнительный сдвиг каждого фрагмента на выходе. Используя Transposed convolution с параметром stride = 2, можно повышать размер карты признаков приблизительно в два раза, добавляя на нее мелкие детали.
В отличие от обычной свертки, параметр padding Transposed convolution отвечает не за увеличение исходной карты признаков, а, наоборот, за "срезание" внешнего края карты-выхода. Это может быть полезно, потому что карта строится с перекрытием фрагментов, полученных из соседних пикселей, но по периметру результат формируется без перекрытия и может иметь более низкое качество.
Как правило, размер ядра kernel_size выбирают кратным stride, чтобы избавиться от артефактов при частичном наложении фрагментов, например:
kernel_size = 4
stride = 2При таких значениях имеет смысл установить padding=2, чтобы убрать внешние два пикселя со всех сторон выходной карты признаков, полученные без перекрытия.
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size,
stride=1, padding=0, ...)где:
in_channels, out_channels — количество каналов в входной и выходной карте признаков,kernel_size — размер ядра свертки Transpose convolution,stride — шаг свертки Transpose convolution,padding— размер отступов, устанавливаемых по краям входной карты признаков.Пример использования:
input = torch.randn(1, 16, 16, 16) # define dummy input
print("Original size", input.shape)
downsample = nn.Conv2d(16, 16, 3, stride=2, padding=1) # define downsample layer
upsample = nn.ConvTranspose2d(16, 16, 3, stride=2, padding=1) # define upsample layer
# let`s downsample and upsample input
with torch.no_grad():
output_1 = downsample(input)
print("Downsampled size", output_1.size())
output_2 = upsample(output_1, output_size=input.size())
print("Upsampled size", output_2.size())
# plot results
fig, ax = plt.subplots(ncols=3, figsize=(15, 5), sharex=True, sharey=True)
sns.heatmap(input[0, 0, :, :], ax=ax[0], cbar=False, vmin=-2, vmax=2)
ax[0].set_title("Input")
sns.heatmap(output_1[0, 0, :, :], ax=ax[1], cbar=False, vmin=-2, vmax=2)
ax[1].set_title("Downsampled")
sns.heatmap(output_2[0, 0, :, :], ax=ax[2], cbar=False, vmin=-2, vmax=2)
ax[2].set_title("Upsampled")
plt.show()
Original size torch.Size([1, 16, 16, 16]) Downsampled size torch.Size([1, 16, 8, 8]) Upsampled size torch.Size([1, 16, 16, 16])

Возникает вопрос: не потеряется ли информация о мелких деталях изображения при передаче через центральный блок сети, где пространственное разрешение минимально? Такая проблема существует.
Те, кто изучал классические методы машинного зрения, помнят, что при извлечении дескрипторов особых точек(SIFT) использовалась так называемая пирамида изображений.

Идея состоит в последовательном уменьшении (масштабировании) изображения и последовательном извлечении признаков в разных разрешениях.
При уменьшении пространственных размеров мы естественным образом получаем карты признаков с разным пространственным разрешением.

Их можно использовать одновременно как в качестве входа для новых сверток, так и для получения предсказаний.
На этой модели построены FPN-сети: Feature Pyramid Networks for Object Detection.
После того, как все карты признаков будут увеличены до одного размера, они суммируются.
Примеры использования в PyTorch:
Предобученная модель была обучена на части датасета COCO train2017 (на 20 категориях, представленных так же в датасете Pascal VOC). Использовались следующие классы:
['__background__', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
import torchvision
from torchvision import transforms
def coco2pil(url):
print(url)
response = requests.get(url)
return Image.open(BytesIO(response.content))
# load resnet50
fcn_model = torchvision.models.segmentation.fcn_resnet50(
weights="FCN_ResNet50_Weights.DEFAULT", num_classes=21
)
classes = [
"__background__",
"aeroplane",
"bicycle",
"bird",
"boat",
"bottle",
"bus",
"car",
"cat",
"chair",
"cow",
"diningtable",
"dog",
"horse",
"motorbike",
"person",
"pottedplant",
"sheep",
"sofa",
"train",
"tvmonitor",
]
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
), # ImageNet
]
)
pil_img = coco2pil("http://images.cocodataset.org/val2017/000000448263.jpg")
input_tensor = transform(pil_img)
with torch.no_grad():
output = fcn_model(input_tensor.unsqueeze(0))
Downloading: "https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth" to /root/.cache/torch/hub/checkpoints/fcn_resnet50_coco-1167a1af.pth 100%|██████████| 135M/135M [00:00<00:00, 236MB/s]
http://images.cocodataset.org/val2017/000000448263.jpg
Возвращаются 2 массива
print("output keys: ", output.keys()) # Ordered dictionary
print("out: ", output["out"].shape, "Batch, class_num, h, w")
output_predictions = output["out"][0].argmax(0) # for first element of batch
print(f"output_predictions: {output_predictions.shape}")
fig = plt.figure(figsize=(10, 10))
plt.imshow(pil_img)
plt.axis("off")
plt.show()
indexes = output_predictions
semantic_seg_person_predict = np.zeros(pil_img.size).astype(bool)
# plot all classes predictions
fig, ax = plt.subplots(nrows=4, ncols=5, figsize=(10, 10))
i = 0 # counter
for row in range(4):
for col in range(5):
mask = torch.zeros(indexes.shape)
mask[indexes == i] = 255
ax[row, col].set_title(classes[i])
ax[row, col].imshow(mask)
ax[row, col].axis("off")
i += 1
plt.show()
output keys: odict_keys(['out', 'aux']) out: torch.Size([1, 21, 240, 320]) Batch, class_num, h, w output_predictions: torch.Size([240, 320])


semantic_seg_person_predict = torch.zeros(indexes.shape)
semantic_seg_person_predict[indexes == 15] = 1 # to obtain binary mask
semantic_seg_person_predict = (
semantic_seg_person_predict.numpy()
) # for skliarn compability
plt.imshow(semantic_seg_person_predict, cmap="gray")
plt.show()

Как оценить качество предсказаний, полученных от модели?
Базовой метрикой является Intersection over Union (IoU), она же коэффициент Жаккара (Jaccard index)
Имеется предсказание модели (фиолетовая маска) и целевая разметка, сделанная человеком (красная маска)*.

Необходимо оценить качество предсказания.
*Для простоты в примере маски прямоугольные, но та же логика будет работать для масок произвольной формы.
Метрика считается как отношение площади пересечения к площади объединения двух масок:
$$ \large IoU = \frac{|T \cap P|}{|T \cup P|} $$T — True mask, P — predicted mask.

Если маски совпадут на 100%, то значение метрики будет равно 1, и это наилучший результат. При пустом пересечении IoU будет нулевым. Значения метрики лежат в интервале $[0..1]$.
В терминах ошибок первого/второго рода IoU можно записать как:
$$ \large IoU = \frac{TP}{TP + FP + FN} $$TP — True positive — пересечение (обозначено желтым),
FP — False Positive (остаток фиолетового прямоугольника),
FN — False Negative (остаток красного прямоугольника).
На базе этой метрики строится ряд производных от нее метрик, таких как Mean Average Precision, которую мы рассмотрим в разделе Детектирование.
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 10))
plt.subplot(1, 3, 1)
plt.axis("off")
plt.title("GT mask")
plt.imshow(semantic_seg_person_mask)
plt.subplot(1, 3, 2)
plt.axis("off")
plt.title("Predicted mask")
plt.imshow(semantic_seg_person_predict)
plt.subplot(1, 3, 3)
plt.title("GT & Predict overlap")
plt.axis("off")
tmp = semantic_seg_person_predict * 2 + semantic_seg_person_mask
plt.imshow(tmp)
plt.show()

Дополнительная информация:
from sklearn.metrics import jaccard_score
# wait vectors, so we flatten the data
y_true = semantic_seg_person_mask.flatten()
y_pred = semantic_seg_person_predict.flatten()
iou = jaccard_score(y_true, y_pred)
print(f"IoU = {iou:.2f}")
IoU = 0.48
from sklearn.metrics import confusion_matrix
# https://stackoverflow.com/questions/31324218/scikit-learn-how-to-obtain-true-positive-true-negative-false-positive-and-fal
# or use: smp.metrics.get_stats
# https://smp.readthedocs.io/en/latest/metrics.html#segmentation_models_pytorch.metrics.functional.get_stats
tn, fp, fn, tp = confusion_matrix(y_true, y_pred, labels=[0, 1]).ravel()
iou = tp / (tp + fp + fn)
print(f"IoU = {iou:.2f}")
IoU = 0.48
Так как задача сегментации сводится к задаче классификации, то можно использовать Cross-Entropy Loss, BCE, или Focal Loss, с которыми мы знакомы.
Если предсказывается маска для объектов единственного класса(target.shape = 1xHxW), то задача сводится к бинарной классификации, так как каждый канал на выходе последнего слоя выдает предсказание для единственного класса.
Это позволяет заменить Softmax в Cross-Entropy Loss на сигмоиду, а функцию потерь — на бинарную кросс-энтропию (BCE).
import torch
mask_class_1 = torch.randint(0, 2, (1, 64, 64)) # [0 , 1]
one_class_out = torch.randn(1, 1, 64, 64)
print(mask_class_1.shape)
print(one_class_out.shape)
torch.Size([1, 64, 64]) torch.Size([1, 1, 64, 64])
Применяем BCEWithLogitsLoss
from torch import nn
bce_loss_wl = nn.BCEWithLogitsLoss() # Sigmoid inside
loss = bce_loss_wl(
one_class_out, mask_class_1.float().unsqueeze(0)
) # both params must have equal size
print(loss)
tensor(0.8085)
Если последний слой модели — это Сигмоида, то можем использовать BCELoss.
norm_one_class_out = one_class_out.sigmoid()
bce_loss = nn.BCELoss()
loss = bce_loss(
norm_one_class_out, mask_class_1.float().unsqueeze(0)
) # both params must have equal size
print(loss)
tensor(0.8085)
CrossEntropyLoss для одного класса работать не будет:
cross_entropy = nn.CrossEntropyLoss()
loss = cross_entropy(one_class_out, mask_class_1.float().unsqueeze(0))
print(loss)
tensor(-0.)
Так как softmax от единственного входа всегда равен 1.
one_class_out.softmax(dim=1).unique()
tensor([1.])
Multilabel
Если предсказывается несколько классов и target имеет форму $N \times W \times H$ (multilabel), то маска каждого хранится в отдельном канале:
import torch
mask_class1 = torch.randint(0, 2, (1, 64, 64)) # [0 , 1]
mask_class2 = torch.randint(0, 2, (1, 64, 64))
target = torch.cat((mask_class1, mask_class2))
print(target.shape)
torch.Size([2, 64, 64])
Видим, что форма выхода модели совпадает с формой тензора масок:
two_class_out = torch.randn(1, 2, 64, 64)
print(two_class_out.shape)
torch.Size([1, 2, 64, 64])
Мы можем посчитать BCE поэлементно, предварительно преобразовав target во float
from torch import nn
# https://pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html
bce_loss = nn.BCEWithLogitsLoss() # Sigmoid inside
float_target = target.float() # add batch and convert ot float
loss = bce_loss(
two_class_out, float_target.unsqueeze(0)
) # both params must have equal size
print(loss)
tensor(0.8036)
Или CrossEntropyLoss
cross_entropy = nn.CrossEntropyLoss()
# If containing class probabilities, same shape as the input and each value should be between [0,1][0,1].
loss = cross_entropy(two_class_out, float_target.unsqueeze(0))
print(loss)
tensor(0.9137)
Результаты не совпадут, так как после Sigmoid и Softmax получатся разные вероятности.
Если маска задана одним каналом, в котором классы пронумерованы целыми числами (multiclass):
sq_target = target.argmax(0)
sq_target.shape
torch.Size([64, 64])
То логично использовать CrossEntropyLoss
Input: Shape (C), (N,C) or (N,C,d1,d2,...,dK) with K≥1 in the case of K-dimensional loss.
Target: If containing class indices, shape (), (N) or (N,d1,d2,...,dK)# https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html
cross_entropy = nn.CrossEntropyLoss()
loss = cross_entropy(two_class_out, sq_target.unsqueeze(0))
print(loss)
tensor(0.9150)
К Region-based loss относятся функции потерь, основанные на оценки площади пересечения масок.
В отличие от accuracy, рассчет IoU (Jaccard index):
$\large IoU = JaccardIndex = \dfrac{ TP }{TP + FP + FN} \in [0,1]$
можно произвести дифференцируемым образом.
И тогда метрику можно превратить в функцию потерь, инвертировав ее:
$\large Jaccard Loss = 1 - IoU$
В PyTorch эта функция потерь не реализована, поэтому для ее использования установим библиотеку SMP.
!pip install -q segmentation-models-pytorch
clear_output()
import segmentation_models_pytorch as smp
iou_loss = smp.losses.JaccardLoss(smp.losses.MULTILABEL_MODE, from_logits=True)
print("IoU Loss", iou_loss(two_class_out, float_target.unsqueeze(0)))
IoU Loss tensor(0.6630)
*При наличии на выходе модели сигмоиды или другой функции, преобразующей логиты в вероятности, параметр from_logits следует уствновить равным False
Другой популярной метрикой для оценки качества сегментации является Dice коэффициент:
$$ \large \displaystyle Dice = \frac{2|A \cap B|}{|A| + |B|} $$Концептульно он похож на IoU, но при выражении через ошибки первого и второго рода будет видно, что он совпадет с F1-мерой:
$$ \large Dice = \frac{2|A \cap B|}{|A| + |B|} = \dfrac{ 2TP }{2TP + FP + FN} = F1\_score ∈ [0,1]$$Его вычисление не сложно произвести дифференцируемым образом:
$ |A \cap B| = \begin{bmatrix} 0.01 & 0.03 & 0.02 & 0.02 \\ 0.05 & 0.12 & 0.09 & 0.07 \\ 0.89 & 0.85 & 0.88 & 0.91 \\ 0.99 & 0.97 & 0.95 & 0.97 \end{bmatrix} * \begin{bmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 \end{bmatrix} \xrightarrow{\ element-wise \ multiply \ } \begin{bmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0.89 & 0.85 & 0.88 & 0.91 \\ 0.99 & 0.97 & 0.95 & 0.97 \end{bmatrix} \xrightarrow{\ sum \ } 7.41$
$\qquad \qquad \qquad \qquad \text{prediction} \qquad \qquad \qquad \quad \text{target}$
$ |A| = \begin{bmatrix} 0.01 & 0.03 & 0.02 & 0.02 \\ 0.05 & 0.12 & 0.09 & 0.07 \\ 0.89 & 0.85 & 0.88 & 0.91 \\ 0.99 & 0.97 & 0.95 & 0.97 \end{bmatrix} \xrightarrow{\ sum \ } 7.82 \qquad \qquad|B| = \begin{bmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 \end{bmatrix} \xrightarrow{\ sum \ } 8 $
$ \Large Dice = \frac{2 \sum\limits_{pixels}y_{true}y_{pred}}{\sum\limits_{pixels}y_{true} + \sum\limits_{pixels}y_{pred}}$
И затем превратить в функцию потерь:
$ \Large DiceLoss = 1 - Dice = 1 - \frac{2\sum\limits_{pixels}y_{true}y_{pred}}{\sum\limits_{pixels}y_{true} + \sum\limits_{pixels}y_{pred}} $
Эта функция потерь также отсутствует в PyTorch, поэтому воспользуемся библиотекой SMP.
dice_loss = smp.losses.DiceLoss(smp.losses.MULTILABEL_MODE, from_logits=True)
print(two_class_out.shape, target.shape)
print("DICE Loss", dice_loss(two_class_out, float_target.unsqueeze(0)))
torch.Size([1, 2, 64, 64]) torch.Size([2, 64, 64]) DICE Loss tensor(0.4959)
Концептуально DiceLoss и JaccardLoss похожи. Но JaccardLoss сильнее штрафует модель на выбросах.
Хороший обзор loss функций для семантической сегментации можно найти в репозитории: Loss functions for image segmentation
Сохраним большую часть традиционной структуры сети, включая слои downsampling (снижение пространственных размеров), извлечем основные признаки, а затем восстановим пространственные размеры.
![]()
Эта архитектура повторяет архитектуру автокодировщика (autoencoder)

Такая архитектура довольно популярна и применяется не только для сегментации, но и в следующих задачах:
Этому будет посвящена одна из следующих лекций, сейчас же мы детально рассмотрим разжимающий блок.
Признаки, полученные при сжатии, скопируем и передадим в разжимающие слои, где карты признаков будут иметь соответствующее пространственное разрешение:

Так же, как и ResNet, этот механизм носит название skip connection, но признаки не суммируются, а конкатенируются.
Рассмотренная нами схема используется в U-Net. Эта популярная модель для сегментации медицинских изображений изначально была предложена в статье U-Net: Convolutional Networks for Biomedical Image Segmentation (Ronneberger et al., 2015) для анализа медицинских изображений.
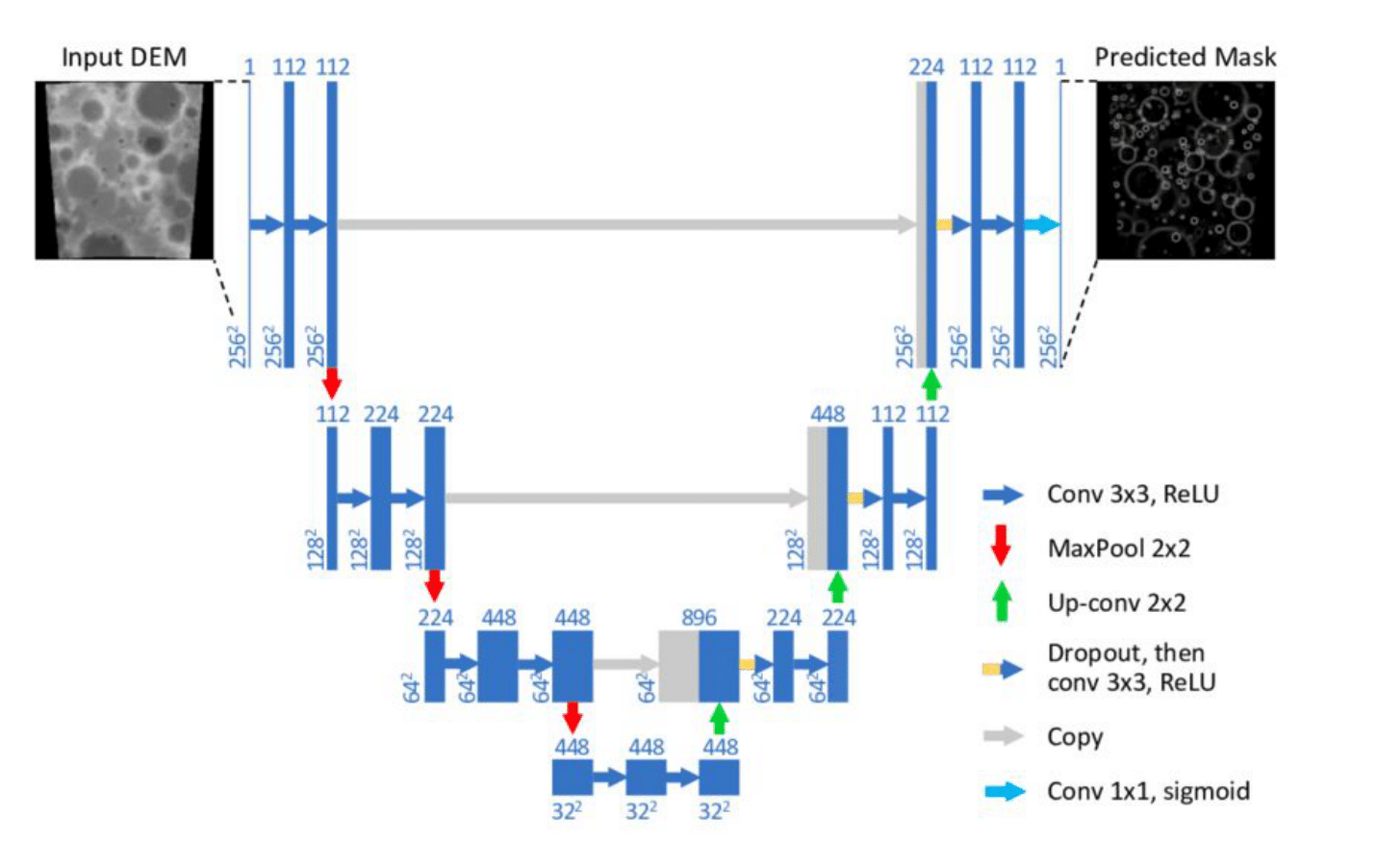
Стоит обратить особое внимание на серые стрелки на схеме: они соответствуют операции конкатенации копий ранее полученных карт активаций по аналогии с DenseNet. Чтобы это было возможно, необходимо поддерживать соответствие между размерами карт активаций в процессах снижения и повышения пространственных размерностей. Для этой цели изменения размеров происходят только при операциях MaxPool и MaxUnpool — в обоих случаях в два раза.
В коде прямой проход может быть реализован, например, вот так:
def forward(self, x):
out1 = self.block1(x) # ------------------------------>
out_pool1 = self.pool1(out1)
out2 = self.block2(out_pool1)
out_pool2 = self.pool2(out2)
out3 = self.block3(out_pool2)
out_pool3 = self.pool2(out3)
out4 = self.block4(out_pool3)
# return up
out_up1 = self.up1(out4)
out_cat1 = torch.cat((out_up1, out3), dim=1)
out5 = self.block5(out_cat1)
out_up2 = self.up2(out5)
out_cat2 = torch.cat((out_up2, out2), dim=1)
out6 = self.block6(out_cat2)
out_up3 = self.up3(out6)
out_cat3 = torch.cat((out_up3, out1), dim=1) # <-------
out = self.block7(out_cat3)
return outПосле upsample блоков ReLU не используется.
DeepLab — семейство моделей для сегментации, значительно развивавшееся в течение четырёх лет. Основой данного рода моделей является использование atrous (dilated) convolutions и, начиная со второй модели, atrous spatial pyramid pooling, опирающейся на spatial pyramid pooling.

Dilated convolution (расширенная свертка) — это тип свертки, который "раздувает" ядро, как бы вставляя отверстия между элементами ядра. Дополнительный параметр (скорость расширения, dilation) указывает, насколько сильно расширяется ядро.
Фактически в такой свертке входные пиксели (признаки) участвуют через один (два, три ...).
Расширенные свертки позволяют значительно увеличить рецептивное поле и хорошо показывают себя при решении задач семантической сегментации изображений.
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, ...)где:
in_channels, out_channels — количество каналов в входной и выходной карте признаков,kernel_size — размер ядра свертки,stride — шаг свертки,padding — размер отступов, устанавливаемых по краям входной карты признаков,dilation — скорость расширения свертки.# for plot
def plot_conv2d(input, conv, output, dilation=1):
fig, ax = plt.subplots(ncols=3, figsize=(15, 5), sharex=False, sharey=False)
# input
sns.heatmap(
input[0][0],
ax=ax[0],
annot=True,
fmt=".0f",
cbar=False,
vmin=0,
vmax=20,
linewidths=1,
)
# kernel
sns.heatmap(
conv.weight.detach()[0, 0, :, :],
ax=ax[1],
annot=True,
fmt=".0f",
cbar=False,
vmin=0,
vmax=20,
linewidths=1,
)
# output
sns.heatmap(
output[0, 0, :, :],
ax=ax[2],
annot=True,
fmt=".0f",
cbar=False,
vmin=0,
vmax=20,
linewidths=1,
)
# titles
ax[0].set_title("Input \nshape: " + str(input.shape))
ax[1].set_title("Kernel \nshape: " + str(conv.weight.shape))
ax[2].set_title("Output \nshape: " + str(output.shape))
fig.suptitle("Dilation = " + str(dilation), y=1.05)
plt.show()
# Atrous example
with torch.no_grad():
# define dummy input
# https://stackoverflow.com/questions/58584413/black-formatter-ignore-specific-multi-line-code
# fmt: off
input = torch.tensor([[[[1, 2, 3],
[1, 2, 3],
[1, 2, 3]]]], dtype=torch.float)
# fmt: on
# define conv layer, dilation = 1
conv = nn.Conv2d(1, 1, kernel_size=2, dilation=1, bias=False)
# define kernel weights
conv.weight = nn.Parameter(torch.tensor([[[[1, 2], [2, 1]]]], dtype=torch.float))
output = conv(input)
plot_conv2d(input, conv, output, dilation=1)

# change dilation to 2
with torch.no_grad():
conv = nn.Conv2d(
1, 1, kernel_size=2, dilation=2, bias=False
) # Fell free to change dilation
conv.weight = nn.Parameter(torch.tensor([[[[1, 2], [2, 1]]]], dtype=torch.float))
output = conv(input)
plot_conv2d(input, conv, output, dilation=2)

with torch.no_grad():
input = torch.tensor([[[[0, 1, 0], [1, 1, 1], [0, 1, 0]]]], dtype=torch.float)
output = conv(input)
plot_conv2d(input, conv, output, dilation=2)

Библиотека на базе PyTorch для сегментации.

!pip install -q segmentation-models-pytorch
Можем комбинировать декодер с разными энкодерами
import segmentation_models_pytorch as smp
from segmentation_models_pytorch.encoders import get_preprocessing_fn
import torch
# 'mit_b0' Mix Vision Transformer Backbone from SegFormer pretrained on Imagenet
preprocess_input = get_preprocessing_fn("mit_b0", pretrained="imagenet")
# MixVisionTransformer encoder does not support in_channels setting other than 3
# supported by FPN only for encoder depth = 5
model = smp.FPN("mit_b0", in_channels=3, classes=10, encoder_depth=5)
# ... Train model on your dataset
dummy_input = torch.randn([1, 3, 64, 64])
mask = model(dummy_input)
print(mask.shape) # torch.Size([1, 1, 64, 64])
Downloading: "https://github.com/qubvel/segmentation_models.pytorch/releases/download/v0.0.2/mit_b0.pth" to /root/.cache/torch/hub/checkpoints/mit_b0.pth 100%|██████████| 13.7M/13.7M [00:00<00:00, 121MB/s]
torch.Size([1, 10, 64, 64])
Существует библиотека pytorch-image-models (timm = Torch IMage Models), в которой собрано большое количество моделей для работы с изображениями.
Описание библиотеки и примеры использования в HuggingFace.
import timm
model_names = timm.list_models(pretrained=True)
print("Total pretrained models: ", len(model_names))
Total pretrained models: 1163
Можно искать модели по шаблону
model_names = timm.list_models("*mobilenet*small*")
print(model_names)
['mobilenetv3_small_050', 'mobilenetv3_small_075', 'mobilenetv3_small_100', 'tf_mobilenetv3_small_075', 'tf_mobilenetv3_small_100', 'tf_mobilenetv3_small_minimal_100']
Smoke test
timm_mobilenet = timm.create_model("mobilenetv3_small_050", pretrained=True)
Downloading model.safetensors: 0%| | 0.00/6.42M [00:00<?, ?B/s]
out = timm_mobilenet(dummy_input)
print(out.shape)
torch.Size([1, 1000])
Можно использовать большинство моделей из timm в качестве энкодеров.
При этом к названию модели, которое передается в конструктор класса SMP, нужно добавить префикс tu-:
smp_timm_model = smp.DeepLabV3("tu-mobilenetv3_small_050", in_channels=3, classes=80)
smp_timm_model.eval()
print("Created DeepLab with mobileNet encoder")
Created DeepLab with mobileNet encoder
Smoke test
mask = smp_timm_model(dummy_input)
print(mask.shape)
torch.Size([1, 80, 64, 64])

Детектирование — задача компьютерного зрения, в которой требуется определить местоположение конкретных объектов на изображении.
При этом вычислять точные границы объектов не требуется, достаточно определить только ограничивающие прямоугольники (bounding boxes), в которых находятся объекты.
В общем случае объекты могут принадлежать к различным классам, и объектов одного класса на изображении может быть несколько.
Начнём с простой ситуации.
Пусть нас интересуют объекты только одного класса, и мы знаем, что такой объект на изображении есть и он один.
К примеру, мы разрабатываем систему распознавания документов:
На вход модели подаётся изображение, и предсказать требуется область, в которой объект локализован. Область (bounding box) определяется набором координат вершин*. Собственно эти координаты и должна предсказать модель.
* Если наложить условие, что стороны многоугольника должны быть параллельны сторонам изображения, то можно ограничиться предсказанием 2-х координат.
Если задачу семантической сегментации получилось свести к классификации, то здесь будем использовать регрессию, поскольку предсказывать нужно не номер класса, а набор чисел.
В зависимости от требований эти числа могут нести разный смысл, например:
Но в любом случае задача остается регрессионной.
Зафиксируем seeds для воспроизводимости результата.
import torch
import random
import numpy as np
def fix_seeds():
torch.manual_seed(42)
random.seed(42)
np.random.seed(42)
fix_seeds()
Решается она так:
Берем сверточную сеть и меняем последний полносвязный слой таким образом, чтобы количество выходов совпадало с количеством координат, которые нам нужно предсказать.
Так для предсказания двух точек потребуется четыре выхода ( x1 , y1 , x2, y2 )
from torchvision.models import resnet18
from torch import nn
# load pretrained model
resnet_detector = resnet18(weights="ResNet18_Weights.DEFAULT")
# Change "head" to predict coordinates (x1,y1 x2,y2)
resnet_detector.fc = nn.Linear(resnet_detector.fc.in_features, 4) # x1,y1 x2,y2
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /root/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth 100%|██████████| 44.7M/44.7M [00:00<00:00, 197MB/s]
Для обучения такой модели придется заменить функцию потерь на регрессионную, например, MSE.
criterion = nn.MSELoss()
# This is a random example. Don't expect good results
input = torch.rand((1, 3, 224, 224))
target = torch.tensor([[0.1, 0.1, 0.5, 0.5]]) # x1,y1 x2,y2 or x,y w,h
print(f"Target: {target}")
output = resnet_detector(input)
loss = criterion(output, target)
print(f"Output: {output}")
print(f"Loss: {loss}")
Target: tensor([[0.1000, 0.1000, 0.5000, 0.5000]]) Output: tensor([[ 0.0432, 0.5333, -0.1924, 0.8475]], grad_fn=<AddmmBackward0>) Loss: 0.19780878722667694
Координаты обычно предсказываются в процентах от длины и ширины изображения. Таким образом, если bounding box целиком помещается на изображении, обе координаты будут находиться в интервале $[0 .. 1]$.

Recent Progress in Appearance-based Action Recognition (Humphreys et al., 2020)
По такому принципу работают многие модели для поиска различных ключевых точек. Например: на лице (facial landmarks) или теле человека.
Координаты прямоугольников мы предсказывать научились.
Теперь усложним задачу: объект остается один, но может принадлежать к различным классам.

То есть к задаче локализации добавляется классификация.
Задачу классификации мы умеем решать:

Остается объединить классификацию с регрессией:

Для этого нужно одновременно предсказывать:
Тогда выход последнего слоя будет иметь размер: $$N + 4$$
где N — количество классов (1000 для ImageNet),
а 4 числа — это координаты одного boundig box (x1,y1,x2,y2 или x,y,w,h).
Как описать функцию потерь для такой модели?
Можно суммировать loss для классификации и loss для регрессии.
$ \large L_{total} = L_{crossentropy}+L_{mse}$

Однако значения разных loss могут иметь разные порядки, поэтому приходится подбирать весовые коэффициенты для каждого слагаемого. В общем случае функция потерь будет иметь вид:
$$\large L_{total} = \sum _iw_iL_i,$$где $w_i$ — весовые коэффициенты каждой из функций потерь.
Они являются гиперпараметрами модели и требуют подбора.
Можно подбирать веса компонентов loss в процессе обучения. Для этого к модели добавляется дополнительный слой:
Как быть, если объектов несколько?
Для каждого объекта нужно вернуть координаты (x1, y1, x2, y2) и класс (0 .. N). Соответственно, количество выходов модели надо увеличивать.
Но нам неизвестно заранее, сколько объектов будет на изображении:
Cкользящее окно Одним из вариантов решения этой проблемы является применение классификатора ко всем возможным местоположениям объектов. Классификатор предсказывает, есть ли на выбранном фрагменте изображения один из интересующих нас объектов. Если нет, то фрагмент классифицируется как "фон".
Проблемой данного подхода является необходимость применять классификатор к огромному количеству различных фрагментов, что крайне дорого с точки зрения вычислений.
Чтобы сократить количество возможных окон для детекции, применяются разные способы:

Общая схема работы детектора:

Loss
Лосс складывается из лосс для классификации $L_{conf}$ и лосс для детекции $L_{loc}$
$$\large L_{det} = L_{conf} + \alpha L_{loc}$$При этом в $L_{loc}$ учитываются не все предсказанные bounding box, а только те, которые наилучшем образом пересекаются с GT (bbox из разметки). Фильтрация может проходить по порогу или при помощи алгоритма.
Теперь возникает другая проблема: в районе объекта алгоритм генерирует множество ограничивающих прямоугольников (bounding box), которые частично перекрывают друг друга.

Чтобы избавиться от них, используется алгоритм NMS (Non maxima suppression). Его задача — избавиться от bounding boxes, которые накладаваются на истинный:

Здесь $B$ — это массив всех bounding boxes, $C$ — массив предсказаний модели относительно наличия объекта в соответствующем bounding box.
Для оценки схожести обычно используется метрика IoU(same == IoU), а значение IoU ($\lambda_{nms}$), при котором bounding boxes считаются принадлежащими одному объекту, является гиперпараметром (часто 0.5).
В PyTorch алгоритм NMS доступен в модуле torchvision.ops
torchvision.ops.nms(boxes, scores, iou_threshold),
где:
boxes — массив bounding box,scores — предсказанная оценка,iou_threshold — порог IoU, NMS отбрасывает все перекрывающиеся поля с $IoU> iou\_threshold$В backbones, использующихся в детекторах на базе сверточных сетей, применяются подходы, развивающие идеи FPN.
а) Строится пирамида признаков, при этом некоторые карты признаков дополняются признакими с более ранних слоев (красный пунктир).
b) Затем на основе последнего слоя FPN строится еще одна (Bottom-up), и опять новые карты признаков дополняются признаками, полученными на первом уровне (зеленый пунктир).
Aug 2021 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Применять ViT напрямую для задач сегментации и детектирования не слишком эффективно, так как при больших размерах patch (16x16) не получится получить точные границы объектов.
А при уменьшении размеров patch будет требоваться все больше ресурсов, так как сложность self-attention $O(n^{2})$ пропорциональна квадрату количества элементов на входе.
Авторы решают проблему при помощи двух усовершенствований.
Self-attention применяется не ко всему изображению сразу, а к его большим фрагментам, окнами.
На первый взгляд это возвращает проблему сверток, про которую мы говорили:

Указываем сети, куда смотреть, и это мешает оценить взаимное влияние признаков, расположенных на разных углах карты.
Чтобы не допустить этой проблемы, на каждом следующем transformer-слое окно сдвигается.
Таким образом сеть может выучить влияние любого патча на любой. При этом не требуется увеличивать количество входов self-attention блока, и количество вычислений не растет.
Далее пространственные размеры карт признаков уменьшаются аналогично тому, как это происходит в сверточных сетях. Для сегментирования и детектирования используется принцип FPN: признаки с разных пространственных карт агрегируются для предсказания.
Patch merging здесь — это конкатенация эмбеддингов с последующей подачей на вход линейного слоя.
Фрагменты из 4-х эмбеддингов 2x2xC конкатенируются. Получаем один тензор 1x1x4C.
Затем подаем его на вход линейному слою, уменьшающему число каналов в 2 раза, получаем новый эмбеддинг размерностью 1x1x2C.
Таким образом, в отличие от традиционных трансформер-архитектур, размер embedding здесь меняется.
Такой подход позволил достичь SOTA результатов как в задаче классификации, так и в задачах детектирования и сегментации. Авторы статьи позиционируют Swin Transformer как backbone решения широкого круга задач CV.
Полезные источники:
YOLO6v3 YOLOv6 v3.0: A Full-Scale Reloading Chuyi Li et. al., Dec. 2023
Первая версия YOLO вышла в том же году, что и SSD. На тот момент детектор несколько проигрывал SSD в точности.
Однако благодаря усилиям Joseph Redmon проект поддерживался и развивался в течение нескольких лет.
3-я версия детектора оказалась настолько удачной, что даже в 2021 можно было прочесть: "YOLOv3, one of the most widely used detectors in industry".
Последующие версии создавались разными авторами. Полагаю, что правильно считать их разными форками YOLOv3, а не новыми версиями. Даже нумерация условна, например, статья про v7 датируется более ранней датой, чем v6.
В прикладных задачах я бы рекомендовал использовать YOLOv8, так как авторы выложили на свой сайт документацию, а точность при скорости порядка 100 fps у всех современных моделей почти одинакова.
В настоящий момент можно сказать, что YOLO — это оптимальный детектор по соотношению качества распознавания к скорости.
Подробнее можно посмотреть в блокноте.
Мы же запустим одну из последних моделей.
!pip install -q ultralytics
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 607.6/607.6 kB 9.8 MB/s eta 0:00:00
Инстанцируем модель по названию. Полный список предобученных моделей.
from ultralytics import YOLO
yolo8 = YOLO("yolov8n.pt")
Downloading https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt to 'yolov8n.pt'... 100%|██████████| 6.23M/6.23M [00:00<00:00, 84.2MB/s]
Детектируем объекты на изображении из COCO.
Из коробки работает с изображениями в разных форматах (даже url), автоматически меняет размер входного изображения, возвращает объект с результатами.
Подробнее ознакомиться можно в документации.
results = yolo8.predict(
"http://images.cocodataset.org/val2017/000000448263.jpg", # baseball
conf=0.25, # for NMS
iou=0.7,
) # for NMS
Downloading http://images.cocodataset.org/val2017/000000448263.jpg to '000000448263.jpg'... 100%|██████████| 36.9k/36.9k [00:00<00:00, 1.41MB/s] image 1/1 /content/000000448263.jpg: 480x640 3 persons, 1 baseball glove, 100.7ms Speed: 13.2ms preprocess, 100.7ms inference, 37.6ms postprocess per image at shape (1, 3, 480, 640)
В качестве результата возвращается список объектов, содержащих полную информацию о детектировании.
print(len(results)) # contains detections for one image
1
У него есть методы для получения списка координат предсказанных bounding box после NMS:
print(results[0].boxes.data) # x1,y2,x2,y2,conf,class_num
tensor([[ 87.5404, 7.1557, 231.3847, 235.4177, 0.8296, 0.0000],
[ 16.3276, 122.7995, 54.5783, 171.0505, 0.8294, 35.0000],
[ 18.5687, 11.8264, 78.2339, 228.6577, 0.7626, 0.0000],
[ 88.2422, 12.8856, 303.3497, 232.0106, 0.3741, 0.0000]], device='cuda:0')
Может даже создать картинку с нарисоваными bounding box.
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
pil_with_bbox = results[0].plot()
plt.imshow(pil_with_bbox) # BGR?
plt.show()

Похоже, объект results хранит картинку в BGR формате, переведем в RGB:
plt.figure(figsize=(10, 6))
plt.imshow(pil_with_bbox[..., ::-1]) # BGR->RGB
plt.show()


Mask R-CNN (Detectron) — концептуально простая, гибкая и общая схема сегментации объектов. Подход эффективно обнаруживает объекты на изображении и одновременно генерирует высококачественную маску сегментации для каждого объекта.
Метод, названный Mask R-CNN, расширяет Faster R-CNN, который мы обсуждали ранее, добавляя ветвь для предсказания маски объекта параллельно с существующей ветвью для распознавания bounding boxes.
Код доступен по ссылке
Загрузим картинку
!wget -q "http://images.cocodataset.org/val2017/000000448263.jpg"
from PIL import Image
from torchvision.transforms import ToTensor
I = Image.open("000000448263.jpg")
t = ToTensor()(I)
Загрузим модель
from IPython.display import clear_output
from torchvision.models.detection import (
maskrcnn_resnet50_fpn,
MaskRCNN_ResNet50_FPN_Weights,
)
mask_rcnn = maskrcnn_resnet50_fpn(weights=MaskRCNN_ResNet50_FPN_Weights.DEFAULT)
clear_output()
mask_rcnn.eval()
predictions = mask_rcnn(t.unsqueeze(0))
Для каждого изображения возвращается словарь
print(predictions[0].keys())
dict_keys(['boxes', 'labels', 'scores', 'masks'])
Каждый ключ содержит тензор, количество элементов в котором равно количеству детектированных объектов.
predictions[0]["masks"].shape
torch.Size([61, 1, 240, 320])
import matplotlib.pyplot as plt
import numpy as np
def show_masks(masks, classes=None):
fig, ax = plt.subplots(nrows=4, ncols=8, figsize=(20, 10))
i = 0
for row in range(4):
for col in range(8):
if classes is not None:
ax[row, col].set_title(int(classes[i]))
ax[row, col].imshow(masks[i])
ax[row, col].axis("off")
i += 1
if i >= len(masks):
plt.show()
return
plt.show()
show_masks(
predictions[0]["masks"].detach().squeeze(1), predictions[0]["labels"].detach()
)

Маски не бинарные, при необходимости можем их бинаризовать
mask = predictions[0]["masks"][2].detach().squeeze(0)
mask = mask > 0.5
plt.imshow(mask, cmap="gray")
plt.show()

У YOLOv8 заявлена поддержка сегментации.
!pip install -q ultralytics
from ultralytics import YOLO
yolo_seg = YOLO("yolov8m-seg.pt")
clear_output()
seg_results = yolo_seg(I)
0: 480x640 4 persons, 1 baseball glove, 79.5ms Speed: 1.7ms preprocess, 79.5ms inference, 2.4ms postprocess per image at shape (1, 3, 480, 640)
seg_results[0].masks.shape
torch.Size([5, 480, 640])
seg_results[0].masks.data.shape
torch.Size([5, 480, 640])
seg_results[0].boxes.cls
tensor([35., 0., 0., 0., 0.], device='cuda:0')
plt.figure(figsize=(10, 6))
pil_with_bbox = seg_results[0].plot(boxes=True, masks=True)
plt.imshow(pil_with_bbox[..., ::-1]) # BGR?
plt.show()

Vision Transformer for Open-World Localization
Simple Open-Vocabulary Object Detection with Vision Transformers
OWL-ViT — трансформер, осуществляющий детектирование по произвольному текстовому запросу.
Модели на вход подается изображение и набор текстов. Модель предсказывает bbox , и сравнивает их эмбеддинги с эмбеддингами текстов.
!pip install -q transformers
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.4/7.4 MB 50.2 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.8/7.8 MB 69.9 MB/s eta 0:00:00
Создаем модель и processor.
processor — это класс, отвечающий за предобработку и постобработку данных.
import torch
from transformers import OwlViTProcessor, OwlViTForObjectDetection
from IPython.display import clear_output
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
processor = OwlViTProcessor.from_pretrained(
"google/owlvit-base-patch32",
)
model = OwlViTForObjectDetection.from_pretrained(
"google/owlvit-base-patch32",
)
model.eval()
model.to(device)
clear_output()
print("loaded") # suppress huge output of model structure
loaded
Загрузим изображение
!wget -qN "http://images.cocodataset.org/val2017/000000448263.jpg"
from PIL import Image
img = Image.open("000000448263.jpg")
img

Создадим набор текстовых описаний для поиска
texts = ["cap", "botle", "text", "boy", "player"] #
batch = [img]
batch_size = len(batch)
with torch.inference_mode():
inputs = processor(
text=texts * batch_size, # copy the same text for all images
images=[img], # batch of images in PIL format
return_tensors="pt",
)
inputs = inputs.to(device)
outputs = model(**inputs) # return object of type OwlViTObjectDetectionOutput
print("bboxex", outputs["pred_boxes"].shape) # batch * total_boxes * 4 coords per box
print("logits", outputs["logits"].shape) # batch * total_boxes * text_count
bboxex torch.Size([1, 576, 4]) logits torch.Size([1, 576, 5])
Постобработка
При предобработке изображения могут масштабироваться (resize). Чтобы получить корректные bbox на выходе, в метод можно подать список исходных размеров изображений.
size = img.size[::-1] # WH -> HW
target_sizes = torch.tensor([size])
print(target_sizes)
tensor([[240, 320]])
results = processor.post_process_object_detection(
threshold=0.1, outputs=outputs, target_sizes=target_sizes.to(device) #
)
print(results)
[{'scores': tensor([0.1027, 0.1171], device='cuda:0'), 'labels': tensor([0, 3], device='cuda:0'), 'boxes': tensor([[ 94.7761, 6.7190, 147.3550, 33.3295],
[ 18.7188, 12.6309, 81.0806, 229.1255]], device='cuda:0')}]
from torchvision.utils import draw_bounding_boxes
from torchvision.ops import box_convert
import matplotlib.pyplot as plt
import numpy as np
def draw_bbox(img, bb, color, labels=None, xywh=True):
t_img = torch.tensor(img).permute(2, 0, 1) # to tensor CHW
bb = bb[:, :4].clone().detach() # take only coords
if xywh:
bb = box_convert(bb, "xywh", "xyxy") # convert from COCO format
img_with_bb = draw_bounding_boxes(t_img, bb, colors=color, width=2, labels=labels)
return img_with_bb.permute(1, 2, 0).numpy() # back to numpy HWC
def show_owl_results(results):
labels = []
for i, text_idx in enumerate(results[0]["labels"]):
labels.append(texts[text_idx] + f" {results[0]['scores'][i]:.2f}")
image_with_bb = draw_bbox(
np.array(img), results[0]["boxes"], "lime", labels=labels, xywh=False
)
plt.figure(figsize=(8, 6))
plt.imshow(image_with_bb)
plt.show()
show_owl_results(results)

Чтобы получить больше результатов, меняем порог:
coarse_results = processor.post_process_object_detection(
threshold=0.07, # change threshold
outputs=outputs,
target_sizes=target_sizes.to(device),
)
show_owl_results(coarse_results)

Модель возвращает набор масок, соответствующих входу. Классы объектов не используются.
В качестве входа могут подаваться:
Обучалась на огромном датасете, частично размеченном в unsupervise режиме
Установим пакет
!pip install -q git+https://github.com/facebookresearch/segment-anything.git
Preparing metadata (setup.py) ... done Building wheel for segment-anything (setup.py) ... done
Загружаем веса из репозитория Facebook Research
# ViT-H
!wget -qN https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
#!wget -qN https://edunet.kea.su/repo/EduNet-web_dependencies/weights/sam_vit_h_4b8939.pth
Создаем encoder
import torch
from segment_anything import sam_model_registry # SamPredictor, sam_model_registry
# model_type = 'vit_h'
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sam.to(device=device)
Sam(
(image_encoder): ImageEncoderViT(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 1280, kernel_size=(16, 16), stride=(16, 16))
)
(blocks): ModuleList(
(0-31): 32 x Block(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=1280, out_features=5120, bias=True)
(lin2): Linear(in_features=5120, out_features=1280, bias=True)
(act): GELU(approximate='none')
)
)
)
(neck): Sequential(
(0): Conv2d(1280, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): LayerNorm2d()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): LayerNorm2d()
)
)
(prompt_encoder): PromptEncoder(
(pe_layer): PositionEmbeddingRandom()
(point_embeddings): ModuleList(
(0-3): 4 x Embedding(1, 256)
)
(not_a_point_embed): Embedding(1, 256)
(mask_downscaling): Sequential(
(0): Conv2d(1, 4, kernel_size=(2, 2), stride=(2, 2))
(1): LayerNorm2d()
(2): GELU(approximate='none')
(3): Conv2d(4, 16, kernel_size=(2, 2), stride=(2, 2))
(4): LayerNorm2d()
(5): GELU(approximate='none')
(6): Conv2d(16, 256, kernel_size=(1, 1), stride=(1, 1))
)
(no_mask_embed): Embedding(1, 256)
)
(mask_decoder): MaskDecoder(
(transformer): TwoWayTransformer(
(layers): ModuleList(
(0-1): 2 x TwoWayAttentionBlock(
(self_attn): Attention(
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn_token_to_image): Attention(
(q_proj): Linear(in_features=256, out_features=128, bias=True)
(k_proj): Linear(in_features=256, out_features=128, bias=True)
(v_proj): Linear(in_features=256, out_features=128, bias=True)
(out_proj): Linear(in_features=128, out_features=256, bias=True)
)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=256, out_features=2048, bias=True)
(lin2): Linear(in_features=2048, out_features=256, bias=True)
(act): ReLU()
)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn_image_to_token): Attention(
(q_proj): Linear(in_features=256, out_features=128, bias=True)
(k_proj): Linear(in_features=256, out_features=128, bias=True)
(v_proj): Linear(in_features=256, out_features=128, bias=True)
(out_proj): Linear(in_features=128, out_features=256, bias=True)
)
)
)
(final_attn_token_to_image): Attention(
(q_proj): Linear(in_features=256, out_features=128, bias=True)
(k_proj): Linear(in_features=256, out_features=128, bias=True)
(v_proj): Linear(in_features=256, out_features=128, bias=True)
(out_proj): Linear(in_features=128, out_features=256, bias=True)
)
(norm_final_attn): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(iou_token): Embedding(1, 256)
(mask_tokens): Embedding(4, 256)
(output_upscaling): Sequential(
(0): ConvTranspose2d(256, 64, kernel_size=(2, 2), stride=(2, 2))
(1): LayerNorm2d()
(2): GELU(approximate='none')
(3): ConvTranspose2d(64, 32, kernel_size=(2, 2), stride=(2, 2))
(4): GELU(approximate='none')
)
(output_hypernetworks_mlps): ModuleList(
(0-3): 4 x MLP(
(layers): ModuleList(
(0-1): 2 x Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=32, bias=True)
)
)
)
(iou_prediction_head): MLP(
(layers): ModuleList(
(0-1): 2 x Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=4, bias=True)
)
)
)
)
Загрузим изображение
!wget -q https://edunet.kea.su/repo/EduNet-content/L12/out/semantic_segmentation_1.png -O cat.png
!wget -q "http://images.cocodataset.org/val2017/000000448263.jpg"
from PIL import Image
import numpy as np
img = Image.open("000000448263.jpg")
np_im = np.array(img) # HWC format
img
Создадим эмбеддинг (на CPU выполняется долго) и предскажем все маски (подробнее об автоматической генерации масок).
%%time
from segment_anything import SamAutomaticMaskGenerator
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(np_im)
CPU times: user 6.23 s, sys: 31.3 ms, total: 6.26 s Wall time: 6.71 s
На выходе получаем список
masks[0]
{'segmentation': array([[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]),
'area': 5943,
'bbox': [104, 40, 108, 82],
'predicted_iou': 1.0488086938858032,
'point_coords': [[175.0, 86.25]],
'stability_score': 0.9864819645881653,
'crop_box': [0, 0, 320, 240]}
masks[0]["segmentation"].shape
(240, 320)
# https://github.com/facebookresearch/segment-anything/blob/main/notebooks/automatic_mask_generator_example.ipynb
import matplotlib.pyplot as plt
def show_anns(anns):
if len(anns) == 0:
return
sorted_anns = sorted(anns, key=(lambda x: x["area"]), reverse=True)
ax = plt.gca()
ax.set_autoscale_on(False)
img = np.ones(
(
sorted_anns[0]["segmentation"].shape[0],
sorted_anns[0]["segmentation"].shape[1],
4,
)
)
img[:, :, 3] = 0
for ann in sorted_anns:
m = ann["segmentation"]
color_mask = np.concatenate([np.random.random(3), [0.35]])
img[m] = color_mask
ax.imshow(img)
plt.figure(figsize=(10, 8))
plt.imshow(img)
show_anns(masks)
plt.axis("off")
plt.show()

Предсказываем по точкам. Сначала создаем эмбеддинг. Он хранится внутри модели.
%%time
from segment_anything import SamPredictor
predictor = SamPredictor(sam)
predictor.set_image(np_im) # create embedding
CPU times: user 1.98 s, sys: 16.2 ms, total: 1.99 s Wall time: 2.06 s
Теперь получаем предсказания, указав точки, которые относятся к объекту и фону:
masks, scores, logits = predictor.predict(
point_coords=np.array([[200, 200], [1, 1]]), # point coords
point_labels=np.array([1, 0]), # 1 - object(foreground), 0 - background
# box
# mask_input
multimask_output=True, # return 1 or 3 masks because of the ambiguous input
)
print("Masks count", len(masks))
print("Scores", scores)
Masks count 3 Scores [ 0.85097 0.95786 0.98574]
print(masks[0].shape)
(240, 320)
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
plt.imshow(img)
show_mask(masks[2], plt.gca())
plt.axis("off")
plt.show()

AP (Average Precision — средняя точность) — это площадь под сглаженной PR-кривой.
m (mean) — усредненная для разных порогов IoU.
Разберемся, что это значит.
Precision измеряет, насколько точны предсказания сети (т.е. процент правильных предсказаний)
Recall измеряет, насколько хорошо сеть находит все положительные срабатывания (positives). Например, мы можем найти 80% возможных положительных срабатываний в наших K лучших предсказаниях.
Вот их математические определения:
$\displaystyle\mathrm{Precision} = \frac{TP}{TP+FP}$
$\displaystyle\mathrm{Recall} = \frac{TP}{TP+FN}$
где $TP$ — True Positive, $TN$ — True Negative, $FP$ — False Positive, $FN$ — False Negative.
Например, мы пытаемся детектировать яблоки на фотографиях. Предположим, мы обработали 20 фотографий (на 10 фотографиях по одному яблоку и на 10 фотографиях яблок нет) и обнаружили что:
Посчитаем precision и recall:
def precision(TP, FP):
return TP / (TP + FP)
def recall(TP, FN):
return TP / (TP + FN)
pres = precision(TP=7, FP=4)
rec = recall(TP=7, FN=3)
print("Precision = %.2f" % pres)
print("Recall = %.2f" % rec)
Precision = 0.64 Recall = 0.70
Зная Precision и Recall для разных порогов, можно построить так называемую PR-кривую.
При помощи таких кривых часто оценивают модели в задачах классификации, когда данные не сбалансированы.
Для получения значений Precision и Recall требуются:
import numpy as np
y_true = np.array([1, 1, 0]) # Labels
y_pred = np.array([0.8, 0.1, 0.2]) # Predictions
Этого достаточно для того, чтобы построить PR-кривую для предсказаний одного класса.
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
def pr_curve(y_true, y_pred):
plt.figure(figsize=(6, 4))
precision, recall, thresholds = precision_recall_curve(y_true, y_pred)
plt.plot(recall, precision, marker="o")
for i, t in enumerate(thresholds):
plt.annotate(str(t), (recall[i], precision[i]))
plt.ylim([0, 1.1])
plt.xlabel("recall")
plt.ylabel("precision")
plt.title("PR curve")
plt.show()
pr_curve(y_true, y_pred)

При детектировании у нас нет меток класса для предсказанных bounding box.
Есть предсказанные детектором bbox в виде:
import pandas as pd
detections = np.array(
[
[290, 50, 170, 160, 0.7, 53], # x, y, w, h, confidence, class_num
[10, 200, 190, 180, 0.8, 53],
[310, 250, 120, 130, 0.75, 53],
]
)
pd.DataFrame(
data=detections, columns=["x", "y", "width", "height", "confidence", "class_num"]
)
| x | y | width | height | confidence | class_num | |
|---|---|---|---|---|---|---|
| 0 | 290.0 | 50.0 | 170.0 | 160.0 | 0.70 | 53.0 |
| 1 | 10.0 | 200.0 | 190.0 | 180.0 | 0.80 | 53.0 |
| 2 | 310.0 | 250.0 | 120.0 | 130.0 | 0.75 | 53.0 |
И есть Ground True bounding box из разметки:
!wget -qN "http://images.cocodataset.org/annotations/annotations_trainval2017.zip"
# !wget -qN "https://edunet.kea.su/repo/EduNet-web_dependencies/datasets/annotations_trainval2017.zip"
!unzip -qn annotations_trainval2017.zip
from pycocotools.coco import COCO
from IPython.display import clear_output
coco = COCO("annotations/instances_val2017.json")
clear_output()
apples_img_id = 60855 # if of some image with apples
apple_cat_id = 53 # apple
ann_id = coco.getAnnIds(imgIds=[apples_img_id])
anns = coco.loadAnns(ann_id)
gt_bbox = []
for ann in anns:
if ann["category_id"] == apple_cat_id:
gt_bbox.append(ann["bbox"] + [ann["category_id"]])
pd.DataFrame(data=gt_bbox, columns=["x", "y", "width", "height", "class_num"])
| x | y | width | height | class_num | |
|---|---|---|---|---|---|
| 0 | 269.44 | 61.96 | 154.91 | 161.48 | 53 |
| 1 | 24.26 | 208.04 | 177.04 | 176.13 | 53 |
Идея состоит в том, чтобы посчитать максимальный IoU между этими bounding box и использовать его вместо метки класса (True/False).
import torch
import skimage
from torchvision.utils import draw_bounding_boxes
from torchvision.ops import box_convert
def draw_bbox(img, bb_xywh, color):
t_img = torch.tensor(img).permute(2, 0, 1) # to tensor CHW
xywh = torch.tensor(bb_xywh)[:, :4] # take only coords
bb = box_convert(xywh, "xywh", "xyxy") # convert from COCO format
img_with_bb = draw_bounding_boxes(t_img, bb, colors=color, width=4)
return img_with_bb.permute(1, 2, 0).numpy() # back to numpy HWC
img_info = coco.loadImgs(apples_img_id)
img = skimage.io.imread(img_info[0]["coco_url"])
img = draw_bbox(img, detections, "blue")
img = draw_bbox(img, gt_bbox, "lime")
plt.figure(figsize=(8, 6))
plt.imshow(img)
plt.show()

Чтобы получить максимальное значение IoU для каждого предсказанного bbox, воспользуемся функцией torchvision.ops.box_iou.
Перед этим преобразуем формат координат к (x1,y1,x2,y2):
from torchvision.ops import box_convert
gt = box_convert(torch.tensor(gt_bbox)[:, :4], "xywh", "xyxy")
pred = box_convert(torch.tensor(detections)[:, :4], "xywh", "xyxy")
И получим IoU для всех возможных пар bbox:
from torchvision.ops import box_iou
pairwise_iou = box_iou(gt, pred)
print(pairwise_iou)
tensor([[0.6153, 0.0000, 0.0000],
[0.0000, 0.8595, 0.0000]], dtype=torch.float64)
Нас интересует только максимальный:
iou, _ = pairwise_iou.max(dim=0)
print(iou)
tensor([0.6153, 0.8595, 0.0000], dtype=torch.float64)
Запишем эти значения в таблицу.
import pandas as pd
predictions = torch.tensor(detections)[:, 4]
predictions = torch.vstack((predictions, iou)).T
pd.DataFrame(data=predictions, columns=["confidence", "iou"])
| confidence | iou | |
|---|---|---|
| 0 | 0.70 | 0.615274 |
| 1 | 0.80 | 0.859463 |
| 2 | 0.75 | 0.000000 |
Теперь будем использовать IoU как GT метку класса: если он больше некоторого порога, то предсказание верное.
В нашем случае будем считать, что если IoU≥0.5, то предсказание правильное.
gt = iou > 0.5
predictions = torch.vstack((predictions[:, 0], gt)).T
detection_results = pd.DataFrame(data=predictions, columns=["confidence", "gt"])
detection_results.head()
| confidence | gt | |
|---|---|---|
| 0 | 0.70 | 1.0 |
| 1 | 0.80 | 1.0 |
| 2 | 0.75 | 0.0 |
Теперь у нас есть все необходимое для того, чтобы построить PR-кривую:
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(6, 4))
precision, recall, thresholds = precision_recall_curve(gt, predictions[:, 0])
plt.plot(recall, precision, marker="o")
plt.ylim([0, 1.1])
plt.show()

AP это площадь под PR кривой.
$\large \displaystyle AP = \int_0^1p(r)dr$
Имея значения Precision и Recall, можно посчитать AP:
from sklearn.metrics import average_precision_score
ap = average_precision_score(gt, predictions[:, 0])
print("AP", ap)
AP 0.8333333333333333
Сравним это значение с площадью под кривой:
from sklearn import metrics
auc = metrics.auc(recall, precision)
print("AUC", auc)
AUC 0.7916666666666666
Как видим, они не совпали. Дело в том, что при подсчете AP кривую сглаживают:
import numpy as np
def smooth_precision(precision):
smooth_prec = []
for i in range(1, len(precision) + 1):
max = precision[:i].max()
smooth_prec.append(max)
return smooth_prec
detection_results = detection_results.sort_values("confidence", ascending=False)
precision, recall, thresholds = precision_recall_curve(
detection_results["gt"], detection_results["confidence"]
)
smoothed_precision = smooth_precision(precision)
plt.figure(figsize=(6, 4))
plt.plot(recall, precision, marker="o")
plt.plot(recall, smoothed_precision, marker="o")
plt.ylim([0, 1.1])
plt.show()

smooth_auc = metrics.auc(recall, smoothed_precision)
print("smooth AUC ", smooth_auc)
smooth AUC 0.8333333333333333
Мы посчитали AP для одного класса, но в датасете их много. Логично усреднить значения AP для разных классов. В некоторых бенчмарках после такого усреднения к названию метрики добавляют приставку m(mean)
AP is averaged over all categories. Traditionally, this is called “mean average precision” (mAP). We make no distinction between AP and mAP
Мы выбрали для IoU порог 0.5.
Но можно посчитать AP для разных порогов, и затем тоже усреднить. В этом случае в названии метрики указывается минимальный и максимальный пороги. Например AP@[.5:.95] соответствует среднему AP для IoU от 0.5 до 0.95 с шагом 0.05.
!pip install -q torchmetrics
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 729.2/729.2 kB 10.1 MB/s eta 0:00:00
from torchmetrics.detection.mean_ap import MeanAveragePrecision
t_gt_bbox = torch.tensor(gt_bbox)
t_detections = torch.tensor(detections)
map_obj = MeanAveragePrecision("xywh", iou_thresholds=[0.5, 0.55, 0.6, 0.65])
results = map_obj(
preds=[
{
"boxes": t_detections[:, :4], # xywh
"scores": t_detections[:, 4], # confidence
"labels": t_detections[:, 5].int(), # class num
}
],
target=[
{"boxes": t_gt_bbox[:, :4], "labels": t_gt_bbox[:, 4].int()} # xywh # class num
],
)
print("mAP@[0.5:0.65] = ", results["map"].item())
mAP@[0.5:0.65] = 0.7524752616882324
Список использованной литературы
Детектирование
Recent Progress in Appearance-based Action Recognition (Humphreys et al., 2020)
SSD: Single Shot MultiBox Detector (Liu et al., 2015)
Focal Loss for Dense Object Detection (Lin et al., 2017)
Статья про Focal Loss от Facebook AI Research
Feature Pyramid Networks for Object Detection (Sergelius et al., 2016)
What is Feature Pyramid Network (FPN)?
You Only Look Once: Unified, Real-Time Object Detection (Redmon et. al., 2015)
YOLO9000: Better, Faster, Stronger (Redmon et. al., 2015)
YOLOv3: An Incremental Improvement (Redmon et. al., 2018)
YOLOv4: Optimal Speed and Accuracy of Object Detection (Bochkovskiy et al., 2020)





















